
Подводя итог вышеизложенному, можно отметить, что библиотека pandas-profiling даёт в распоряжение аналитика некоторые полезные возможности, которые придутся кстати в тех случаях, когда нужно быстро получить общее приблизительное представление о данных или передать кому-нибудь отчёт о разведывательном анализе данных. При этом настоящая работа с данными, учитывающая их особенности, выполняется, как и без использования pandas-profiling, вручную.
Если вы хотите взглянуть на то, как выглядит весь разведывательный анализ данных в одном Jupyter-блокноте — взгляните на этот
мой проект, созданный с помощью nbviewer. А в этом
GitHub-репозитории можно найти соответствующий код.
Уважаемые читатели!
С чего вы начинаете анализ новых наборов данных?

Мне часто приходится говорить, что для понимания проще нарисовать, лучше всего нарисовать. В подавляющем большинстве случаев, после того, как всё стало понятно, остальное не так и сложно, становится делом техники. То же самое и в науке о данных, и этап, на котором всё «понимается» называется Exploratory Data Analysis (EDA) или разведочный анализ данных એ
. E DA играет важнейшую роль после получения набора данных и ставит своей целью выяснить, как с ним работать и получить требуемый результат.
Итак, в этой статье познакомлю новичков с EDA. Не волнуйтесь, всё когда-то впервые и если вы только что узнали, что EDA существует, то к концу статьи вы будете иметь четкое представление обо всех основных моментах, связанных с EDA и вместе с тем увидите пошаговые практические примеры кодирования. Давайте разбираться!
- Что такое разведочный анализ данных?
- Описание задачи
- Шаги разведочного анализа данных
- A. Загрузка и первичный осмотр данных
- B. Обработка пропущенных значений
- C. Анализ распределения переменных
- D. Исследование корреляций между переменными
- E. Выявление выбросов и аномалий
- F. Изучение категориальных переменных
- G. Визуализация результатов EDA
- Разведочный анализ данных средствами pandas
- Практический пример кодирования
- Импорт библиотек
- Загрузка набора данных
- Оценка столбцов/поиск недостающих значений
- Одномерный анализ
- Двумерный анализ
- Показатели корреляции и образец исследуемых данных
- Очистка данных
- Отсутствующие и аномальные данные
- Разведочный анализ переменных
- Разведочный анализ данных
- Однопеременные графики
- Поиск взаимосвязей
- Двухпеременные графики
- Выбираем базовый уровень
- Разведочный анализ данных средствами pandas-profiling
- Конструирование и выбор признаков
- Выбор признаков
- EDA — краткий обзор
- Что такое одномерный анализ?
- Что такое двумерный анализ
- В заключение
- Заключение
- Заключение
Что такое разведочный анализ данных?
Разведочный анализ данных, Exploratory Data Analysis (EDA) — один из первых и определяющих шагов проекта науки о данных, который приводит в движение весь проект. Он придает проекту конкретное направление и формирует план его реализации.
Разведочный анализ данных означает изучение данных до самых глубин для получения из них практической информации. Он включает в себя анализ и обобщение массивных наборов данных, часто в форме диаграмм и графиков.
Следовательно и бесспорно это самый важный этап в проекте науки о данных, по собственному опыту знаю, что он всегда занимает 70-80% времени всего проекта. Чем лучше вы знаете свой набор данных, тем лучше вы сможете его использовать! Чтобы лучше понять, какое место EDA занимает во всем процессе анализа данных, вот вам иллюстрация:

Думается, что теперь у вас появилось чёткое представление о месте, занимаемое EDA и вы готовы погрузиться в подробности!
Описание задачи
Прежде чем писать код, необходимо разобраться в решаемой задаче и доступных данных. В этом проекте мы будем работать с выложенными в общий доступ данными об энергоэффективности зданий
в Нью-Йорке.
Наша цель: использовать имеющиеся данные для построения модели, которая прогнозирует количество баллов Energy Star Score для конкретного здания, и интерпретировать результаты для поиска факторов, влияющих на итоговый балл.
Данные уже включают в себя присвоенные баллы Energy Star Score, поэтому наша задача представляет собой машинное обучение с управляемой регрессией:
- Управляемая (Supervised): нам известны признаки и цель, и наша задача — обучить модель, которая сможет сопоставить первое со вторым.
- Регрессия (Regression): балл Energy Star Score — это непрерывная переменная.
Наша модель должна быть точная — чтобы могла прогнозировать значение Energy Star Score близко к истинному, — и интерпретируемая — чтобы мы могли понять её прогнозы. Зная целевые данные, мы можем использовать их при принятии решений по мере углубления в данные и создания модели.

Перевод A Complete Machine Learning Project Walk-Through in Python: Part One
.
Когда читаешь книгу или слушаешь учебный курс про анализ данных, нередко возникает чувство, что перед тобой какие-то отдельные части картины, которые никак не складываются воедино. Вас может пугать перспектива сделать следующий шаг и целиком решить какую-то задачу с помощью машинного обучения, но с помощью этой серии статей вы обретёте уверенность в способности решить любую задачу в сфере data science.
Чтобы у вас в голове наконец сложилась цельная картина, мы предлагаем разобрать от начала до конца проект применения машинного обучения с использованием реальных данных.
Последовательно пройдём через этапы:
- Очистка и форматирование данных.
- Разведочный анализ данных.
- Конструирование и выбор признаков.
- Сравнение метрик нескольких моделей машинного обучения.
- Гиперпараметрическая настройка лучшей модели.
- Оценка лучшей модели на тестовом наборе данных.
- Интерпретирование результатов работы модели.
- Выводы и работа с документами.
Вы узнаете, как этапы переходят один в другой и как реализовать их на Python. Весь проект
доступен на GitHub, первая часть лежит здесь.
В этой статье мы рассмотрим первые три этапа.

Разведочный анализ данных, или EDA, – это как археологические раскопки в мире информации. Это первый шаг, когда мы берем на себя роль исследователя данных и начинаем расследовать, как устроены наши данные, как они взаимосвязаны и что они нам могут рассказать. E DA – это не просто скучная предварительная обработка, это настоящее приключение, в ходе которого мы обнаруживаем неожиданные моменты, паттерны и закономерности, которые часто прячутся на первый взгляд.
Представь, что ты археолог, который обнаружил древний город. Первое, что ты делаешь, – это изучаешь артефакты, учишься понимать их значение и связи между ними, прежде чем начнешь рассказывать историю этого города. Точно так же и EDA позволяет нам раскрывать истории, заложенные в данных. Мы открываем для себя ключевые факторы, влияющие на наши переменные, выявляем паттерны поведения и взаимосвязи, которые нередко оказывают решающее влияние на стратегии и принимаемые бизнес-решения.
Помимо этого, EDA – это наша страховка от неприятных сюрпризов. Мы находим аномалии данных, которые могут исказить наши выводы, и можем предпринять меры для их коррекции. Также EDA помогает нам определить, какие данные нам не хватает, чтобы получить полное представление о ситуации, и планомерно заполнить эти пробелы.
Первым делом, приступая к работе с новым набором данных, нужно понять его. Для того чтобы это сделать, нужно, например, выяснить диапазоны значений, принимаемых переменными, их типы, а также узнать о количестве пропущенных значений.
Библиотека pandas предоставляет нам множество полезных инструментов для выполнения разведочного анализа данных (Exploratory Data Analysis, EDA). Но, прежде чем воспользоваться ими, обычно нужно начать с функций более общего плана, таких как df.describe(). Правда, надо отметить, что возможности, предоставляемые подобными функциями, ограничены, а начальные этапы работы с любыми наборами данных при выполнении EDA очень часто сильно похожи друг на друга.

