

- Приложение для прогнозирования COVID-19
- Введение
- Предупреждение
- Что касается термина «руководство»
- Инструментарий
- Разрабатываем решение
- Правильная установка пакетов и отслеживание файлов Jupyter
- Выработка решения задачи
- Загрузка данных
- Подготовка
- Создание классификатора и прогнозирование
- Базовый фронтенд
- Прогнозирование нагрузки
- Обеспечение воспроизводимости с помощью Docker
- Создание Dockerfile
- Развёртываем на AWS
- Настройка zappa
- Настройка AWS
- Учётные данные AWS
- Установим учётные данные с пользователями и правами в IAM
- Добавляем учётные данные в проект
- Развёртывание
- Уменьшаем размер загрузки
- Загружаем модель в корзину S3
- Отладка и обновления
- AWS API Gateway — ограничение доступа
- Настройка Rapidapi
- Описание задачи
- Очистка данных
- Отсутствующие и аномальные данные
- Разведочный анализ данных
- Однопеременные графики
- Поиск взаимосвязей
- Двухпеременные графики
- Конструирование и выбор признаков
- Выбираем базовый уровень
- Заключение
- Начало работы
- Введение в машинное обучение
Приложение для прогнозирования COVID-19
Похоже, коронавирус не спешит уходить из нашей жизни. Но мы можем не только носить маски и мыть руки. Давайте разработаем API на Python и приложение машинного обучения, быстренько напишем алгоритм прогнозирования COVID-19, развернём его и выложим на маркетплейс. Хотите узнать, как это сделать? Читайте дальше это пошаговое руководство.
Введение
В рамках проекта разберём ряд непростых вопросов:
В статье показан процесс разработки API на Python от начала и до конца с разъяснением наиболее сложных частей, например настройки с помощью AWS Lambda.
При работе над проектом я и сам столкнулся с рядом трудностей, которые только помогли мне больше узнать о процессе создания и развёртывания. Кроме того, подобным образом можно создавать и другие проекты и даже попробовать заработать немного денег.
Как видно из содержания, статья состоит из 4 основных частей, а именно:
Весь код открыт на Github:
Итоговый результат можно найти здесь на Rapidapi:
Предупреждение
Я не считаю себя экспертом, поэтому, возможно, в статье будут упущены некоторые моменты. Кроме того, всегда следите за своими расходами на AWS: не платите за то, о чем вы не знаете.
Некоторые разделы предложенного руководства также можно улучшить и развить дальше. Например, часть проекта, связанная с машинным обучением, не слишком проработана, подготовка сыровата, а многие этапы отсутствуют. Но в одной статье всего ведь не распишешь.
Что касается термина «руководство»
Я считаю эту статью пошаговым руководством. Хоть и не эксперт, кое-какими знаниями определённых инструментов могу поделиться. Благодаря этим инструментам пошаговое руководство может помочь создать даже продвинутое приложение.
Понадобятся знания о:
Инструментарий
Тут всегда одно и то же, но всё нужное. Делаем по пунктам:
git remote add origin URL_TO_GIT_REPOgit push -u origin master
Разрабатываем решение
Потребуется Jupyter Notebook, ведь мы разрабатываем приложение машинного обучения.
Правильная установка пакетов и отслеживание файлов Jupyter
Установим Jupyter Notebook и jupytext:
pip install notebook jupytext
Установим хук в git/hooks/pre-commit для правильного отслеживания изменений в git:
touch .git/hooks/pre-commit
code .git/hooks/pre-commit
Скопируем это в файл:
#!/bin/sh
# Для каждого файла ipynb в индексе git добавим представление в Python
jupytext —from ipynb —to py:light —pre-commit
Затем сделаем этот хук исполняемым (на Mac):
chmod +x .git/hooks/pre-commit
Выработка решения задачи
Раз уж пандемическая зараза не торопится уходить, я подумал: почему бы не использовать один из многочисленных наборов данных для выявления случаев заболевания Covid-19? С учётом структуры такого набора данных попробуем спрогнозировать количество новых случаев инфицирования в день по стране.
pip install -r requirements.txt
Этой командой установим все необходимые пакеты. Заглянем в /development/predict_covid.ipynb и узнаем, какие там есть библиотеки.
