
- Перевод в некоторое внутреннее состояние.
- Методы синтаксического анализа бывают двух видов
- Вступление
- Приступим
- Контекстно-свободная грамматика
- Вывод
- Ссылки
- Способы описания грамматики
- LL -грамматики
- . По первым двум символам определить раскрытие можно. Также грамматика не LL если разные правила начинаются с одинаковых символов: Грамматика не LL , если в правилах имеем т.н. левую рекурсию: Преимущество LL -грамматик — для них сравнительно легко написать синтаксический анализатор методом рекурсивного спуска. Метод рекурсивного спуска Метод рекурсивного спуска — способ написания синтаксических анализаторов для LL -грамматик на алгоритмических языках программирования. Для каждого нетерминала грамматики записывается процедура, тело которой выводится из правил для данного нетерминала. Построенный синтаксический анализатор выдаёт сообщение о принадлежности входной строки к заданному языку. Написание синтаксического анализатора состоит из этапов: Вспомогательная структура данных — поток (stream). У потока есть возможность получить текущий символ (peek stream) без продвижения вперёд, получить символ и удалить из потока (next stream). Пример реализации потока: stream.scm. Все функции, соответствующие нетерминалам, принимают поток, первым символом которого должен быть первый символ раскрытия нетерминала, и функцию ошибки, которая вызывается, чтобы прервать разбор. При успешном разборе функция поглощает из входного потока все токены, соответствующие раскрытию данного нетерминала. Пусть w — некоторая строка символов грамматики (терминальных и нетерминальных). Обозначим FIRST(w) — множество терминальных символов, с которого может начинаться строка токенов, полученная из w раскрытием всех нетерминалов. Если строка может быть пустой, то ε также входит в FIRST(w). Построим множество FIRST(w) для правил грамматики арифметических выражений: Пусть правило имеет вид где функция (expect stream term error) имеет вид Разбор начинается с создания потока и сохранения точки возврата. После успешного разбора аксиомы в потоке должен располагаться символ конца потока. ;; Создаём поток ;; Создаём точку возврата ;; разбираем аксиому ;; в конце должен остаться признак конца потока Лексический анализ Грамматика для стадии лексического анализа описывается, как правило, без рекурсии (имеется ввиду, без нехвостовой рекурсии), т.к. лексическая структура языка не требует вложенных конструкций. Назначение лексического анализа: разбивает исходный текст на последовательность токенов, которые синтаксический анализ будет группировать в дерево. Либо, если исходный текст не соответствует грамматике — выдача сообщения (сообщений) об ошибке. Входные данные: строка символов (или список символов), выходные: последовательность токенов. Можно сказать, что дерево разбора для грамматики лексем вырожденное — рекурсия есть только по правой ветке (cdr). Мы будем его реализовывать методом рекурсивного спуска. Его грамматика как правило описывается уже с использованием рекурсии, дерево разбора рекурсивное. Назначение: построение синтаксического дерева из списка токенов. Либо выдача сообщения об ошибке. Входные данные: список токенов, выходные: дерево разбора (или синтаксическое дерево). Дерево разбора — дерево, построенное для данной грамматики и данной входной строки, такое что, корнем является аксиома грамматики, листьями — символы входной строки, внутренними узлами являются нетерминальные символы грамматики, потомки внутренних узлов упорядочены и соответствуют правилам грамматики, при перечислении листьев слева-направо получаем исходную строку. Абстрактное синтаксическое дерево отражает уже логическую, смысловую структуру программы. В отличие от дерева разбора, оно не содержит скобок для указания приоритета, символов-разделителей и т.д. Пример лексического и синтаксического анализа В качестве примера рассмотрим подмножество Scheme с переменными, лямбдами, определениями и вызовами функций. Первая фаза написание парсера — построение LL -грамматики. Проблема этой грамматики, что она не LL . Грамматика, приведённая к LL : Вторая фаза — механистическое построение парсера по грамматике. Построим лексический анализатор: Третья фаза — реализация семантических действий. В случае лексического анализа — это построение цепочки токенов. Синтаксический разбор предложения русского языка В данной статье описывается процесс синтаксического анализа предложения русского языка с использованием контекстно-свободной грамматики и алгоритма LR-анализа. Обработка естественного языка — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков. В общем, процесс анализа предложения естественного языка выглядит следующим образом: разбиение