Автор материала, который мы сегодня публикуем, говорит, что он — не любитель выполнения повторяющихся действий. В результате он, в поисках средств, позволяющих быстро и эффективно выполнять разведочный анализ данных, нашёл библиотеку pandas-profiling
. Результаты её работы выражаются не в виде неких отдельных показателей, а в форме довольно подробного HTML-отчёта, содержащего большую часть тех сведений об анализируемых данных, которые может понадобиться знать перед тем, как приступать к более плотной работе с ними.
Здесь будут рассмотрены особенности использования библиотеки pandas-profiling на примере набора данных Titanic.
Шаги разведочного анализа данных
Давайте рассмотрим каждый шаг.
A. Загрузка и первичный осмотр данных
Первый шаг – загрузка данных и их первичный осмотр. Для этого мы будем использовать библиотеку Pandas, которая позволяет работать с табличными данными.
Задача:
Предположим, у нас есть CSV-файл sales_data.csv
с данными о продажах. Давайте загрузим данные из файла и выведем первые пять строк таблицы на экран.
import pandas as pd
# Загрузка данных
data = pd.read_csv('sales_data.csv')
# Вывод первых 5 строк таблицы
print(data.head())
B. Обработка пропущенных значений
Пропущенные значения могут повлиять на анализ, поэтому важно обработать их. В этом шаге мы будем заполнять пропущенные значения средними или медианными значениями.
Задача:
Допустим, у нас есть пропущенные значения в столбце Цена
. Мы решим эту проблему, заполнив пропущенные значения средней ценой продуктов.
mean_price = data['Цена'].mean()
data['Цена'].fillna(mean_price, inplace=True)
C. Анализ распределения переменных
В этом шаге мы будем изучать распределение числовых переменных. Мы построим гистограммы и диаграммы рассеяния для лучшего понимания данных.
Задача:
Представим, что нам интересно распределение цен на продукты. Давайте построим гистограмму для этой переменной.
import matplotlib.pyplot as plt
plt.hist(data['Цена'], bins=20, color='blue', alpha=0.7)
plt.xlabel('Цена')
plt.ylabel('Частота')
plt.title('Распределение цен на продукты')
plt.show()
D. Исследование корреляций между переменными
В этом шаге мы рассмотрим корреляции между числовыми переменными. Мы используем коэффициент корреляции, чтобы определить, какие переменные взаимосвязаны.
Задача:
Допустим, мы хотим понять, существует ли связь между ценой продукта и его количеством продаж. Давайте рассчитаем коэффициент корреляции между этими переменными.
correlation = data['Цена'].corr(data['Количество'])
print("Корреляция между ценой и количеством продаж:", correlation)
E. Выявление выбросов и аномалий
В этом шаге мы будем искать выбросы и аномалии в данных. Для этого используется визуализация, например, ящик с усами (box plot).
Задача:
Давайте определим, есть ли выбросы в столбце Количество
(количество продаж продукта). Мы построим ящик с усами для этой переменной.
plt.boxplot(data['Количество'])
plt.ylabel('Количество')
plt.title('Анализ выбросов в количестве продаж')
plt.show()
F. Изучение категориальных переменных
Категориальные переменные тоже важны. В этом шаге мы будем исследовать их распределение и частоты.
Задача:
Пусть нас интересует, какие продукты являются наиболее популярными среди покупателей. Давайте построим график частоты продаж для каждого продукта.
product_counts = data['Продукт'].value_counts()
product_counts.plot(kind='bar')
plt.xlabel('Продукт')
plt.ylabel('Частота продаж')
plt.title('Частота продаж продуктов')
plt.xticks(rotation=45)
plt.show()
G. Визуализация результатов EDA
Последний шаг – визуализация результатов всего EDA. Мы объединим несколько графиков для более полного представления.
Задача:
Давайте создадим обобщенную визуализаци
ю результатов EDA, включая гистограмму, диаграмму рассеяния и ящик с усами.
plt.figure(figsize=(10, 6))
plt.subplot(2, 2, 1)
plt.hist(data['Цена'], bins=20, color='blue', alpha=0.7)
plt.xlabel('Цена')
plt.ylabel('Частота')
plt.title('Распределение цен на продукты')
plt.subplot(2, 2, 2)
plt.scatter(data['Цена'], data['Количество'], color='green')
plt.xlabel('Цена')
plt.ylabel('Количество')
plt.title('Диаграмма рассеяния между ценой и количеством продаж')
plt.subplot(2, 2, 3)
plt.boxplot(data['Количество'])
plt.ylabel('Количество')
plt.title('Анализ выбросов в количестве продаж')
plt.tight_layout()
plt.show()
С помощью данных шагов мы прошлись от загрузки и осмотра данных до визуализации результатов анализа. Этот процесс позволяет нам лучше понять данные, выявить паттерны и зависимости, а также подготовиться к следующим этапам анализа или моделирования.
Разведочный анализ данных средствами pandas
Я решил поэкспериментировать с pandas-profiling на наборе данных Titanic из-за того, что в нём имеются данные разных типов и из-за наличия в нём пропущенных значений. Я полагаю, что библиотека pandas-profiling особенно интересна в тех случаях, когда данные ещё не очищены и требуют дальнейшей обработки, зависящей от их особенностей. Для того чтобы успешно выполнить подобную обработку, нужно знать о том, с чего начать, и на что обратить внимание. Здесь нам и пригодятся возможности pandas-profiling.
Для начала импортируем данные и используем pandas для получения показателей описательной статистики:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()
После выполнения этого фрагмента кода получится то, что показано на следующем рисунке.
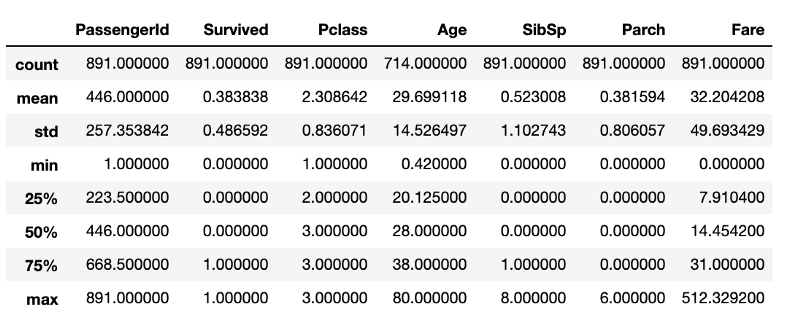
Показатели описательной статистики, полученные с помощью стандартных средств pandas
Хотя тут содержится масса полезных сведений, здесь нет всего, что было бы интересно узнать об исследуемых данных. Например, можно предположить, что во фрейме данных, в структуре DataFrame
, имеется 891 строка. Если это нужно проверить, то потребуется ещё одна строка кода, определяющую размер фрейма. Хотя эти вычисления и не особенно ресурсозатратны, постоянное их повторение обязательно приведёт к потерям времени, которое, вероятно, лучше будет потратить на очистку данных.
Практический пример кодирования
Начнём с импорта необходимых библиотек и чтения данных.
Импорт библиотек
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import matplotlib as mpl mpl.rcParams.update(mpl.rcParamsDefault)
Загрузка набора данных
data = pd.read_csv("StudentsPerformance-ru.csv")
Можно использовать функцию df.head
в Pandas для просмотра фрейма данных следующим образом:
# Выведем первые 10 строк # Наш фрейм данных называется data, поэтому мы вызываем data.head и # печатаем результат print(data.head)
Вот как выглядит наш результат:
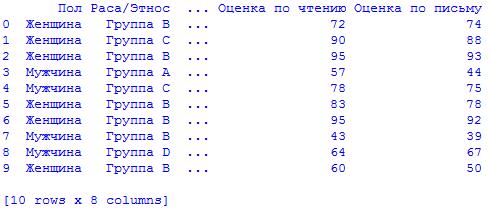
Оценка столбцов/поиск недостающих значений
Как видим, в прочитанном наборе всего 8 столбцов. Чтобы получить более подробное представление, давайте воспользуемся функцией df.info
и узнаем больше о столбцах, с которыми мы имеем дело:
data.info()
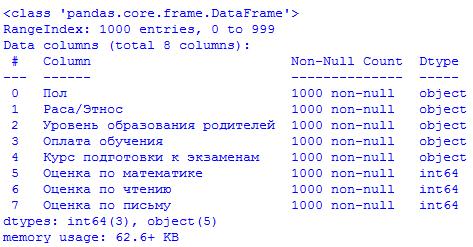
Итак, у нас есть три поля типа int
, а остальные поля типа object
. Приведенная выше информация очень помогает, когда мы применяем различные вычисления на уровне столбца.