Самые важные библиотеки:
Для более подробной информации о следующих подзаголовках перейдите, пожалуйста, по ссылке Jupyter Notebook:
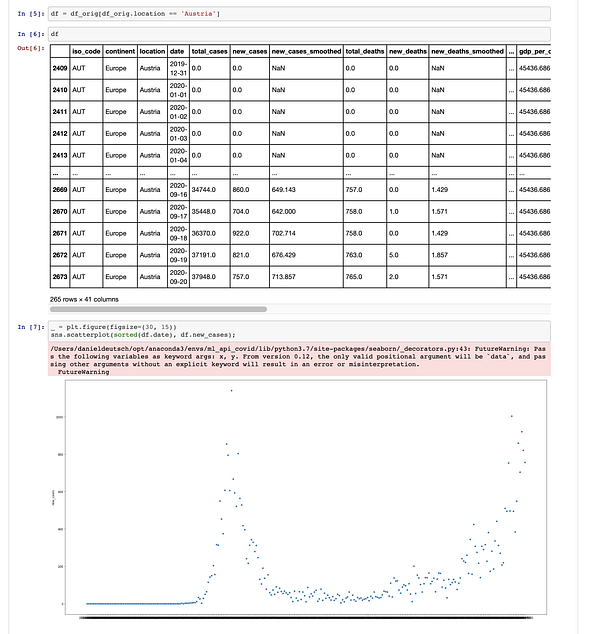
Загрузка данных
Будем использовать набор данных из https://ourworldindata.org/coronavirus-source-data в формате csv.
Подготовка
Если вкратце, вот что я сделал:
Создание классификатора и прогнозирование
Для функциональности API будем использовать сервер Flask (в app.py).
Базовый фронтенд
Который обслуживает базовый файл HTML и CSS:
Прогнозирование нагрузки
Это немного сложнее.
Ключевой маршрут таков:
Но прежде чем мы сможем вернуть результат прогнозирования, нужно получить последние данные и снова подвергнуть их предварительной обработке. Вот как это делается:
В процессе предварительной обработки (pre-process) снова происходит преобразование загруженного набора данных для целей машинного обучения, в то время как get_prediction_params принимает входное значение (страна, по которой делается прогноз) и URL-адрес последнего набора данных.
Всё это делает более точным прогноз для последних данных, но вместе с тем и замедляет приложение.
У вас может возникнуть вопрос: для чего здесь вот это rf = load_model(BUCKET_NAME, MODEL_FILE_NAME, MODEL_LOCAL_PATH)? Чтобы загрузить предварительно обученную модель из корзины AWS S3 и сэкономить память при выполнении всего с помощью AWS Lambda. Подробнее об этом чуть дальше в статье.
Если же развёртывать в облаке не нужно, то можно просто выполнить вот это joblib.load(PATH_TO_YOUR_EXPORTED_MODEL). В notebook экспортируем модель с помощью joblib.dump. Более подробная информация об экспорте моделей содержится в документации sklearn.
Такая она, функциональность сервера FLAK: предоставляет маршрут для обслуживания HTML-шаблона и маршрут для прогнозирования. Очень просто!
env FLASK_APP=app.py FLASK_ENV=development flask run
Обеспечение воспроизводимости с помощью Docker
Возможно, вы захотите масштабировать приложение или упростить его тестирование для других. Для этого можно создать контейнер Docker. Не будем подробно расписывать, как он работает. Если вам интересно, пройдите по одной из ссылок в конце статьи (пункт «Дополнительные ссылки»).
Внимание: это приложение может работать и без контейнера Docker!
Создание Dockerfile
Примечание: последняя строчка предназначена для запуска сервера Flask.
Создав Dockerfile, запустим:
docker build -t YOUR_APP_NAME .
docker run -d -p 80:8080 YOUR_APP_NAME
После чего приложение можно увидеть на http://localhost/.
Развёртываем на AWS
Пока что всё было очень легко. Ничего сложного, ничего особенного. Самое интересное и сложное начнётся сейчас, когда приложение будет развёртываться.
Опять же не будем вдаваться в подробности, остановимся лишь на том, что может вызвать вопросы.
Настройка zappa
Создав приложение локально, приступим к настройке хостинга на реальном сервере. Будем использовать zappa.
Zappa позволяет очень легко создавать и развёртывать бессерверные, событийно-ориентированные приложения на Python (включающие, помимо прочих, веб-приложения стандарта WSGI) на AWS Lambda + API Gateway. Можно считать это «бессерверным» веб-хостингом для приложений на Python. А это бесконечное масштабирование, отсутствие простоев и обслуживания — намного меньше ваших возможных теперешних затрат на развёртывание!
pip install zappa
Мы используем среду conda. Укажем её:
Удалим bin/python/ и экспортируем:
Теперь мы можем ввести следующий код, чтобы настроить конфигурацию.
Проходим всё и получаем вот такой zappa_settings.json:
ВНИМАНИЕ: Не вводите имя для корзины s3, так как она не может быть найдена. Не знаю, в чём проблема с именем корзины s3, у меня так и не получилось с этим разобраться. Несколько раз появлялись ошибки в операторах, и я не смог решить эту проблему. Лучше оставьте то имя, которое есть, и всё будет работать нормально.
Но мы всё ещё не готовы к развёртыванию. Первым делом нужно получить учётные данные AWS.
