
Обработка естественного языка сейчас не используются разве что в совсем консервативных отраслях. В большинстве технологических решений распознавание и обработка «человеческих» языков давно внедрена: именно поэтому обычный IVR с жестко заданными опциями ответов постепенно уходит в прошлое, чатботы начинают все адекватнее общаться без участия живого оператора, фильтры в почте работают на ура и т.д. Как же происходит распознавание записанной речи, то есть текста? А вернее будет спросить, что лежит в основе соврменных техник распознавания и обработки? На это хорошо отвечает наш сегодняшний адаптированный перевод – под катом вас ждет лонгрид, который закроет пробелы по основам NLP. Приятного чтения!

- Что такое Natural Language Processing?
- Основные концепции spaCy
- Разделение текста на слова и пунктуацию
- Разбиение текста на предложения
- Значение частей речи для анализа текста
- Лемматизация и нормализация
- Важность лемматизации при анализе текста
- Именованная сущность (NER) извлечение
- Применение NER в задачах информационного поиска
- СПАСИБО
- Рейк-Нлтк
- Генсим
- Заключение
- Токенизация
- Подсчёт слов
- Состав документа
- Введение в SpaCy
- Стоп-слова
- Леммы
- Перевод аудио в текст
- Материалы по теме
- Извлечение ключевых слов
- Автоматическая аннотация текстов
- Работа с векторными представлениями
- Использование встроенных векторов слов в spaCy
- Пользовательские векторы
- Применение пользовательских векторов в задачах классификации и кластеризации
- Синтаксический анализ
- Использование дерева зависимостей для анализа отношений между словами
- Грамматические отношения
- Примеры использования грамматических отношений для извлечения информации
- Siri
- Gmail
- Dialogflow
- Python-библиотека NLTK
Что такое Natural Language Processing?
Natural Language Processing (далее – NLP) – обработка естественного языка – подраздел информатики и AI, посвященный тому, как компьютеры анализируют естественные (человеческие) языки. N LP позволяет применять алгоритмы машинного обучения для текста и речи.
Например, мы можем использовать NLP, чтобы создавать системы вроде распознавания речи, обобщения документов, машинного перевода, выявления спама, распознавания именованных сущностей, ответов на вопросы, автокомплита, предиктивного ввода текста и т.д.
Сегодня у многих из нас есть смартфоны с распознаванием речи – в них используется NLP для того, чтобы понимать нашу речь. Также многие люди используют ноутбуки со встроенным в ОС распознаванием речи.
Время на прочтение
Обработка естественного языка (NLP) представляет собой важную область исследований, объединяющую лингвистику, компьютерные науки и искусственный интеллект. Она посвящена разработке методов и инструментов для анализа, понимания и генерации текста человеческими искусственными системами. Важность NLP становится все более явной, поскольку она находит применение в различных сферах, включая автоматический перевод, анализ тональности, извлечение информации, вопросно-ответные системы и многое другое.
В мире обработки естественного языка существует множество инструментов и библиотек, предназначенных для упрощения этой сложной задачи. Однако библиотека spaCy выделяется своей эффективностью и производительностью. Она разработана с акцентом на скорость и точность, что делает ее предпочтительным выбором для многих разработчиков и исследователей в области NLP.
Обработка естественного языка – это не только наука, но и искусство. Верность интерпретации текста, умение извлекать скрытые смыслы и генерировать «человекопонимаемый» контент – все это требует глубокого понимания инструментов, которые мы используем. spaCy становится вашим надежным союзником в этом креативном процессе, и давайте вместе исследуем, как он может вдохновить нас на создание потрясающих решений.
Основные концепции spaCy
Одним из первых шагов в обработке естественного языка является разделение текста на более мелкие единицы, такие как слова и предложения. Этот процесс называется токенизацией. SpaCy обладает мощными инструментами для токенизации и сегментации текста, позволяя эффективно разбивать текст на смысловые компоненты.