Следующим по важности шагом является обнаружение недостающих значений, которые обязаны у нас быть. Если мы это сделаем, то нужно будет соответствующим образом действовать на дальнейших этапах разработки. На этом этапе EDA нам не обязательно иметь дело с пропущенными значениями, но нам нужно понять их, чтобы мы могли побороться с ними позже.
data.isnull().sum()

Нам повезло и в нашем наборе данных нет пропущенных значений. Это случается очень нечасто, но когда это случается, то действительно повезло!
Однако, если бы были пропущенные значения, что бы вы сделали? Поступить можно по-разному и либо отбросить отсутствующие значения, если их немного, либо заполнить их средними или медианными значениями с помощью функции Pandas data.fillna()
.
Одномерный анализ
Теперь пришло время для быстрой визуализации, чтобы увидеть, какие группы и категории входят в наши данные.
Сначала мы исследуем соотношение мужчин и женщин в наборе данных.
sns.set_style('darkgrid')
sns.countplot(y='Пол',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Пол')
plt.show()
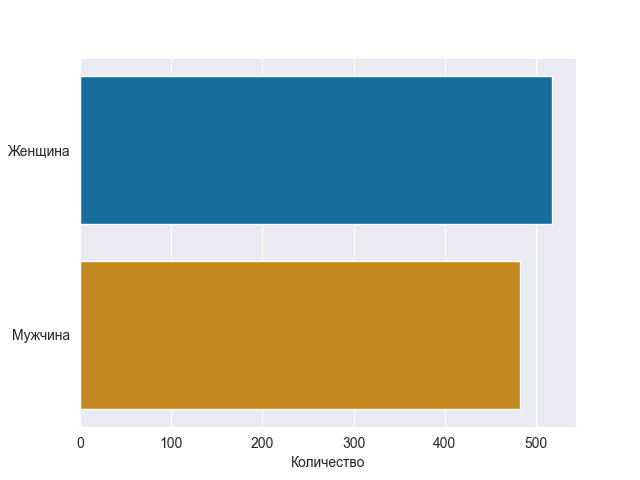
График seaborn довольно точно отражает разделение данных на мужчин и женщин. Вот более точная версия подсчета:
female_count = len(data[data['Пол']=='Женщина'])
male_count = len(data) - female_count
print("\n Всего женщин:",female_count,"\n","Всего мужчин:",male_count)

Вот и не знаю теперь, зачем нам так интересно знать соотношение полов? Важно одно — в нашем наборе данных почти одинаково встречаются представители обоих полов, в модели, которую мы разрабатываем с использованием этого набора данных, не нужно беспокоиться о каких-либо гендерных предподчтениях.
Теперь давайте посмотрим, как данные делят учащихся на разные расы или этнические группы. Будем следовать той же процедуре, что и на предыдущем шаге. График можно построить с помощью следующего кода:
sns.set_style('whitegrid')
sns.countplot(x='Раса/Этнос',data=data,palette='colorblind')
plt.xlabel("Раса/Этнос")
plt.ylabel("Количество")
plt.show()
Вот как он выглядит:
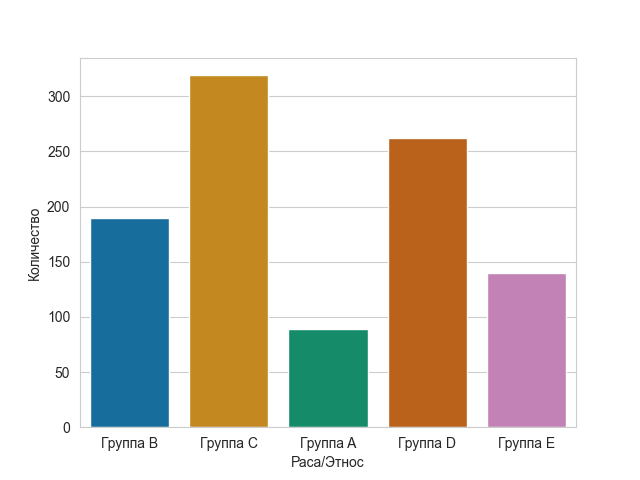
Затем мы сделаем то же самое, чтобы изучить распределение для 'Уровень образования родителей'
. Посмотрим, что у нас там есть.
sns.set_style('whitegrid')
sns.countplot(y='Уровень образования родителей',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Раса/Этнос')
plt.show()
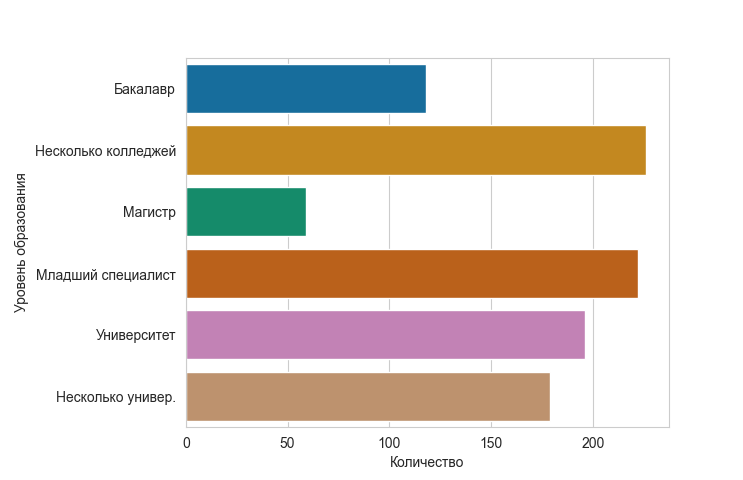
Это говорит нам о том, что у большинства родителей есть как минимум степень младшего специалиста.
Двумерный анализ
Далее мы исследуем, есть ли какая-либо корреляция (зависимость) между отдельными функциями (столбцами), которые нам необходимо учитывать. Некоторые модели, такие как Наи́вный ба́йесовский классифика́тор એ
, используют допущение об отсутствии корреляции между отдельными характеристиками, поэтому этот шаг имеет решающее значение.
Итак, давайте построим диаграммы рассеяния для различных комбинаций предметов.