Настройка AWS
Здесь придётся повозиться. И пусть вас не сбивает с толку сложность AWS и её управление политиками.
Учётные данные AWS
Сначала вам нужно получить access key id (идентификатор ключа доступа) и access key (ключ доступа) AWS.
Установим учётные данные с пользователями и правами в IAM
Разберём здесь всё подробно:
Моя пользовательская политика:
Как видите, я добавил политики, связанные с S3. Ведь предварительно обученную модель придётся загружать из S3. Более подробно об этом чуть дальше.
Добавляем учётные данные в проект
В корневом каталоге создаём папку aws/credentials с помощью:
mkdir ~/.aws
code ~/.aws/credentials
Вставляем свои учётные данные из AWS:
То же самое и с config:
Обратите внимание: для открытия папки code используется vscode, выбранный мной в качестве редактора.
Сохраняем назначенные пользователю идентификатор ключа доступа и секретный ключ доступа AWS, которые были созданы в файле ~/.aws/credentials. Каталог .aws/ должен находиться в вашем домашнем каталоге, а файл учётных данных не имеет расширения.
Развёртывание
Теперь можно развернуть API с помощью команды:
zappa deploy dev
Но при этом следует учитывать, что:
Уменьшаем размер загрузки
Существуют разные мнения о том, как можно уменьшить размер загрузки с zappa. Ознакомиться с ними можно в конце статьи (пункт «Дополнительные ссылки»).
Первым делом нужно уменьшить размер подгружаемого пакета.
Поместим всю исследовательскую часть в отдельную папку с названием development (разработка). Затем можно указать исключённые файлы и папки в zappa_settings.json с помощью exclude:
Можно добавить всё, что не было упаковано для развёртывания.
Дальше надо разобраться с зависимостями среды. В нашем случае имеется несколько зависимостей, которые не нужны для развёртывания. Создаём новый файл requirements_prod.txt. В нём должны быть только те зависимости, которые необходимы в AWS.
Обязательно экспортируем имеющиеся пакеты:
После этого все пакеты удаляем:
pip uninstall -r requirements.txt -y
Устанавливаем новые пакеты для развёртывания и сохраняем их в файле:
Теперь при вводе zappa deploy dev размер пакета должен быть значительно меньше.
Загружаем модель в корзину S3
Теперь нам нужно откуда-то взять модель, которая была исключена из загрузки AWS Lambda. Будем использовать AWS S3 корзину.
В процессе разработки мы пытались загрузить её туда программным образом, но в итоге сделали это вручную: так было просто быстрее. Тем не менее вы можете попробовать загрузить — у меня в репозитории ещё есть закомментированный файл.
Перейдём к https://console.aws.amazon.com/s3/.
Проверяем, есть ли подходящая политика для взаимодействия с корзиной и boto3. Должно получиться что-то вроде этого:
Отладка и обновления
Никаких ошибок больше быть не должно. А если они есть, можно выполнить отладку:
zappa status
# и
zappa tail
Наиболее распространенные ошибки связаны с разрешениями (и тогда проверяем политику разрешений) или с несовместимыми библиотеками Python. В любом случае при отладке в zappa выдаются достаточно понятные сообщения об ошибках. Среди ошибок можно выделить такие:
При обновлении кода не забывайте обновлять также и развёртывание:
zappa update dev
AWS API Gateway — ограничение доступа
Прежде чем выводить API на рынок (маркетплейс), сначала нужно ограничить его использование API-ключом.
Теперь доступ к API ограничен.
Настройка Rapidapi
Открытый исходный код: https://github.com/Createdd/ml_api_covid.
На Rapidapi: https://rapidapi.com/Createdd/api/covid_new_cases_prediction.
Читайте нас в Telegram, VK и Яндекс. Дзен
Перевод статьи Daniel Deutsch: Develop and sell a Machine Learning app — from start to end tutorial
Время на прочтение

Перевод A Complete Machine Learning Project Walk-Through in Python: Part One.
Когда читаешь книгу или слушаешь учебный курс про анализ данных, нередко возникает чувство, что перед тобой какие-то отдельные части картины, которые никак не складываются воедино. Вас может пугать перспектива сделать следующий шаг и целиком решить какую-то задачу с помощью машинного обучения, но с помощью этой серии статей вы обретёте уверенность в способности решить любую задачу в сфере data science.
Чтобы у вас в голове наконец сложилась цельная картина, мы предлагаем разобрать от начала до конца проект применения машинного обучения с использованием реальных данных.
Последовательно пройдём через этапы:
Вы узнаете, как этапы переходят один в другой и как реализовать их на Python. Весь проект доступен на GitHub, первая часть лежит здесь. В этой статье мы рассмотрим первые три этапа.
Описание задачи
Прежде чем писать код, необходимо разобраться в решаемой задаче и доступных данных. В этом проекте мы будем работать с выложенными в общий доступ данными об энергоэффективности зданий в Нью-Йорке.