Разделение текста на слова и пунктуацию
Процесс разделения текста на отдельные слова и пунктуационные символы является основой для большинства анализов в NLP. SpaCy предоставляет нам простой и эффективный способ этого сделать. Давайте рассмотрим пример:
import spacy
# Загружаем языковую модель
nlp = spacy.load(«en_core_web_sm»)
# Входной текст
text = «spaCy is an amazing tool for natural language processing.»
# Применяем токенизацию
doc = nlp(text)
# Выводим токены (слова и пунктуацию) из текста
for token in doc:
print(token.text)
В данном примере мы используем предварительно обученную английскую языковую модель (en_core_web_sm), загружаем ее с помощью spacy.load(). Затем мы передаем текст через эту модель, получаем объект Doc и можем итерироваться по токенам, выводя их текст.
Разбиение текста на предложения
Часто текст состоит не только из слов, но и из предложений. SpaCy обеспечивает удобный способ разделения текста на предложения:
import spacy
# Загружаем языковую модель
nlp = spacy.load(«en_core_web_sm»)
# Входной текст с несколькими предложениями
text = «SpaCy is fast. It’s also efficient.»
# Применяем разбиение на предложения
doc = nlp(text)
# Выводим предложения из текста
for sentence in doc.sents:
print(sentence.text)
Здесь мы используем метод doc.sents, который автоматически распознает предложения в тексте и возвращает их в виде отдельных объектов Span.
Частеречная разметка (Part-of-Speech tagging или POS-тегирование) – это процесс присвоения каждому слову в тексте определенной метки, соответствующей его грамматической роли. SpaCy предоставляет мощные инструменты для выполнения этой задачи.
import spacy
# Загружаем языковую модель
nlp = spacy.load(«en_core_web_sm»)
# Входной текст
text = «I like to read books.»
# Применяем анализ
doc = nlp(text)
# Выводим слова и их части речи
for token in doc:
print(token.text, token.pos_)
В этом примере мы используем свежезагруженную английскую языковую модель (en_core_web_sm), создаем объект Doc для входного текста и итерируем по токенам (словам), выводя текст каждого токена и его часть речи.
Значение частей речи для анализа текста
Части речи являются ключевыми элементами анализа текста, поскольку они раскрывают структуру и смысл предложения. Различные части речи могут указывать на субъект, объект, действие, качество и т.д. Эта информация имеет большое значение для множества приложений, от анализа тональности до извлечения информации.
Лемматизация и нормализация
Лемматизация — это процесс приведения слова к его базовой форме (лемме) путем удаления окончаний и суффиксов. Это помогает унифицировать различные формы слова и улучшить точность анализа.
import spacy
nlp = spacy.load(«en_core_web_sm»)
text = «running dogs are happily barking»
doc = nlp(text)
for token in doc:
print(token.text, token.lemma_)
Важность лемматизации при анализе текста
Лемматизация позволяет снизить размерность данных, учитывая только базовые формы слов. Это особенно полезно, например, при анализе тональности, чтобы учесть все формы одного слова, когда выражается какой-либо оттенок.
Именованная сущность (NER) извлечение
Именованные сущности (Named Entities) — это объекты реального мира, которые можно идентифицировать по имени, такие как имена людей, места, даты, организации и т.д. Извлечение и классификация именованных сущностей является важной задачей в NLP. SpaCy предоставляет удобные инструменты для этой цели.
import spacy
nlp = spacy.load(«en_core_web_sm»)
text = «Apple is going to build a new office in London in 2023.»
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
Применение NER в задачах информационного поиска
Извлечение именованных сущностей имеет множество применений. В информационном поиске, например, оно может быть использовано для автоматической классификации документов по тематикам, выделения ключевых фактов или для создания связей между сущностями.
Мы обсудим spaCy, YAKE, rake-nltk и Gensim для процесса извлечения ключевых слов.

Проснувшись утром, вы первым делом открываете телефон и проверяете сообщения. Ваш разум приучен игнорировать сообщения в WhatsApp тех людей и групп, которые вам не нравятся. Вы определяете важность сообщения, проверяя только ключевые слова людей и название группы.