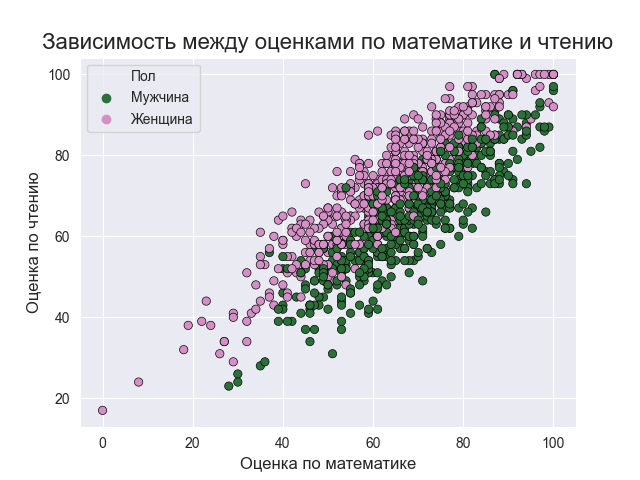
sns.set_style('darkgrid')
plt.title('Зависимость между оценками по математике и чтению',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по чтению',size=12)
sns.scatterplot(x='Оценка по математике', y='Оценка по чтению', data=data, hue='Пол', edgecolor='black', palette='cubehelix', hue_order=['Мужчина','Женщина'])
plt.show()
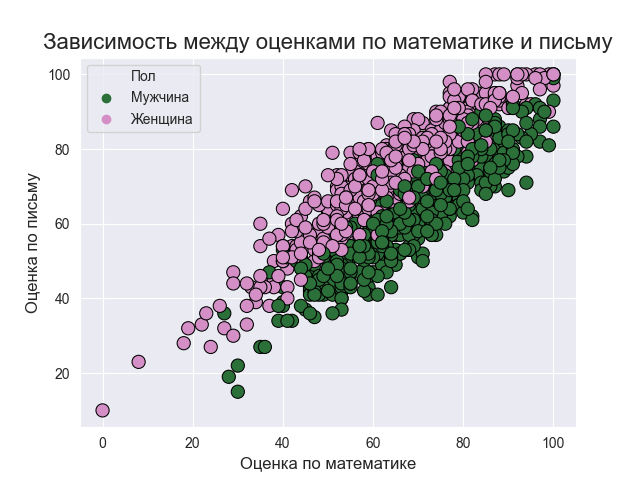
plt.title('Зависимость между оценками по математике и письму',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='Оценка по математике', y='Оценка по письму', data=data, hue='Пол', s=90, edgecolor='black', palette='cubehelix', hue_order=['Мужчина','Женщина'])
plt.show()
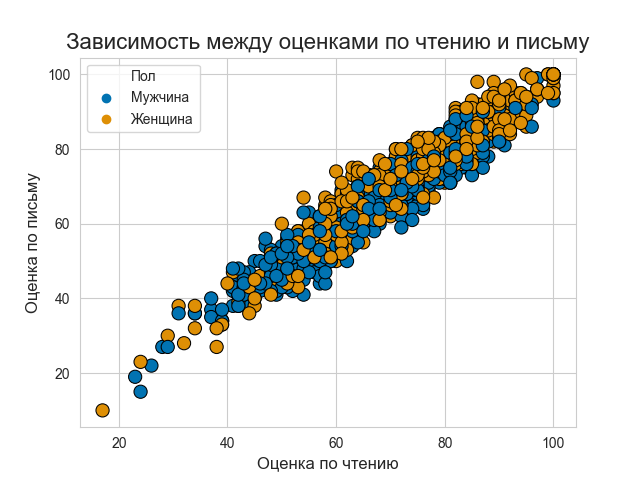
sns.set_style('whitegrid')
plt.title('Зависимость между оценками по чтению и письму',size=16)
plt.xlabel('Оценка по чтению',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='Оценка по чтению', y='Оценка по письму', data=data, hue='Пол', s=90, edgecolor='black', palette='colorblind',hue_order=['Мужчина','Женщина'])
plt.show()
Итак, диаграмма рассеяния એ
предполагает высокую степень корреляции между оценками учащихся по разным предметам. Оценки учащихся по математике и (чтению, письму) мало разбросаны, но, как правило, они показывают рост, поэтому, если ученик набирает больше по математике, то он или она также обычно набирает больше по другим предметам. С другой стороны, зависимость оценок по чтению и письму более сгруппирована вдоль прямой линии.
Подобный анализ многое говорит нам о важности EDA, ведь если бы не EDA на получение такого результата ушли бы часы.
Мы знаем, что «интегральная оценка» — это обобщенный показатель, рассчитанный на основе значений измерений и характеризующий конкретный набор данных. Поэтому, с технической точки зрения, она всегда вызывает особый интерес: какое из измерений больше всего влияет на её значение.
Чтобы это выяснить, построим еще один график, :
total_marks = ((data['Оценка по математике'] + data['Оценка по чтению'] + data['Оценка по письму'])/300)*100
data['Интегральная оценка'] = total_marks
kde_data = data[ ['Оценка по математике','Оценка по чтению','Оценка по письму','Интегральная оценка'] ]
sns.set_style("darkgrid")
sns.kdeplot(data=kde_data,shade=True, palette='colorblind')
plt.show()
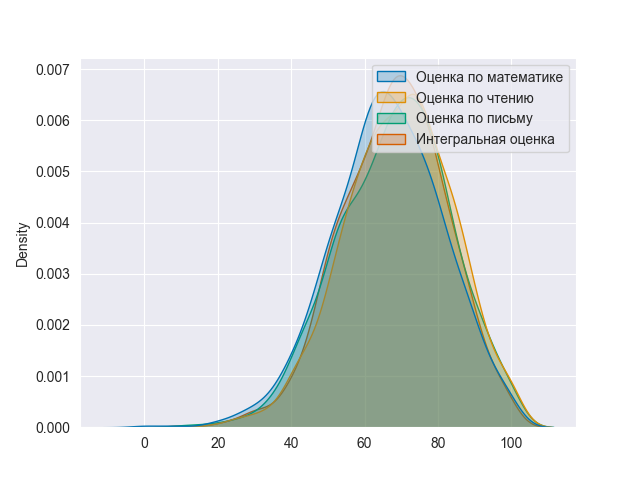
Совершенно очевидно, что почти все предметы в одинаковой степени влияют на общий балл. Таким образом, нам не нужно рассматривать какую-либо конкретную функцию, влияющую на Интегральную оценку больше, чем другие.
На сегодня все, ребята! Хотя EDA на этом не заканчивается и есть еще много чего, что надо знать, но это уже другая история. А теперь пора убедиться, что вы сможете реализовать это самостоятельно для понимания истинной сущности EDA. Архив с набором данных и код, использованные в это статье находятся здесь
.
Показатели корреляции и образец исследуемых данных
После результатов анализа переменных pandas-profiling, в разделе Correlations, выведет корреляционные матрицы Пирсона и Спирмена.
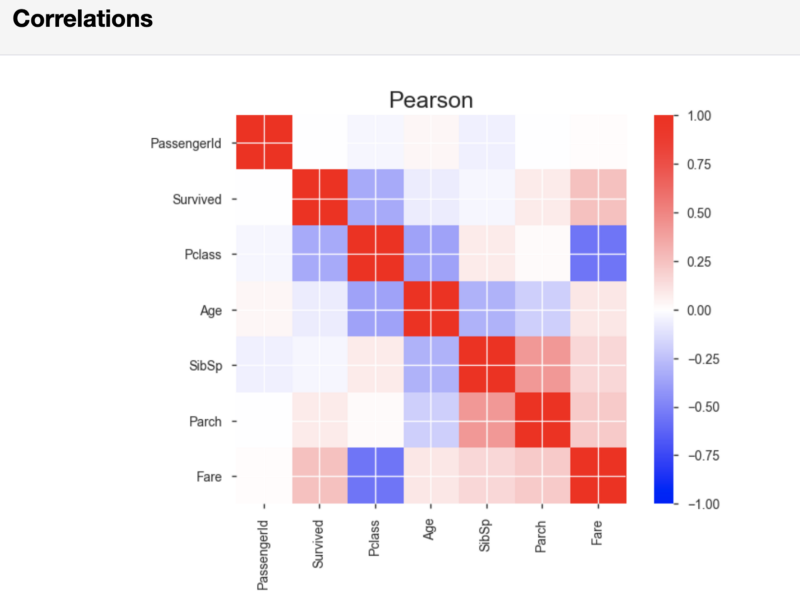
Корреляционная матрица Пирсона
Если нужно, то можно, в той строке кода, которая запускает формирование отчёта, задать показатели пороговых значений, применяемых при расчёте корреляции. Делая это, вы можете указать то, какая сила корреляции считается важной для вашего анализа.
И наконец, в отчёте pandas-profiling, в разделе Sample, выводится, в качестве примера, фрагмент данных, взятый из начала набора данных. Такой подход может привести к неприятным неожиданностям, так как первые несколько наблюдений могут представлять собой выборку, которая не отражает особенностей всего набора данных.