Наша цель: использовать имеющиеся данные для построения модели, которая прогнозирует количество баллов Energy Star Score для конкретного здания, и интерпретировать результаты для поиска факторов, влияющих на итоговый балл.
Данные уже включают в себя присвоенные баллы Energy Star Score, поэтому наша задача представляет собой машинное обучение с управляемой регрессией:
Наша модель должна быть точная — чтобы могла прогнозировать значение Energy Star Score близко к истинному, — и интерпретируемая — чтобы мы могли понять её прогнозы. Зная целевые данные, мы можем использовать их при принятии решений по мере углубления в данные и создания модели.
Очистка данных
Далеко не каждый набор данных представляет собой идеально подобранное множество наблюдений, без аномалий и пропущенных значений (намек на датасеты mtcars и iris). В реальных данных мало порядка, так что прежде чем приступить к анализу, их нужно очистить и привести к приемлемому формату. Очистка данных — неприятная, но обязательная процедура при решении большинства задач по анализу данных.
Сначала можно загрузить данные в виде кадра данных (dataframe) Pandas и изучить их:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv(‘data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv’)
# Display top of dataframe
data.head()
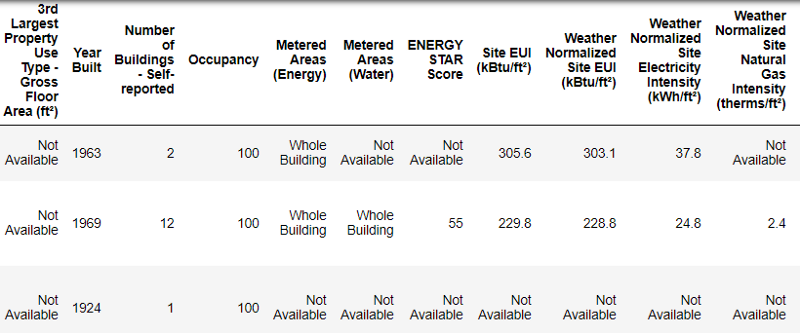
Так выглядят реальные данные.
Это фрагмент таблицы из 60 колонок. Даже здесь видно несколько проблем: нам нужно прогнозировать Energy Star Score, но мы не знаем, что означают все эти колонки. Хотя это не обязательно является проблемой, потому что зачастую можно создать точную модель, вообще ничего не зная о переменных. Но нам важна интерпретируемость, поэтому нужно выяснить значение как минимум нескольких колонок.
Когда мы получили эти данные, то не стали спрашивать о значениях, а посмотрели на название файла:
и решили поискать по запросу «Local Law 84». Мы нашли эту страницу, на которой говорилось, что речь идёт о действующем в Нью-Йорке законе, согласно которому владельцы всех зданий определённого размера должны отчитываться о потреблении энергии. Дальнейший поиск помог найти все значения колонок. Так что не пренебрегайте именами файлов, они могут быть хорошей отправной точкой. К тому же это напоминание, чтобы вы не торопились и не упустили что-нибудь важное!
Мы не будем изучать все колонки, но точно разберёмся с Energy Star Score, которая описывается так:
Ранжирование по перцентили от 1 до 100, которая рассчитывается на основе самостоятельно заполняемых владельцами зданий отчётов об энергопотреблении за год. Energy Star Score — это относительный показатель, используемый для сравнения энергоэффективности зданий.
Первая проблема решилась, но осталась вторая — отсутствующие значения, помеченные как «Not Available». Это строковое значение в Python, которое означает, что даже строки с числами будут храниться как типы данных object, потому что если в колонке есть какая-нибудь строковая, Pandas конвертирует её в колонку, полностью состоящую из строковых. Типы данных колонок можно узнать с помощью метода dataframe.info():
# See the column data types and non-missing values
data.info()
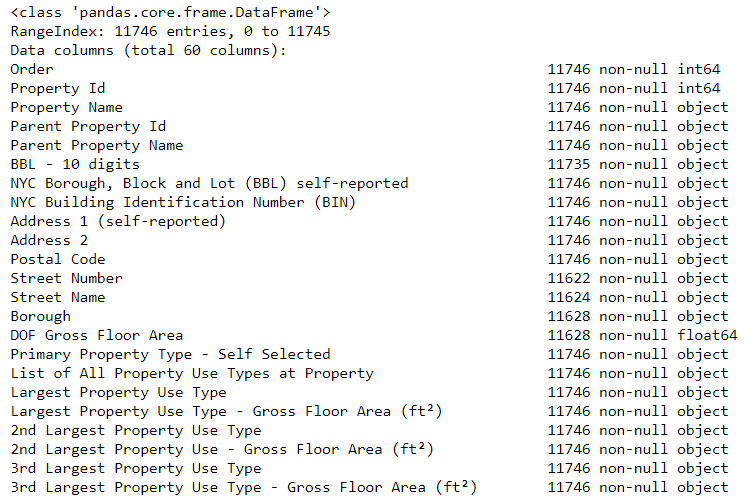
Наверняка некоторые колонки, которые явно содержат числа (например, ft²), сохранены как объекты. Мы не можем применять числовой анализ к строковым значениям, так что конвертируем их в числовые типы данных (особенно float)!