предложения на синтаксические единицы — слова и словосочетания; определение грамматических параметров каждой единицы; определение синтаксической связи между единицами. На выходе — абстрактное дерево разбора. Разбиение предложения на синтаксические единицы Предложение естественного языка состоит из словоформ и устойчивых словосочетаний. Ряд словоформ данного слова называется парадигмой. Словосочетания — составные союзы, предикативы или устойчивые выражения — не изменяются и не могут быть разложены на меньшие единицы без потери смысла. Далее под словом будем понимать любую синтаксическую единицу — словоформу или словосочетание. Каждое слово в предложении определяется тройкой: Таким образом, разбиение предложения «Ясно дело, он не придет на встречу» будет иметь следующий вид: Определение грамматических параметров (граммем) Граммемой называется элемент грамматической категории; различные граммемы одной категории исключают друг друга и не могут быть выражены вместе. Для каждой словоформы определяем набор из семи граммем: В качестве источника будем использовать словарь OpenCorpora и интерфейс к нему — pymorphy2. Для поиска правила в грамматике по данному набору граммем будем представлять их в общем виде: Определение синтаксической связи между словами Для определения синтаксической связи между словами будем использовать контекстно-свободную грамматику и LR-анализ. Грамматика и LR-анализ Формальная грамматика — способ описания языка в виде так называемых продукций. Например: означает, что правило ‘a’ порождает ‘ab’ ИЛИ ‘ac’. Нетерминалами называются объекты, обозначающие какую-либо сущность языка (предложение, формула и т.д.). Терминалы — объекты непосредственно присутствующие в языке, соответствующего грамматике, и имеющий конкретное, неизменяемое значение (буквы, слова, формулы и др.). Контекстно-свободные грамматики, это такие грамматики, у которых левые части всех продукций являются одиночными нетерминалами. Для описания русского языка будем использовать теорию грамматики составляющих (phrase structure grammar), которая утверждает что всякая сложная грамматическая единица складывается из двух более простых и не пересекающихся единиц, называемых её непосредственными составляющими. Выделяют следующие составляющие: Именная группа (NP) То есть номинативная именная группа — это существительное в номинативном падеже ИЛИ прилагательное в номинативном падеже + номинативная именная группа ИЛИ другое. Глагольная группа (VP) Другими словами, транзитивная глагольная группа — это транзитивный глагол + аблативная именная группа ИЛИ краткое прилагательное + транзитивная глагольная группа ИЛИ другое.
- Метод рекурсивного спуска
- Вспомогательная структура данных — поток (stream).
- Лексический анализ
- Пример лексического и синтаксического анализа
- Синтаксический разбор предложения русского языка
- определение грамматических параметров каждой единицы;
- Разбиение предложения на синтаксические единицы
- Определение грамматических параметров (граммем)
- Определение синтаксической связи между словами
- Грамматика и LR-анализ
- Глагольная группа (VP)
- Проблемы
- Заключение
Перевод в некоторое внутреннее состояние.
Другой способ разбора S-маркер (Как с Агатой).
Методы синтаксического анализа бывают двух видов
Время на прочтение
Здравствуйте. Это статья об синтаксическом анализе предложений, их представлении. Для разбора предложений будет использоваться пакет NLTK и язык программирования Python (версии 2.7).
Вступление
В моей предыдущей статье мы рассматривали морфологические анализаторы и их использование. Настоятельно рекомендую прочитать её, чтобы лучше понять данную статью. Также там рассматривается установка и настройка пакета NLTK.
Приступим
Что такое синтаксический анализ? Синтаксический анализ – это процесс, который определяет, принадлежит ли некоторая последовательность лексем языку, порождаемому грамматикой. Обычно представляется в виде дерева для удобства понимания.
Рассмотрим некоторые грамматические особенности английского языка:
Контекстно-свободная грамматика
Синтаксический анализатор – это программа, которая обрабатывает входное предложение согласно правилам грамматики и строит одну или несколько синтаксических структур, которые отвечают этой грамматике.
Мы рассмотрим два простых алгоритма синтаксического анализа: алгоритм рекурсивного спуска (стратегия «сверху-вниз») и алгоритм перемещения-сворачивания (стратегия «снизу-вверх»).
Рассмотрим каждый подробнее:
Вывод
В данной статье мы рассмотрели синтаксический анализ предложений с помощью пакета NLTK. Также рассмотрели два алгоритма для синтаксического анализа: алгоритм перемещения-сворачивания и алгоритм рекурсивного спуска.