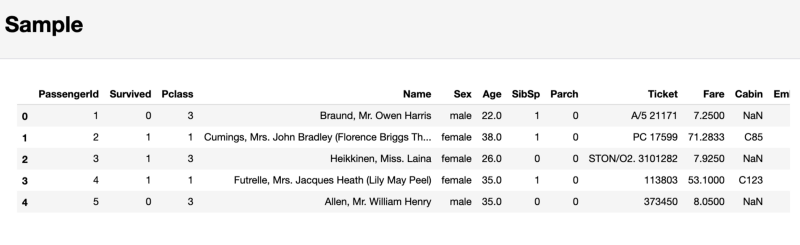
Раздел, содержащий образец исследуемых данных
В результате я не рекомендую обращать внимание на этот последний раздел. Вместо этого лучше воспользоваться командой df.sample
, которая, случайным образом, выберет 5 наблюдений из набора данных.
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars
и iris
). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести
к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head()
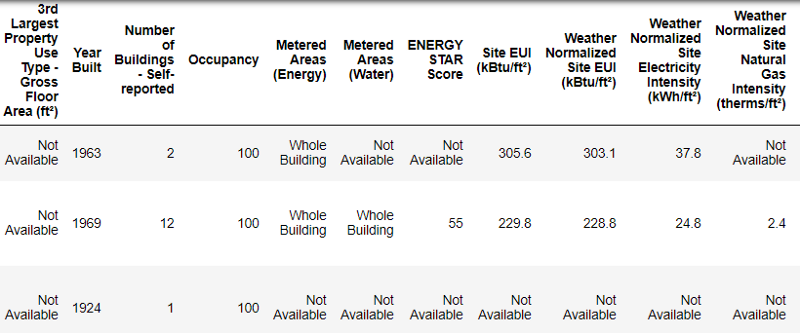
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score
, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу
, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок
. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score
— это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object
, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info()
:
# See the column data types and non-missing values
data.info()
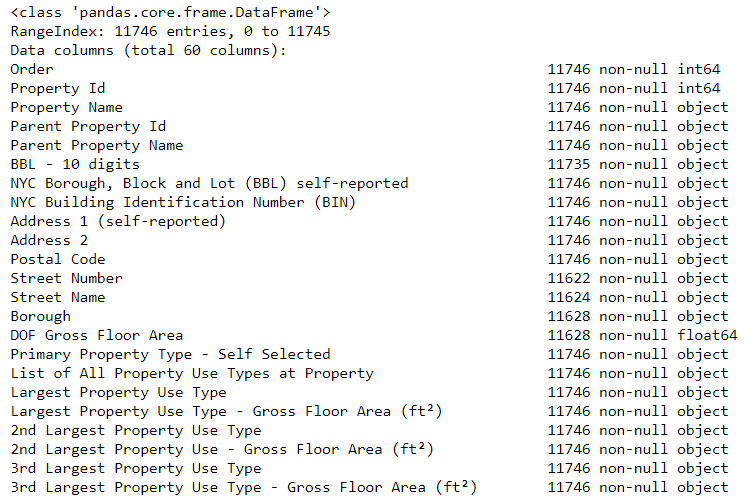
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float
)!
Этот код сначала заменяет все «Not Available» на not a number
( np.nan
), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float
:
# Replace all occurrences of Not Available with numpy not a number
data = data.replace({'Not Available': np.nan})
# Iterate through the columns
for col in list(data.columns):
# Select columns that should be numeric
if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score' in col):
# Convert the data type to float
data[col] = data[col].astype(float)
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке ( код здесь
).
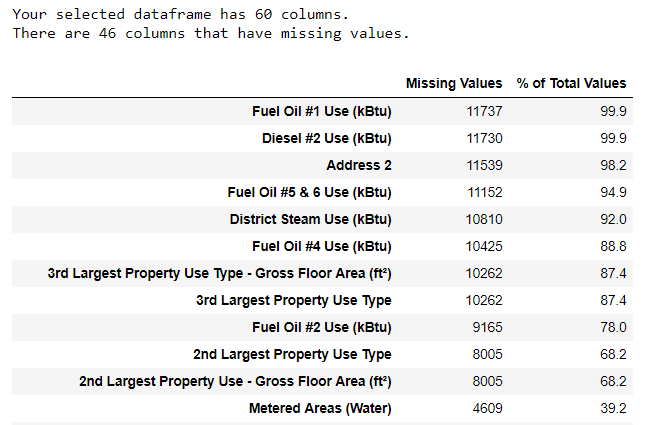
Для создания таблицы использована функция из ветки на StackOverflow
.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи ( вот обсуждение
), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий
:
- Ниже первого квартиля − 3 ∗ интерквартильный размах.
- Выше третьего квартиля + 3 ∗ интерквартильный размах.
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
Разведочный анализ переменных
За разделом Overview в отчёте можно обнаружить полезные сведения о каждой переменной. В них, кроме прочего, входят небольшие диаграммы, описывающие распределение каждой переменной.

Сведения о числовой переменной Age
Как можно видеть из предыдущего примера, pandas-profiling даёт нам несколько полезных индикаторов, таких, как процент и количество пропущенных значений, а также показатели описательной статистики, которые мы уже видели. Так как Age
— это числовая переменная, визуализация её распределения в виде гистограммы позволяет нам сделать вывод о том, что перед нами — скошенное вправо распределение.
При рассмотрении категориальной переменной выводимые показатели немного отличаются от тех, что были найдены для числовой переменной.

Сведения о категориальной переменной Sex
А именно, вместо нахождения среднего, минимума и максимума, библиотека pandas-profiling нашла число классов. Так как Sex
— бинарная переменная, её значения представлены двумя классами.
Если вы, как и я, любите исследовать код, то вас может заинтересовать то, как именно библиотека pandas-profiling вычисляет эти показатели. Узнать об этом, учитывая то, что код библиотеки открыт и доступен на GitHub, не так уж и сложно. Так как я не большой любитель использования «чёрных ящиков» в моих проектах, я взглянул на исходный код библиотеки. Например, вот как выглядит механизм обработки числовых переменных, представленный функцией describe_numeric_1d
:
def describe_numeric_1d(series, **kwargs):
"""Compute summary statistics of a numerical (`TYPE_NUM`) variable (a Series).
Also create histograms (mini an full) of its distribution.
Parameters
----------
series : Series
The variable to describe.
Returns
-------
Series
The description of the variable as a Series with index being stats keys.
"""
# Format a number as a percentage. For example 0.25 will be turned to 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# To avoid to compute it several times
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# The dropna() is a workaround for https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] if stats['mean'] else np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Histograms
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name)
Хотя этот фрагмент кода и может показаться довольно большим и сложным, на самом деле, понять его очень просто. Речь идёт о том, что в исходном коде библиотеки имеется функция, которая определяет типы переменных. Если оказалось, что библиотека встретила числовую переменную, вышеприведённая функция найдёт показатели, которые мы рассматривали. В этой функции используются стандартные операции pandas по работе с объектами типа Series
, наподобие series.mean()
. Результаты вычислений сохраняются в словаре stats
. Гистограммы формируются с использованием адаптированной версии функции matplotlib.pyplot.hist
. Адаптация направлена на то, чтобы функция могла бы работать с различными типами наборов данных.
Разведочный анализ данных
Коротко говоря, РАД — это попытка выяснить, что нам могут сказать данные. Обычно анализ начинается с поверхностного обзора, затем мы находим интересные фрагменты и анализируем их подробнее. Выводы могут быть интересными сами по себе, или они могут способствовать выбору модели, помогая решить, какие признаки мы будем использовать.