Этот код сначала заменяет все «Not Available» на not a number (np.nan), которые можно интерпретировать как числа, а затем конвертирует содержимое определённых колонок в тип float:
Когда значения в соответствующих колонках у нас станут числами, можно начинать исследовать данные.
Отсутствующие и аномальные данные
Наряду с некорректными типами данных одна из самых частых проблем — отсутствующие значения. Они могут отсутствовать по разным причинам, и перед обучением модели эти значения нужно либо заполнить, либо удалить. Сначала давайте выясним, сколько у нас не хватает значений в каждой колонке (код здесь).
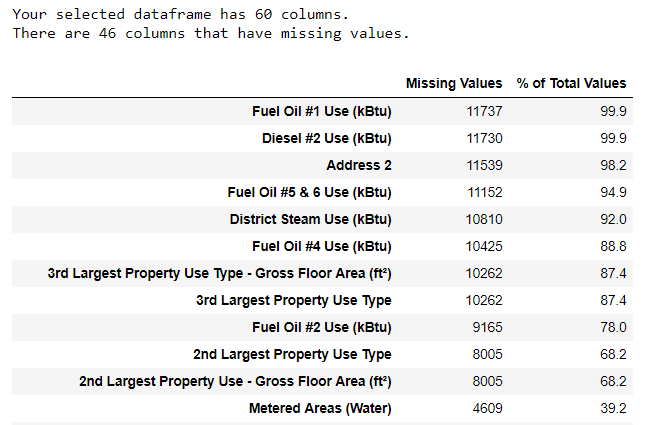
Для создания таблицы использована функция из ветки на StackOverflow.
Убирать информацию всегда нужно с осторожностью, и если много значений в колонке отсутствует, то она, вероятно, не пойдёт на пользу нашей модели. Порог, после которого колонки лучше выкидывать, зависит от вашей задачи (вот обсуждение), а в нашем проекте мы будем удалять колонки, пустые более чем на половину.
Также на этом этапе лучше удалить аномальные значения. Они могут возникать из-за опечаток при вводе данных или из-за ошибок в единицах измерений, либо это могут быть корректные, но экстремальные значения. В данном случае мы удалим «лишние» значения, руководствуясь определением экстремальных аномалий:
Код, удаляющий колонки и аномалии, приведён в блокноте на Github. По завершении процесса очистки данных и удаления аномалий у нас осталось больше 11 000 зданий и 49 признаков.
Разведочный анализ данных
Коротко говоря, РАД — это попытка выяснить, что нам могут сказать данные. Обычно анализ начинается с поверхностного обзора, затем мы находим интересные фрагменты и анализируем их подробнее. Выводы могут быть интересными сами по себе, или они могут способствовать выбору модели, помогая решить, какие признаки мы будем использовать.
Однопеременные графики
Наша цель — прогнозировать значение Energy Star Score (в наших данных переименовано в score), так что имеет смысл начать с исследования распределения этой переменной. Гистограмма — простой, но эффективный способ визуализации распределения одиночной переменной, и её можно легко построить с помощью matplotlib.
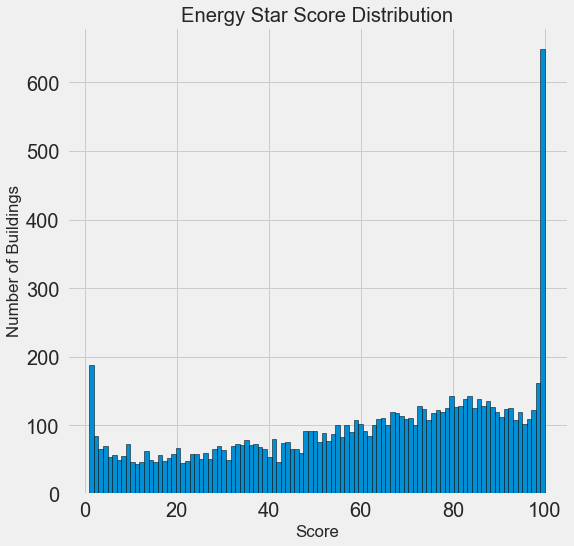
Выглядит подозрительно! Балл Energy Star Score является процентилем, значит следует ожидать единообразного распределения, когда каждый балл присваивается одному и тому же количеству зданий. Однако высший и низший результаты получило непропорционально большое количество зданий (для Energy Star Score чем больше, тем лучше).