Спасибо за внимание.
Ссылки
Формальная грамматика — это способ описания синтаксиса языков программирования.
Мы будем рассматривать не все языки программирования, а только контекстно-свободные
и регулярные (автоматные).
Формальная грамматика — набор правил, позволяющих породить строку, принадлежащую
данному языку программирования. Формальная грамматика состоит из
Терминальные символы — символы алфавита, из которых строятся строки данного
языка программирования. Для стадии лексического анализа (грамматики токенов)
терминальные символы — литеры (characters) текста. Для стадии синтаксического
анализа терминальные символы — токены.
Нетерминальные символы — символы, которые раскрываются согласно правилам
грамматики.
В синтаксическом дереве (дереве разбора) терминальные символы соответствуют листьям, нетерминальные —
внутренним узлам.
Аксиома грамматики — нетерминальный символ, выбранный в качестве стартового.
Правила грамматики описывают, как в строке символов (терминальных и нетерминальных)
раскрываются нетерминальные символы.
Порождение строки, принадлжежащей языку, начинается с аксиомы, заканчивается
цепочкой терминальных символов.
Контекстно-свободные языки — языки, правила грамматик которых описываются
выражением вида
где X — нетерминальный символ, a, b, c — некоторые символы грамматики.
При описании грамматик для наглядности пустую строку обозначают знаком ε.
Грамматика арифметических выражений:
Пример вывода в этой грамматике:
Дерево вывода для этого примера:
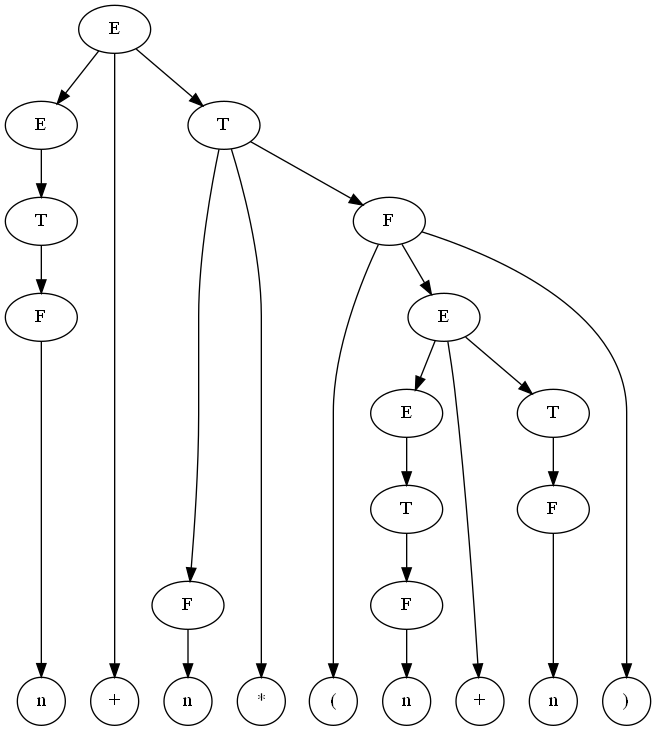
Задача синтаксического анализа — имеем цепочку нетерминальных символов,
нужно построить дерево разбора, соответствующее этой цепочке или показать,
что такового не существует — цепочка не принадлежит данному языку.
Т.е. для некоторой грамматики и некоторой строки определить, принадлежит ли
данная строка языку, описываемому данной грамматикой.
Способы описания грамматики
Форма Бекуса-Наура (БНФ) — способ описания грамматики, где правила имеют вид
Впервые она была использована при описании Алгола-60.
При описании многих языков программирования (в учебниках, стандартах) используется
тот или иной вариант БНФ. Нотация может быть расширена такими обзначениями как
* или + после нетерминала, означающие повторение ноль или более раз (*)
или один или более раз (+) данного нетерминала.
Синтаксические диаграммы — это графический способ описания грамматики языка.
Впервые был использован Никлаусом Виртом при описании синтаксиса языка Паскаль
в 1973 году.
Используются редко, т.к. грамматика в виде БНФ более компактная и её проще
записывать (диаграммы нужно рисовать).
LL
-грамматики
LL(k)-грамматики — грамматики, в которых мы можем определить правило для
раскрытия нетерминала по первым k символам входной цепочки.