Однопеременные графики
Наша цель — прогнозировать значение Energy Star Score (в наших данных переименовано в score
), так что имеет смысл начать с исследования распределения этой переменной. Гистограмма — простой, но эффективный способ визуализации распределения одиночной переменной, и её можно легко построить с помощью matplotlib
.
import matplotlib.pyplot as plt
# Histogram of the Energy Star Score
plt.style.use('fivethirtyeight')
plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k');
plt.xlabel('Score'); plt.ylabel('Number of Buildings');
plt.title('Energy Star Score Distribution');
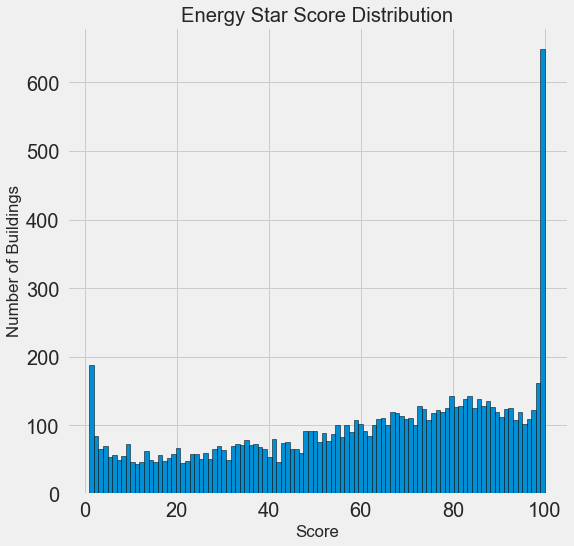
Выглядит подозрительно! Балл Energy Star Score является процентилем, значит следует ожидать единообразного распределения, когда каждый балл присваивается одному и тому же количеству зданий. Однако высший и низший результаты получило непропорционально большое количество зданий (для Energy Star Score чем больше, тем лучше).
Если мы снова посмотрим на определение этого балла, то увидим, что он рассчитывается на основе «самостоятельно заполняемых владельцами зданий отчётов», что может объяснить избыток очень больших значений. Просить владельцев зданий сообщать о своём энергопотреблении, это как просить студентов сообщать о своих оценках на экзаменах. Так что это, пожалуй, не самый объективный критерий оценки энергоэффективности недвижимости.
Если бы у нас был неограниченный запас времени, то можно было бы выяснить, почему так много зданий получили очень высокие и очень низкие баллы. Для этого нам пришлось бы выбрать соответствующие здания и внимательно их проанализировать. Но нам нужно только научиться прогнозировать баллы, а не разработать более точный метод оценки. Можно пометить себе, что у баллов подозрительное распределение, но мы сосредоточимся на прогнозировании.
Поиск взаимосвязей
Главная часть РАД — поиск взаимосвязей между признаками и нашей целью. Коррелирующие с ней переменные полезны для использования в модели, потому что их можно применять для прогнозирования. Один из способов изучения влияния категориальной переменной (которая принимает только ограниченный набор значений) на цель — это построить график плотности с помощью библиотеки Seaborn.
График плотности можно считать сглаженной гистограммой
, потому что он показывает распределение одиночной переменной. Можно раскрасить отдельные классы на графике, чтобы посмотреть, как категориальная переменная меняет распределение. Этот код строит график плотности Energy Star Score, раскрашенный в зависимости от типа здания (для списка зданий с более чем 100 измерениями):
# Create a list of buildings with more than 100 measurements
types = data.dropna(subset=['score'])
types = types['Largest Property Use Type'].value_counts()
types = list(types[types.values > 100].index)
# Plot of distribution of scores for building categories
figsize(12, 10)
# Plot each building
for b_type in types:
# Select the building type
subset = data[data['Largest Property Use Type'] == b_type]
# Density plot of Energy Star Scores
sns.kdeplot(subset['score'].dropna(),
label = b_type, shade = False, alpha = 0.8);
# label the plot
plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20);
plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
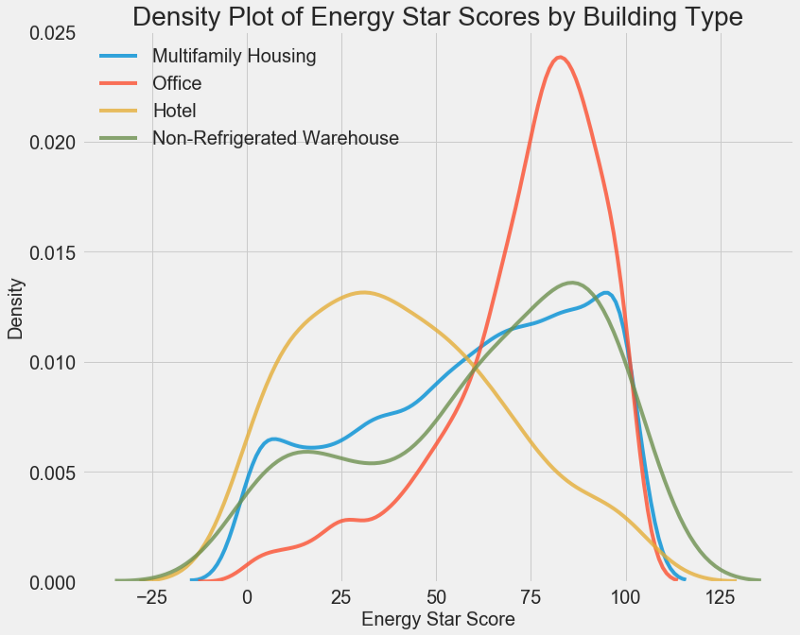
Как видите, тип здания сильно влияет на количество баллов. Офисные здания обычно имеют более высокий балл, а отели более низкий. Значит нужно включить тип здания в модель, потому что этот признак влияет на нашу цель. В качестве категориальной переменной мы должны выполнить one-hot кодирование типа здания.
Аналогичный график можно использовать для оценки Energy Star Score по районам города:
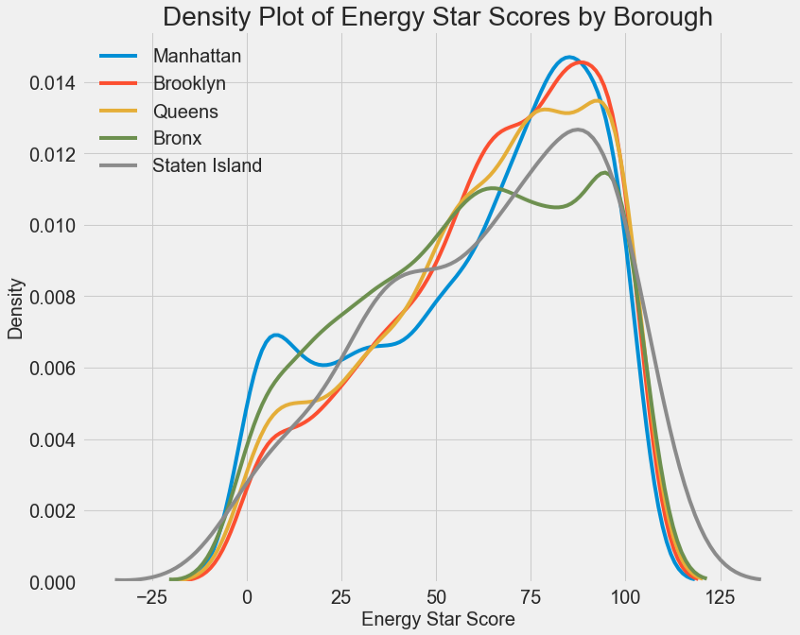
Район не так сильно влияет на балл, как тип здания. Тем не менее мы включим его в модель, потому что между районами существует небольшая разница.