Если мы снова посмотрим на определение этого балла, то увидим, что он рассчитывается на основе «самостоятельно заполняемых владельцами зданий отчётов», что может объяснить избыток очень больших значений. Просить владельцев зданий сообщать о своём энергопотреблении, это как просить студентов сообщать о своих оценках на экзаменах. Так что это, пожалуй, не самый объективный критерий оценки энергоэффективности недвижимости.
Если бы у нас был неограниченный запас времени, то можно было бы выяснить, почему так много зданий получили очень высокие и очень низкие баллы. Для этого нам пришлось бы выбрать соответствующие здания и внимательно их проанализировать. Но нам нужно только научиться прогнозировать баллы, а не разработать более точный метод оценки. Можно пометить себе, что у баллов подозрительное распределение, но мы сосредоточимся на прогнозировании.
Поиск взаимосвязей
Главная часть РАД — поиск взаимосвязей между признаками и нашей целью. Коррелирующие с ней переменные полезны для использования в модели, потому что их можно применять для прогнозирования. Один из способов изучения влияния категориальной переменной (которая принимает только ограниченный набор значений) на цель — это построить график плотности с помощью библиотеки Seaborn.
График плотности можно считать сглаженной гистограммой, потому что он показывает распределение одиночной переменной. Можно раскрасить отдельные классы на графике, чтобы посмотреть, как категориальная переменная меняет распределение. Этот код строит график плотности Energy Star Score, раскрашенный в зависимости от типа здания (для списка зданий с более чем 100 измерениями):
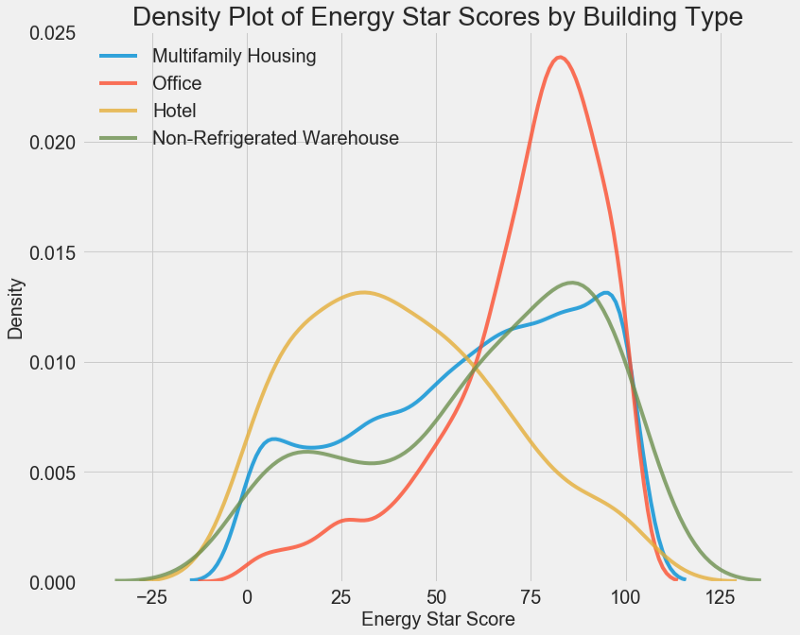
Как видите, тип здания сильно влияет на количество баллов. Офисные здания обычно имеют более высокий балл, а отели более низкий. Значит нужно включить тип здания в модель, потому что этот признак влияет на нашу цель. В качестве категориальной переменной мы должны выполнить one-hot кодирование типа здания.
Аналогичный график можно использовать для оценки Energy Star Score по районам города:
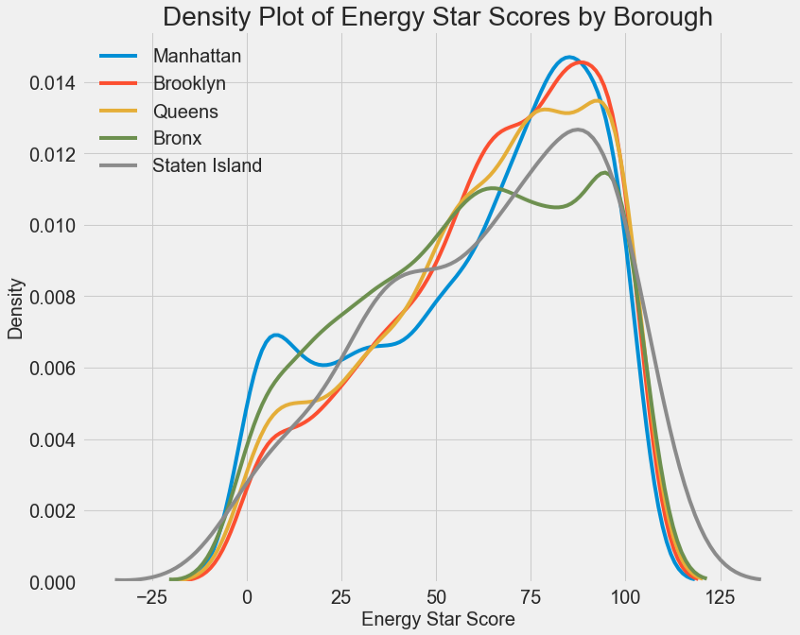
Район не так сильно влияет на балл, как тип здания. Тем не менее мы включим его в модель, потому что между районами существует небольшая разница.