Дано: цепочка терминальных символов и нетерминальный символ. Требуется определить,
по какому правилу нужно раскрыть нетерминальный символ, чтобы получить префикс
этой цепочки. Для LL(k)-грамматик это можно сделать, зная первые k символов.
Чаще всего рассматриваются LL
-грамматики, где раскрытие определяется по первому
символу.
Пример: LL
-грамматика для тех же арифметических выражений:
Однако, это грамматика LL
. По первым двум символам определить раскрытие можно.
Также грамматика не LL
если разные правила начинаются с одинаковых символов:
Грамматика не LL
, если в правилах имеем т.н. левую рекурсию:
Преимущество LL
-грамматик — для них сравнительно легко написать синтаксический
анализатор методом рекурсивного спуска.
Метод рекурсивного спуска
Метод рекурсивного спуска — способ написания синтаксических анализаторов
для LL
-грамматик на алгоритмических языках программирования. Для каждого
нетерминала грамматики записывается процедура, тело которой выводится из правил
для данного нетерминала.
Построенный синтаксический анализатор выдаёт сообщение о принадлежности
входной строки к заданному языку.
Написание синтаксического анализатора состоит из этапов:
Вспомогательная структура данных — поток (stream).
У потока есть возможность получить текущий символ (peek stream) без продвижения
вперёд, получить символ и удалить из потока (next stream).
Пример реализации потока: stream.scm.
Все функции, соответствующие нетерминалам, принимают поток, первым символом которого
должен быть первый символ раскрытия нетерминала, и функцию ошибки, которая вызывается,
чтобы прервать разбор. При успешном разборе функция поглощает из входного потока
все токены, соответствующие раскрытию данного нетерминала.
Пусть w — некоторая строка символов грамматики (терминальных и нетерминальных).
Обозначим FIRST(w) — множество терминальных символов, с которого может начинаться
строка токенов, полученная из w раскрытием всех нетерминалов. Если строка может
быть пустой, то ε также входит в FIRST(w).
Построим множество FIRST(w) для правил грамматики арифметических выражений:
Пусть правило имеет вид
где функция (expect stream term error) имеет вид
Разбор начинается с создания потока и сохранения точки возврата.
После успешного разбора аксиомы в потоке должен располагаться символ
конца потока.
;; Создаём поток
;; Создаём точку возврата
;; разбираем аксиому
;; в конце должен остаться признак конца потока
Лексический анализ
Грамматика для стадии лексического анализа описывается, как правило, без
рекурсии (имеется ввиду, без нехвостовой рекурсии), т.к. лексическая структура
языка не требует вложенных конструкций.
Назначение лексического анализа: разбивает исходный текст на последовательность
токенов, которые синтаксический анализ будет группировать в дерево. Либо,
если исходный текст не соответствует грамматике — выдача сообщения (сообщений)
об ошибке.
Входные данные: строка символов (или список символов), выходные:
последовательность токенов. Можно сказать, что дерево разбора для грамматики
лексем вырожденное — рекурсия есть только по правой ветке (cdr).
Мы будем его реализовывать методом рекурсивного спуска.
Его грамматика как правило описывается уже с использованием рекурсии, дерево
разбора рекурсивное.
Назначение: построение синтаксического дерева из списка токенов. Либо выдача
сообщения об ошибке.
Входные данные: список токенов, выходные: дерево разбора (или синтаксическое
дерево).
Дерево разбора — дерево, построенное для данной грамматики и данной входной
строки, такое что, корнем является аксиома грамматики, листьями — символы
входной строки, внутренними узлами являются нетерминальные символы грамматики,
потомки внутренних узлов упорядочены и соответствуют правилам грамматики, при
перечислении листьев слева-направо получаем исходную строку.
Абстрактное синтаксическое дерево отражает уже логическую, смысловую
структуру программы. В отличие от дерева разбора, оно не содержит скобок для
указания приоритета, символов-разделителей и т.д.
Пример лексического и синтаксического анализа
В качестве примера рассмотрим подмножество Scheme с переменными, лямбдами, определениями
и вызовами функций.
Первая фаза написание парсера — построение LL
-грамматики.
Проблема этой грамматики, что она не LL
.
Грамматика, приведённая к LL
:
Вторая фаза — механистическое построение парсера по грамматике.