Ваш разум будет извлекать ключевые слова из имени группы WhatsApp или имени контакта и приучать себя любить это или игнорировать. Это также зависит от многих других факторов. Такое же поведение можно увидеть при чтении статей, просмотре сериалов или сериалов Netflix и т. Д.
Машинное обучение может имитировать такое же поведение. Это известно как извлечение ключевых слов в обработке естественного языка (NLP). Таким образом, чтение статей или новостей будет зависеть от извлеченных ключевых слов, таких как наука о данных, машинное обучение, искусственный интеллект и т. Д.
Вы можете проверить, принадлежит ли ваша статья к текущему тренду или нет. Либо ваша статья будет в тренде, либо нет. Просто выполните поиск по извлеченным ключевым словам по трендам Google. Это один из факторов, а не единственный.
В этой статье мы рассмотрим библиотеки Python, которые помогают в процессе извлечения ключевых слов.
СПАСИБО
SpaCy — это все в одной библиотеке Python для задач НЛП. Но нас интересует функция извлечения ключевых слов в spaCy.
Мы начнем с установки библиотеки spaCy, а затем загрузим модель en_core_sci_lg. После этого передайте текст статьи в конвейер НЛП. Он вернет извлеченные ключевые слова.
Каждая модель имеет свой функционал. Если статья состоит из медицинских терминов, используйте модель en_core_sci_lg. В противном случае вы можете использовать модель en_core_web_sm.
Найдите соответствующий код ниже.
Используйте библиотеку Python YAKE для управления процессом извлечения ключевых слов.
Еще одна библиотека Keyword Extractor (Yake) выбирает наиболее важные ключевые слова, используя метод статистических функций текста из статьи. С помощью YAKE вы можете контролировать количество извлеченных ключевых слов и другие функции.
Для deduplication_threshold = 0,1
Для deduplication_threshold = 0.9
4. Переменная numOfKeywords будет определять количество извлеченных ключевых слов. Если numOfKeywords = 20, то общее извлеченное ключевое слово будет меньше и равно 20.
Другие методы извлечения ключевых слов, которые вы можете протестировать на своих данных.
Рейк-Нлтк
2. Производительность Rake-nltk сравнима с spacy.
Генсим
Gensim в первую очередь разработан для тематического моделирования. Со временем Gensim добавил другие задачи НЛП, такие как обобщение, поиск сходства текста и т. Д. Здесь мы продемонстрируем использование Genism для задач извлечения ключевых слов.
Установите genism с помощью команды pip install gensim.
Заключение
В этой статье я объяснил 4 библиотеки Python (spaCy, YAKE, rake-nltk, Gensim), которые извлекают ключевые слова из статьи или текстовых данных. Вы также можете поискать другие библиотеки Python для аналогичной задачи.
Надеюсь, эта статья поможет вам в решении ваших задач НЛП.

Я описал инструменты и методы для новичков, имеющих только общее представление в данной теме. Если вы более опытный практик, вам нужны вторая часть о представлении вектора и третья — тематическое моделирование и конвейеры. Конечно, в этой области есть свой жаргон. Он может немного напугать, но я сведу технические термины к минимуму.
Вам понадобится базовое понимание Python и какой-то опыт в машинном обучении желателен, но не обязателен. Как всегда, я даю ссылки на документацию там, где в объяснениях или приёмах не останавливаюсь на деталях.
Токенизация
Токен — это последовательность символов в документе, имеющая значение для анализа. Обычно это отдельные слова, но не всегда. Документ — это коллекция текста. Им может быть твит, книга или что-то еще. Признаки хороших токенов:
Подсчёт слов
Теперь, когда у нас есть токены, мы можем приступить к самому простому анализу. Подсчитаем количество слов через Counter.