Чтобы посчитать взаимосвязи между переменными, можно использовать коэффициент корреляции Пирсона. Это мера интенсивности и направления линейной зависимости между двумя переменными. Значение +1 означает идеально линейную положительную зависимость, а -1 означает идеально линейную отрицательную зависимость. Вот несколько примеров значений коэффициента корреляции Пирсона:

Хотя этот коэффициент не может отражать нелинейные зависимости, с него можно начать оценку взаимосвязей переменных. В Pandas можно легко вычислить корреляции между любыми колонками в кадре данных (dataframe):
Самые отрицательные корреляции с целью:

и самые положительные:

Есть несколько сильных отрицательных корреляций между признаками и целью, причём наибольшие из них относятся к разным категориям EUI (способы расчёта этих показателей слегка различаются). E UI (Energy Use Intensity, интенсивность использования энергии) — это количество энергии, потреблённой зданием, делённое на квадратный фут площади. Эта удельная величина используется для оценки энергоэффективности, и чем она меньше, тем лучше. Логика подсказывает, что эти корреляции оправданны: если EUI увеличивается, то Energy Star Score должен снижаться.
Двухпеременные графики
Воспользуемся диаграммами рассеивания для визуализации взаимосвязей между двумя непрерывными переменными. К цветам точек можно добавить дополнительную информацию, например, категориальную переменную. Ниже показана взаимосвязь Energy Star Score и EUI, цветом обозначены разные типы зданий:
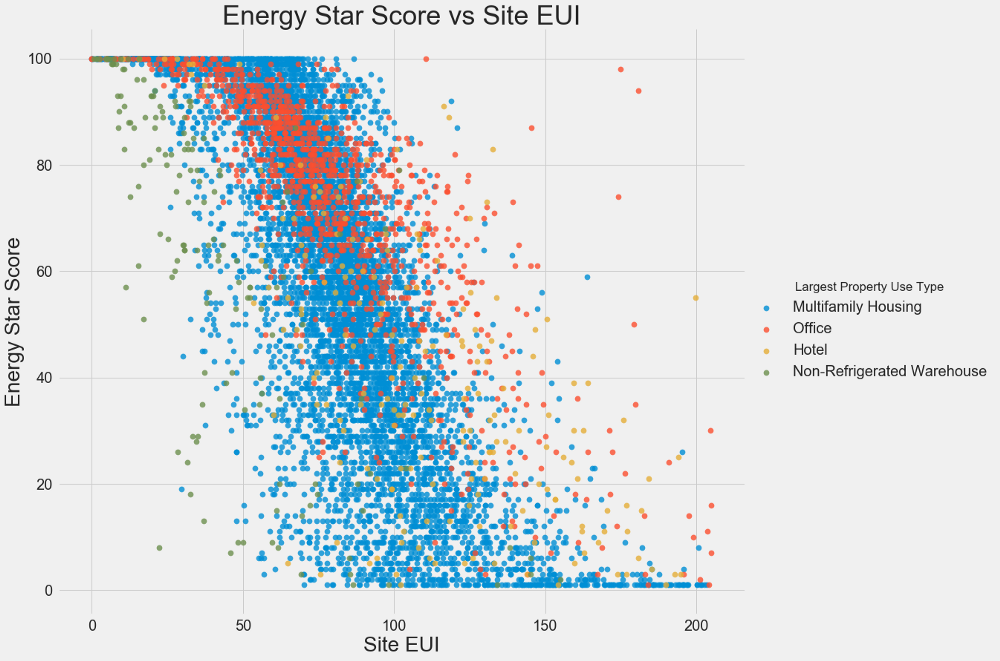
Этот график позволяет визуализировать коэффициент корреляции -0,7. По мере уменьшения EUI увеличивается Energy Star Score, эта взаимосвязь наблюдается у зданий разных типов.
Наш последний исследовательский график называется Pairs Plot (парный график). Это прекрасный инструмент, позволяющий увидеть взаимосвязи между различными парами переменных и распределение одиночных переменных. Мы воспользуемся библиотекой Seaborn и функцией PairGrid для создания парного графика с диаграммой рассеивания в верхнем треугольнике, с гистограммой по диагонали, двухмерной диаграммой плотности ядра и коэффициентов корреляции в нижнем треугольнике.