Построим лексический анализатор:
Третья фаза — реализация семантических действий. В случае лексического
анализа — это построение цепочки токенов.
Синтаксический разбор предложения русского языка
В данной статье описывается процесс синтаксического анализа предложения русского языка с использованием контекстно-свободной грамматики и алгоритма LR-анализа.
Обработка естественного языка — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков.
В общем, процесс анализа предложения естественного языка выглядит следующим образом:
разбиение предложения на синтаксические единицы — слова и словосочетания;
определение грамматических параметров каждой единицы;
определение синтаксической связи между единицами. На выходе — абстрактное дерево разбора.
Разбиение предложения на синтаксические единицы
Предложение естественного языка состоит из словоформ и устойчивых словосочетаний. Ряд словоформ данного слова называется парадигмой.
Словосочетания — составные союзы, предикативы или устойчивые выражения — не изменяются и не могут быть разложены на меньшие единицы без потери смысла. Далее под словом будем понимать любую синтаксическую единицу — словоформу или словосочетание.
Каждое слово в предложении определяется тройкой:
Таким образом, разбиение предложения «Ясно дело, он не придет на встречу» будет иметь следующий вид:
Определение грамматических параметров (граммем)
Граммемой называется элемент грамматической категории; различные граммемы одной категории исключают друг друга и не могут быть выражены вместе. Для каждой словоформы определяем набор из семи граммем:
В качестве источника будем использовать словарь OpenCorpora и интерфейс к нему — pymorphy2. Для поиска правила в грамматике по данному набору граммем будем представлять их в общем виде:
Определение синтаксической связи между словами
Для определения синтаксической связи между словами будем использовать контекстно-свободную грамматику и LR-анализ.
Грамматика и LR-анализ
Формальная грамматика — способ описания языка в виде так называемых продукций. Например:
означает, что правило ‘a’ порождает ‘ab’ ИЛИ ‘ac’.
Нетерминалами называются объекты, обозначающие какую-либо сущность языка (предложение, формула и т.д.). Терминалы — объекты непосредственно присутствующие в языке, соответствующего грамматике, и имеющий конкретное, неизменяемое значение (буквы, слова, формулы и др.). Контекстно-свободные грамматики, это такие грамматики, у которых левые части всех продукций являются одиночными нетерминалами.
Для описания русского языка будем использовать теорию грамматики составляющих (phrase structure grammar), которая утверждает что всякая сложная грамматическая единица складывается из двух более простых и не пересекающихся единиц, называемых её непосредственными составляющими. Выделяют следующие составляющие:
Именная группа (NP)
То есть номинативная именная группа — это существительное в номинативном падеже ИЛИ прилагательное в номинативном падеже + номинативная именная группа ИЛИ другое.
Глагольная группа (VP)
Другими словами, транзитивная глагольная группа — это транзитивный глагол + аблативная именная группа ИЛИ краткое прилагательное + транзитивная глагольная группа ИЛИ другое.
Предложная группа (PP)
Предложная группа — это предлог + именная дативная группа ИЛИ другое.
Полное предложение (S)
Полное предложение существует тогда и только тогда, когда именная и глагольная группы согласованы в числе, лице и роде.
Неполным предложением называется такое предложение, где опущена именная часть. Как правило, в таких предложениях глагольная группа выражена безличным глаголом. Например, «Мне хочется гулять», «Светает». Эллептическим предложением называется предложение, где опущена глагольная часть, она заменяется знаком тире. Например, «За спиной – лес. Справа и слева – болота».
Для того, чтобы определить принадлежность данного предложения к языку грамматики будем использовать алгоритм LR-анализа. Данный алгоритм предполагает построение дерева разбора снизу вверх (от листьев к корню). Ключевым элементов алгоритма является метод «переноса-свертки» (англ. shift-reduce):
читаем символы входной строки до тех пор, пока найдется цепочка, совпадающая с правой частью какого-нибудь из правил, найденную цепочку положить в стэк (перенос);
заменим найденную цепочку правилом из грамматики (свертка).
Если все цепочки строки были перенесены, то данное предложение принадлежит языку грамматики, и по крайней мере одно дерево разбора существует.
Для представления синтаксической связи в предложении используется бинарное дерево, где листья — это слова (терминалы) с набором граммем, а узлы — правила (претерминалы). Корнем является предложение (нетерминал).