Чтобы посчитать взаимосвязи между переменными, можно использовать коэффициент корреляции Пирсона
. Это мера интенсивности и направления линейной зависимости между двумя переменными. Значение +1 означает идеально линейную положительную зависимость, а -1 означает идеально линейную отрицательную зависимость. Вот несколько примеров значений коэффициента корреляции Пирсона
:

Хотя этот коэффициент не может отражать нелинейные зависимости, с него можно начать оценку взаимосвязей переменных. В Pandas можно легко вычислить корреляции между любыми колонками в кадре данных (dataframe):
# Find all correlations with the score and sort
correlations_data = data.corr()['score'].sort_values()
Самые отрицательные корреляции с целью:

и самые положительные:

Есть несколько сильных отрицательных корреляций между признаками и целью, причём наибольшие из них относятся к разным категориям EUI (способы расчёта этих показателей слегка различаются). EUI (Energy Use Intensity
, интенсивность использования энергии) — это количество энергии, потреблённой зданием, делённое на квадратный фут площади. Эта удельная величина используется для оценки энергоэффективности, и чем она меньше, тем лучше. Логика подсказывает, что эти корреляции оправданны: если EUI увеличивается, то Energy Star Score должен снижаться.
Двухпеременные графики
Воспользуемся диаграммами рассеивания для визуализации взаимосвязей между двумя непрерывными переменными. К цветам точек можно добавить дополнительную информацию, например, категориальную переменную. Ниже показана взаимосвязь Energy Star Score и EUI, цветом обозначены разные типы зданий:
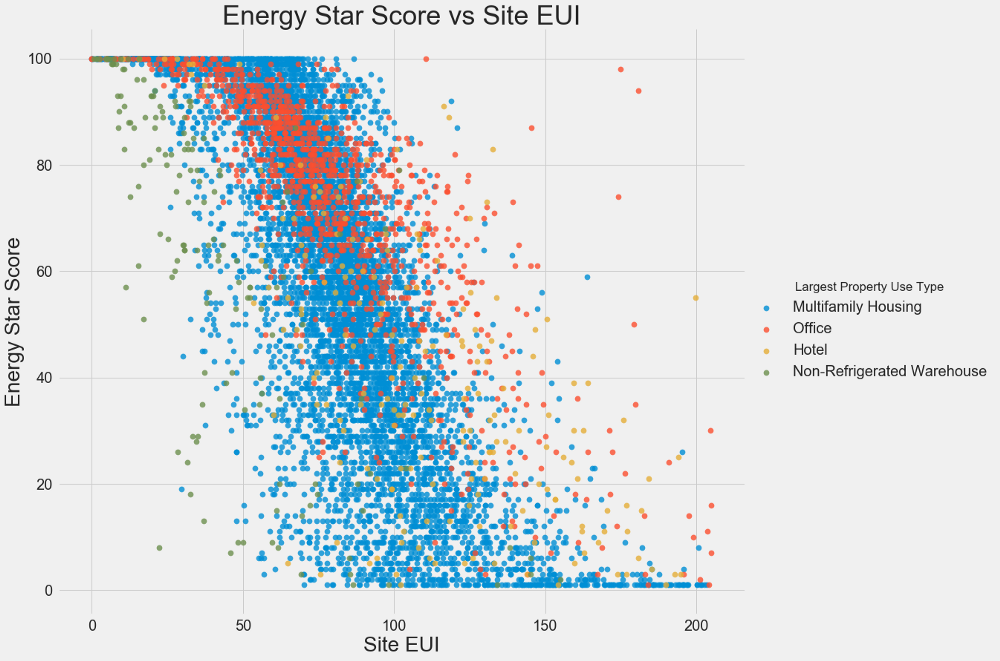
Этот график позволяет визуализировать коэффициент корреляции -0,7. По мере уменьшения EUI увеличивается Energy Star Score, эта взаимосвязь наблюдается у зданий разных типов.
Наш последний исследовательский график называется Pairs Plot (парный график)
. Это прекрасный инструмент, позволяющий увидеть взаимосвязи между различными парами переменных и распределение одиночных переменных. Мы воспользуемся библиотекой Seaborn и функцией PairGrid
для создания парного графика с диаграммой рассеивания в верхнем треугольнике, с гистограммой по диагонали, двухмерной диаграммой плотности ядра и коэффициентов корреляции в нижнем треугольнике.
# Extract the columns to plot
plot_data = features[['score', 'Site EUI (kBtu/ft²)',
'Weather Normalized Source EUI (kBtu/ft²)',
'log_Total GHG Emissions (Metric Tons CO2e)']]
# Replace the inf with nan
plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan})
# Rename columns
plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI',
'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI',
'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'})
# Drop na values
plot_data = plot_data.dropna()
# Function to calculate correlation coefficient between two columns
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# Create the pairgrid object
grid = sns.PairGrid(data = plot_data, size = 3)
# Upper is a scatter plot
grid.map_upper(plt.scatter, color = 'red', alpha = 0.6)
# Diagonal is a histogram
grid.map_diag(plt.hist, color = 'red', edgecolor = 'black')
# Bottom is correlation and density plot
grid.map_lower(corr_func);
grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds)
# Title for entire plot
plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
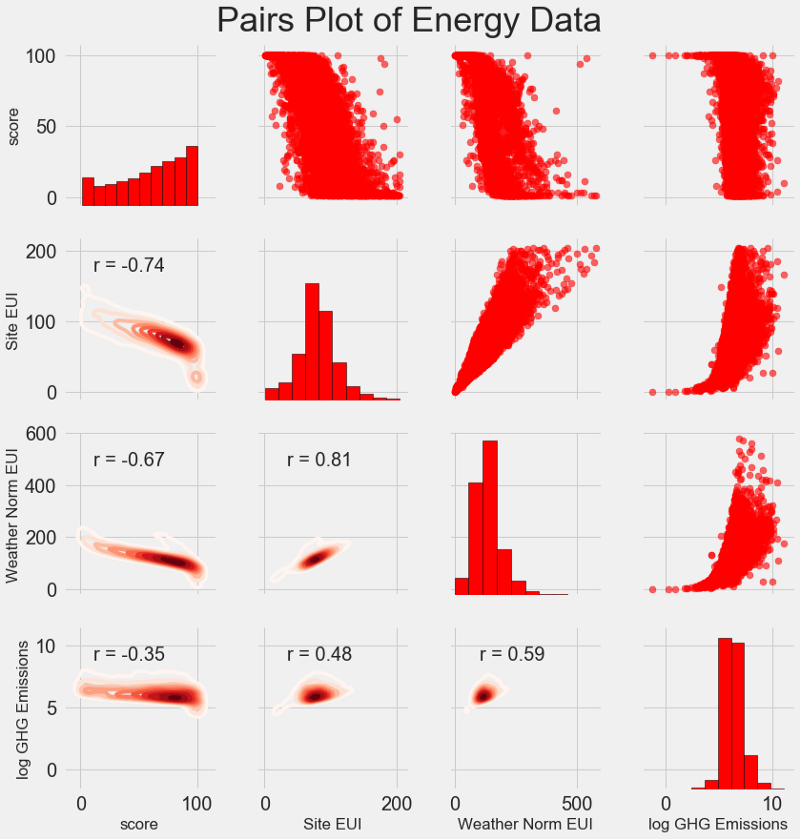
Чтобы увидеть взаимосвязи переменных, поищем пересечения рядов и колонок. Допустим, нужно посмотреть корреляцию Weather Norm EUI
и score
, тогда мы ищем ряд Weather Norm EUI
и колонку score
, на пересечении которых стоит коэффициент корреляции -0,67. Эти графики не только классно выглядят, но и помогают выбрать переменные для модели.
Выбираем базовый уровень
Для регрессионных задач в качестве базового уровня разумно угадывать медианное значение цели на обучающем наборе для всех примеров в тестовом наборе. Эти наборы задают барьер, относительно низкий для любой модели.
В качестве метрики возьмём среднюю абсолютную ошибку (mae)
в прогнозах. Для регрессий есть много других метрик, но мне нравится совет
выбирать какую-то одну метрику и с её помощью оценивать модели. А среднюю абсолютную ошибку легко вычислить и интерпретировать.
Прежде чем вычислять базовый уровень, нужно разбить данные на обучающий и тестовый наборы:
- Обучающий набор признаков — то, что мы предоставляем нашей модели вместе с ответами в ходе обучения. Модель должна выучить соответствие признаков цели.