И отобразим на гистограмме:
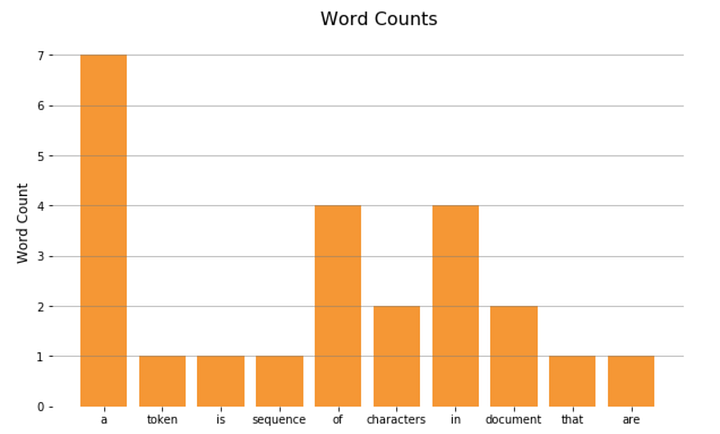
Состав документа
Количество слов может быть полезно, но обычно требуется более глубокий анализ, отвечающий на вопросы бизнеса, особенно когда данные состоят не из одного документа. Мы можем настроить себя на успех, создав Pandas DataFrame, содержащий функции, возвращающие:
Пример: анализ состава документов с DataFrame
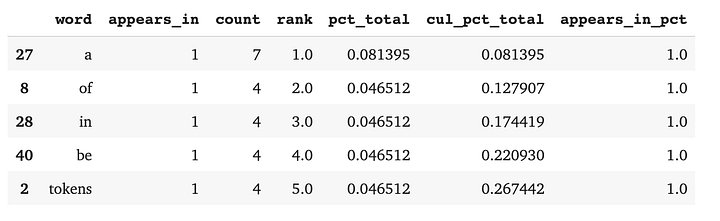
С помощью DataFrame мы видим график функции распределения вероятностей, показывающий, как ранг токена связан с совокупным составом наших документов:
import seaborn as sns
sns.lineplot(x = ‘rank’, y = ‘cul_pct_total’, data = wc)
plt.show();
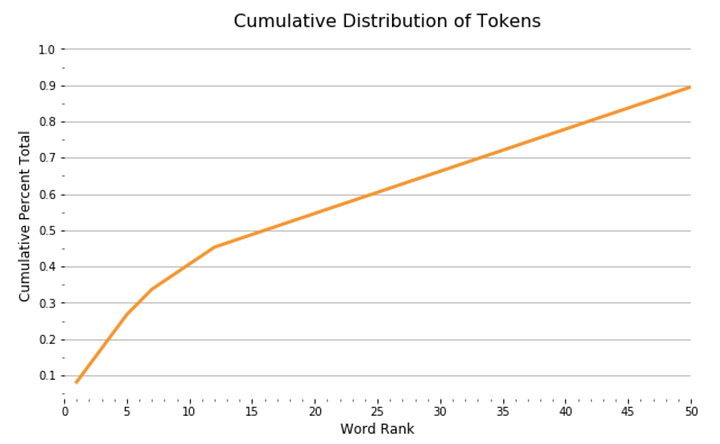
Из графика видно, что 13 наиболее употребимых токенов составляют 45% документа, а после распределение выглядит довольно равномерным. Мы можем увидеть относительный процент этих токенов в составе документа в виде сплошных занимаемых ими участков документа:
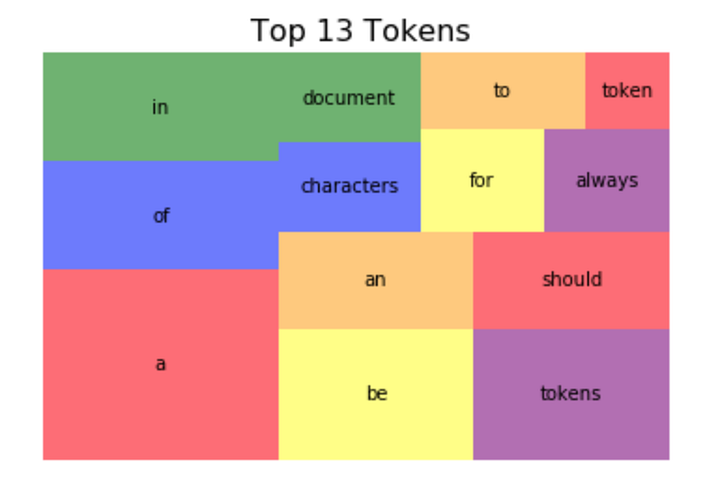
Эти примеры демонстрируют принципы, необходимые для более глубокого понимания мира обработки естественного языка. Токенизация, подсчёт слов и анализ состава документов — основополагающие концепции. Мы могли бы написать целую библиотеку с нуля, но обычно это не самый эффективный способ решения проблем. Существует зоопарк библиотек с открытым кодом, но только одна из них — лидер в области.