Узел дерева определяется следующим образом:
class Node:
def __init__(self, word=None, tag=None, grammemes=None, leaf=False):
self.word = word; # строка слова
self.tag = tag; # здесь тэг — претерминал,
который соотвествует промежуточному правилу грамматики
self.grammemes = grammemes; # набор граммем
self.leaf = leaf;
self.l = None;
self.r = None;
self.p = None;
Построение дерева начинается с листьев, которым присваивается строка слова или словосочетания, а также набор ее граммем.
Важно заметить, что свертка происходит в установленном порядке:
def reduce(self):
self.reduce_ADJ() # прилагательные
self.reduce_NP() # именные группы
self.reduce_PP() # предложные
self.reduce_VP() # глагольные
self.reduce_S() # полные и неполные предложения
Такой порядок важен, так как исключает возможность «упустить» некоторые члены предложения. Сначала формируются прилагательные вместе с модификаторами (e.g. безумно красивый), затем именные группы, предложные и наконец глагольные. После этого идет поиск полных/неполных предложений, если таковые отсутствуют, то дерево не имеет корня, а значит и предложение не принадлежит языку грамматики.
Рассмотрим условный пример построение дерева:




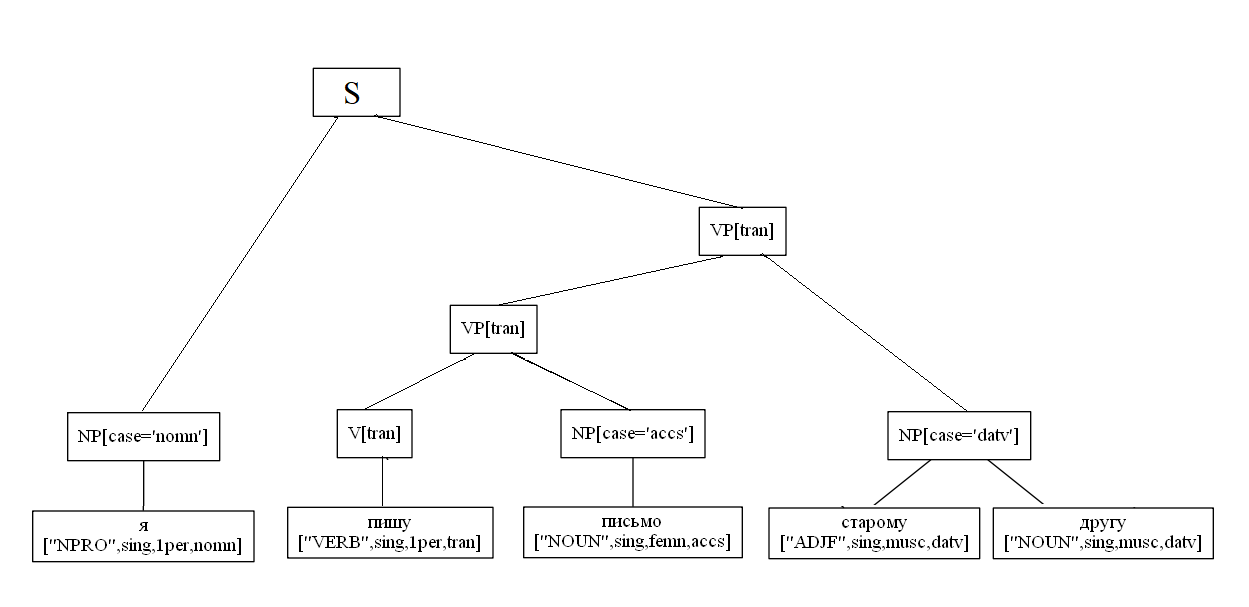
Конкретный пример разбора двусоставного предложения:
Проблемы
Естественный язык неоднозначен, его понимание зависит от ряда факторов — от особенностей грамматического строя языка, от национальной культуры, от говорящего и т.д. Перечислим основные проблемы машинной обработки языка.
Заключение
Проект доступен для использования и редактирования. Он содержит сам анализатор, дерево разбора, а также кс-грамматику русского языка и небольшой словарь составных союзов и предикатов, которые отсутствуют в словаре OpenCorpora. На данный момент для длинных сложных предложений парсер может находить 3 и более деревьев, для решения этой проблемы вносятся изменения в грамматику, а также планируется использовать вероятностных методов.