- Тестовый набор признаков используется для оценки обученной модели. Когда она обрабатывает тестовый набор, то не видит правильных ответов и должна прогнозировать, опираясь только на доступные признаки. Мы знаем ответы для тестовых данных и можем сравнить с ними результаты прогнозирования.
Для обучения используем 70 % данных, а для тестирования — 30 %:
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)
Теперь вычислим показатель для исходного базового уровня:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true - y_pred))
baseline_guess = np.median(y)
print('The baseline guess is a score of %0.2f' % baseline_guess)
print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
The baseline guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164
Средняя абсолютная ошибка на тестовом наборе составила около 25 пунктов. Поскольку мы оцениваем в диапазоне от 1 до 100, то ошибка составляет 25 % — довольно низкий барьер для модели!
Разведочный анализ данных средствами pandas-profiling
Теперь сделаем то же самое с использованием pandas-profiling:
pandas_profiling.ProfileReport(df)
Выполнение представленной выше строки кода позволит сформировать отчёт с показателями разведочного анализа данных. Код, показанный выше, приведёт к выводу найденных сведений о данных, но можно сделать так, чтобы в результате получился бы HTML-файл, который, например, можно кому-то показать.
Первая часть отчёта будет содержать раздел Overview (Обзор), дающий основные сведения о данных (количество наблюдений, количество переменных, и так далее). Кроме того, он будет содержать список предупреждений, уведомляющий аналитика о том, на что стоит обратить особое внимание. Эти предупреждения могут послужить подсказкой о том, на чём можно сосредоточить усилия при очистке данных.
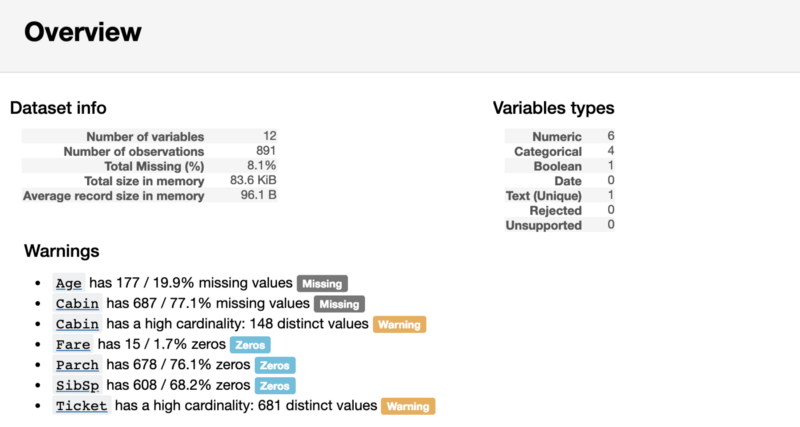
Раздел отчёта Overview
Конструирование и выбор признаков
Конструирование и выбор признаков
зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
- Применим к категориальным переменным (квартал и тип собственности) one-hot кодирование.
- Добавим взятие натурального логарифма от всех числовых переменных.
One-hot кодирование
необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки
, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
# Copy the original data
features = data.copy()
# Select the numeric columns
numeric_subset = data.select_dtypes('number')
# Create columns with log of numeric columns
for col in numeric_subset.columns:
# Skip the Energy Star Score column
if col == 'score':
next
else:
numeric_subset['log_' + col] = np.log(numeric_subset[col])
# Select the categorical columns
categorical_subset = data[['Borough', 'Largest Property Use Type']]
# One hot encode
categorical_subset = pd.get_dummies(categorical_subset)
# Join the two dataframes using concat
# Make sure to use axis = 1 to perform a column bind
features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Выбор признаков
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
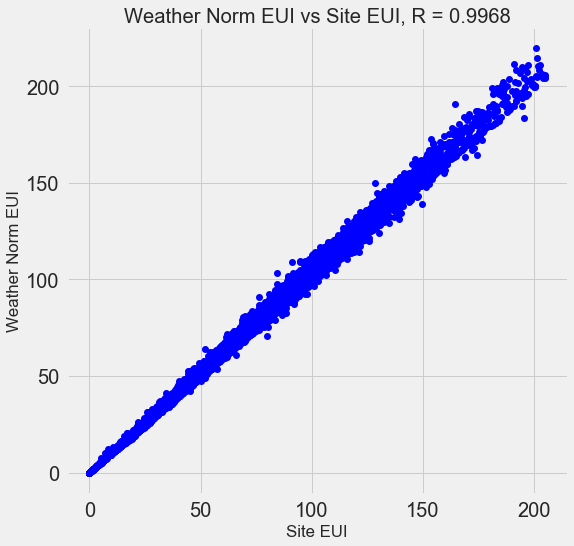
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными
. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой
. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии ( variance inflation factor
). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow
).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично
, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = 'all')
print(features.shape)
(11319, 65)
EDA — краткий обзор
Кратко определим этапы, которые включает EDA, после приведу практические примеры, в которых используем различные методы EDA на реальном наборе данных.
Хотя методы EDA следует применять в соответствии с ситуацией и доступными типами данных, я постараюсь сделать это, используя основные приемы, которые вам нужно знать как новичку и которые являются фундаментом в анализе данных. Посмотрим:
Что такое одномерный анализ?
Как следует из названия, одномерный анализ — это когда анализ переменных выполняется по отдельности. Независимо от того, является ли переменная категориальной или непрерывной, если мы анализируем ее независимо от других переменных, то это называется одномерным анализом.
Вот некоторые из основных методов одномерного анализа:
- Основные тенденции
;
- Дисперсия;
- Визуализации (блоковые диаграммы, гистограммы и т. д.)
Что такое двумерный анализ
Двумерный анализ относится к изучению взаимосвязи между любыми двумя переменными в наборе данных. Это может быть связь между любыми двумя переменными‑предикторами или с целевой переменной. Такие отношения, если они существуют, могут вызвать проблемы во время разработки модели, например, шум.
Некоторые из методов, используемых для двумерного анализа:
В заключение
EDA, Exploratory Data Analysis или разведочный анализ данных — один из важнейших этапов проекта в области науки о данных. Он не только помогает определить направление проекта, но также помогает использовать набор данных наилучшим образом.
На протяжении всей статьи мы видели все основные концепции, задействованные в типичном процессе EDA. Кроме того, мы прошли пошаговую реализацию некоторых основных практик EDA с использованием практического набора данных.
Однако, это только начало. По мере продвижения вы обнаружите, что мир EDA гораздо более разнообразен и детализирован. Лучший способ научиться — попробовать выполнить собственный EDA на некоторых из наших наборов данных для проектов машинного обучения
.
По мотивам Exploratory Data Analysis in Python: Beginner’s Guide for 2021

Заключение
Разведочный анализ данных является неотъемлемой частью успешного анализа данных и позволяет сделать первые выводы, идентифицировать интересные тренды и подготовить данные для последующих этапов работы. При проведении EDA важно не только использовать технические методы, но и иметь интуитивное понимание данных и их контекста.
Напоследок хочу порекомендовать вам
бесплатный вебинар
, где коллеги из OTUS расскажут про то, какие виды требований бывают и как они коррелируют между собой. Как понять, что заказчик пришел к тебе с реальной проблемой, и как отличить проблему, потребность и решение.
Заключение
Вы этой статье мы прошли через три первых этапа решения задачи с помощью машинного обучения. После постановки задачи мы:
- Очистили и отформатировали сырые данные.
- Провели разведочный анализ для изучения имеющихся данных.
- Выработали набор признаков, которые будем использовать для наших моделей.
Наконец, мы вычислили базовый уровень, с помощью которого будем оценивать наши алгоритмы.
В следующей статье
мы научимся с помощью Scikit-Learn
оценивать модели машинного обучения, выбирать лучшую модель и выполнять её гиперпараметрическую настройку.