Введение в SpaCy
SpaСy — свободная, открытая библиотека Python для решения передовых задач NLP, разработанная Explosion. Она не хранит повторяющиеся компоненты документов в разных структурах данных. Вместо этого SpaСy индексирует компоненты и хранит уточняющую информацию. Поэтому её считают эффективнее в проектах производственного класса, чем библиотеки вроде NLTK. Токены в SpaCy:
Стоп-слова
Слова “I”, “and”, “of” и тому подобные почти не имеют смысловой нагрузки. Мы называем их стоп-словами и в анализ не включаем. Большинство библиотек имеют встроенный список часто используемых английских слов. Союзов, артиклей, наречий, предлогов и общеупотребимых глаголов. Однако лучшая практика — настройка списка под задачу.
Пример удаления стоп-слов:
Леммы
Лемматизация — поиск леммы слова или корневого слова. Говоря простым языком, лемма — это то слово, которое можно найти в словаре. Например, бег, бежит, бегущий, бежал — формы одной и той же лексемы (слова) с леммой “бег”. Пример лемматизации:
Продолжаем серию статей по практическому применению Python. Попробуем решить задачу транскрибации записи речи из аудио в текст. Это не rocket science 🙂 Такие задачи уже решаются продуктами на рынке и довольно неплохо (Сбер, Yandex). Моя цель – не конкурировать, а показать, что такие серьезные задачи можно начать решать с минимальным порогом входа: достаточно базовых знаний в программировании на Python.
Направление естественного анализа речи – целая область в NLP (Natural Language Processing). Дело в том, что компьютер очень быстро считает, но вот с пониманием смысла у него проблемы. Программа может быстро подсчитать количество слов в произведении «Война и мир», но с анализом смысла будут проблемы. А вот NLP пытается докопаться до смыслов.
Прежде чем анализировать речь, ее необходимо перевести в текст, а уже его подвергать анализу. Напрямую анализировать аудио – такого я не встречал (поправьте, если есть реализации, очень интересно посмотреть). В этой статье мы как раз займемся расшифровкой аудио в текст.
Для работы нам понадобится Python 3.8+, библиотека для распознавания речи – Vosk. Немного про библиотеку :
Перевод аудио в текст
Чтобы реализовать транскрибацию из аудио в текст, нам необходимо решить следующие задачи:
Все действия буду делать на машине с Ubuntu 20 (Python 3.8) со следующей конфигурацией:
Причина использования такого количества RAM в том, что мы делаем распознавание на универсальной модели, то есть модели размером 50 Мб, которая требует в разы меньше оперативной памяти в работе, чем полноценная модель. Правда, качество распознавания в этом случае уменьшится.
Создаем директорию speech:
mkdir speech
cd speech
Далее необходимо поставить зависимости для Python:
apt install python3-pip
pip3 install ffmpeg
pip3 install pydub
pip3 install vosk
pip3 install torch
pip3 install transformers
Также скачиваем и распаковываем модель для распознавания русской речи, выполнив команды:
curl -o ./model.zip https://alphacephei.com/vosk/models/vosk-model-ru-0.22.zip
unzip model.zip
mv vosk-model-ru-0.22/ model
rm -rf model.zip
В результате этих действий мы скопировали к себе модель, разархивировали ее и переименовали директорию. Также удалили скачанный архив. Всё-таки он весит 1.5 Гб. Для расстановки пунктуации делаем похожие действия: скачиваем еще одну модель весом 1.5 Гб.
curl -o recasepunc.zip https://alphacephei.com/vosk/models/vosk-recasepunc-ru-0.22.zip
unzip recasepunc.zip
mv vosk-recasepunc-ru-0.22/ recasepunc
rm -rf recasepunc.zip
Код файла app.py, который выполняет перевод аудио в текст.
Последний штрих – разместить файл Song.mp3 в нашей директории с исполняемым файлом app.py. Затем запускаем app.py. В результате наша программа обработает файл .mp3 и на основе натренированных моделей из библиотеки Vosk сделает транскрибацию аудио в текст с сохранением результата в файл data.txt.
Наша реализация решает поставленные задачи в начале статьи. Но это скорее MVP, чем продуманное решение для продакшена. Если мы начнем углубляться, то перед нами встанут задачи обработки больших аудио (от часа и более), организации многопоточности, балансировки и горизонтального масштабирования и много чего интересного. Библиотека VOSK позволяет со всем этим справиться. Но это уже другая история 🙂
Материалы по теме
Анализ тональности текста является важным компонентом анализа настроений и мнений в текстовых данных. SpaCy, хотя и не является специализированной библиотекой для анализа тональности, может быть полезным инструментом для предварительной обработки и анализа текстов перед применением специализированных методов.
Извлечение ключевых слов
Извлечение ключевых слов из текста помогает сжать информацию и выделить самые важные аспекты содержания. SpaCy предоставляет возможность извлекать ключевые слова, используя частоту слов или их семантическое значение.
Автоматическая аннотация текстов
Автоматическая аннотация текстов позволяет автоматически добавлять дополнительные метаданные к текстам. Это может быть полезно, например, при создании информационных ресурсов, где необходимо предоставить пользователям дополнительные сведения о тексте.
SpaCy позволяет не только анализировать тексты, но и добавлять к ним дополнительные метаданные для обогащения контента. Это может быть полезно при создании разнообразных приложений, таких как информационные порталы, поисковые системы и многие другие.
Работа с векторными представлениями
Векторные представления слов — это числовые векторы, представляющие слова в многомерном пространстве таким образом, что семантически близкие слова имеют близкие векторы. Это понятие основано на гипотезе о дистрибутивности, согласно которой слова, используемые в похожих контекстах, имеют схожие значения.
Использование встроенных векторов слов в spaCy
Одной из мощных особенностей spaCy является наличие встроенных векторов слов, которые могут быть использованы для анализа семантической близости и сходства между словами. Эти векторы обучены на больших объемах текста и позволяют сравнивать слова на основе их семантического значения.
import spacy
nlp = spacy.load(«en_core_web_sm»)
# Получаем векторное представление слова «cat»
vector_cat = nlp(«cat»).vector
# Получаем векторное представление слова «dog»
vector_dog = nlp(«dog»).vector
# Вычисляем косинусное расстояние между векторами
similarity = vector_cat.dot(vector_dog) / (vector_cat.norm() * vector_dog.norm())
print(«Similarity between ‘cat’ and ‘dog’:», similarity)
Пользовательские векторы
В некоторых случаях может потребоваться обучить собственные векторные представления слов на специфическом корпусе текстов. Это особенно полезно, если вы работаете с узкоспециализированной терминологией или имеете доступ к большому объему текстов данных.
Применение пользовательских векторов в задачах классификации и кластеризации
Пользовательские векторные представления слов могут быть использованы в различных задачах машинного обучения, таких как классификация и кластеризация. Например, вы можете использовать эти векторы для обучения модели классификации тональности текста или для кластеризации похожих документов.
Векторные представления слов открывают двери к множеству интересных задач. Они позволяют не только анализировать близость слов, но и использовать эту информацию для решения более сложных задач, таких как классификация и кластеризация. Ваша способность создавать и использовать собственные векторы дает вам бескрайний потенциал в области анализа текста.
Синтаксический анализ
Синтаксический анализ, также известный как анализ зависимостей, является важной частью обработки естественного языка. Он фокусируется на выявлении синтаксических отношений между словами в предложении. Для визуализации этих отношений используется дерево зависимостей, которое является графическим представлением структуры предложения.
Использование дерева зависимостей для анализа отношений между словами
Дерево зависимостей позволяет нам легко увидеть, какие слова являются главными, а какие зависимыми, а также какие синтаксические отношения связывают их. В spaCy можно получить дерево зависимостей для предложения с помощью метода .print_tree().
import spacy
nlp = spacy.load(«en_core_web_sm»)
text = «The cat chased the mouse.»
doc = nlp(text)
# Выводим дерево зависимостей
for token in doc:
print(token.text, token.dep_, token.head.text)
Грамматические отношения
Синтаксические отношения определяют, как слова связаны между собой в предложении. Некоторые из ключевых синтаксических отношений включают субъект, объект, прямое дополнение, косвенное дополнение и т.д. Эти отношения помогают нам понимать семантическую структуру предложения.
Примеры использования грамматических отношений для извлечения информации
Грамматические отношения могут быть использованы для извлечения семантической информации из текста. Рассмотрим пример использования грамматических отношений для определения семантической роли слова в предложении.
Синтаксический анализ дает нам обширный инсайт в то, как слова связаны между собой в предложении, и как эти отношения могут повлиять на их значения. Помимо анализа грамматической структуры, дерево зависимостей может быть использовано для выявления более сложных синтаксических конструкций и семантических связей.

В Windows есть виртуальный помощник Cortana, который распознает речь. С помощью Cortana можно создавать напоминания, открывать приложения, отправлять письма, играть в игры, узнавать погоду и т.д.
Siri

Siri это помощник для ОС от Apple: iOS, watchOS, macOS, HomePod и tvOS. Множество функций также работает через голосовое управление: позвонить/написать кому-либо, отправить письмо, установить таймер, сделать фото и т.д.
Gmail
Известный почтовый сервис умеет определять спам, чтобы он не попадал во входящие вашего почтового ящика.
Dialogflow

Платформа от Google, которая позволяет создавать NLP-ботов. Например, можно сделать бота для заказа пиццы, которому не нужен старомодный IVR, чтобы принять ваш заказ.
Python-библиотека NLTK
NLTK (Natural Language Toolkit) – ведущая платформа для создания NLP-программ на Python. У нее есть легкие в использовании интерфейсы для многих языковых корпусов, а также библиотеки для обработки текстов для классификации, токенизации, стемминга, разметки, фильтрации и семантических рассуждений. Ну и еще это бесплатный опенсорсный проект, который развивается с помощью коммьюнити.
Мы будем использовать этот инструмент, чтобы показать основы NLP. Для всех последующих примеров я предполагаю, что NLTK уже импортирован; сделать это можно командой import nltk
В этой статье были разобраны основы NLP для текста, а именно:
Отлично! Теперь, зная основы выделения признаков, вы можете использовать признаки как входные данные для алгоритмов машинного обучения.
Если вы хотите увидеть все описанные концепции в одном большом примере, то вам сюда.
Мы рассмотрели ключевые концепции, начиная от токенизации и разметки частей речи, до анализа синтаксиса и работы с векторными представлениями слов. Благодаря spaCy, мы научились извлекать сущности, анализировать тональность текста и автоматически аннотировать документы. Все, что мы рассмотрели в данной статье, представляет лишь вершину айсберга в мире возможностей, которые предоставляет spaCy. Чтобы полностью овладеть всеми аспектами библиотеки и максимально эффективно применять её в реальных проектах, рекомендуется продолжать изучать документацию, участвовать в сообществе и практиковать на реальных данных.
В заключение рекомендую аналитикам данных посетить открытый урок, посвященный базовому сбору требований. В результате занятия у участников появятся методические материалы по работе с заказчиком в ходе решения задачи по анализу данных. Также преподаватель поделится полезными советами по организации эффективного взаимодействия с заказчиком в бизнес-реалиях. Записаться можно на странице онлайн-курса «Аналитик данных».
Токены, состав документа, стоп-слова, леммы — все они играют свою роль в обработке естественного языка, хотя они довольно просты сами по себе. Мой следующий пост NLP в Python: представления вектора погрузит нас глубже в тему NLP.
Jupyter Notebook на Github
Перевод статьи Matt Kirby: Natural Language Processing with Python