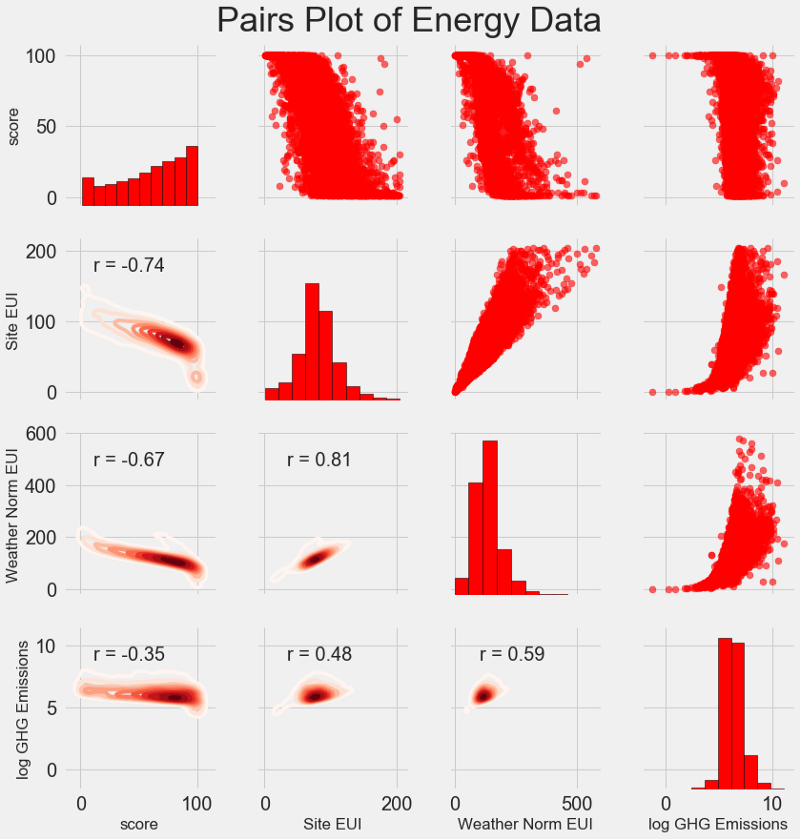
Чтобы увидеть взаимосвязи переменных, поищем пересечения рядов и колонок. Допустим, нужно посмотреть корреляцию Weather Norm EUI и score, тогда мы ищем ряд Weather Norm EUI и колонку score, на пересечении которых стоит коэффициент корреляции -0,67. Эти графики не только классно выглядят, но и помогают выбрать переменные для модели.
Конструирование и выбор признаков
Конструирование и выбор признаков зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
One-hot кодирование необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
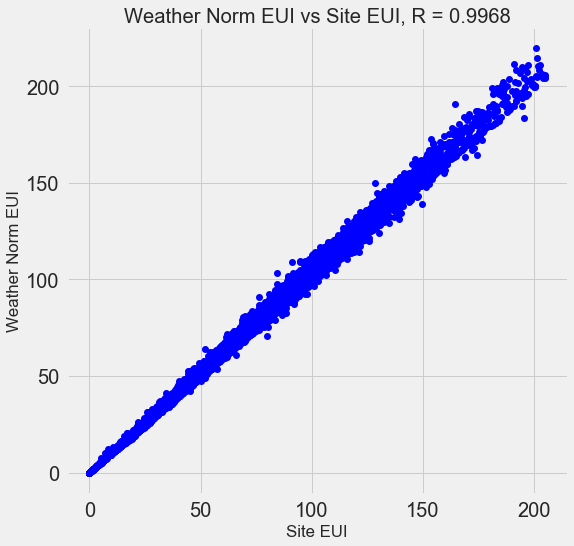
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии (variance inflation factor). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Выбираем базовый уровень
Для регрессионных задач в качестве базового уровня разумно угадывать медианное значение цели на обучающем наборе для всех примеров в тестовом наборе. Эти наборы задают барьер, относительно низкий для любой модели.
В качестве метрики возьмём среднюю абсолютную ошибку (mae) в прогнозах. Для регрессий есть много других метрик, но мне нравится совет выбирать какую-то одну метрику и с её помощью оценивать модели. А среднюю абсолютную ошибку легко вычислить и интерпретировать.
Прежде чем вычислять базовый уровень, нужно разбить данные на обучающий и тестовый наборы:
Для обучения используем 70 % данных, а для тестирования — 30 %:
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)
Теперь вычислим показатель для исходного базового уровня:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true — y_pred))
baseline_guess = np.median(y)
print(‘The baseline guess is a score of %0.2f’ % baseline_guess)
print(«Baseline Performance on the test set: MAE = %0.4f» % mae(y_test, baseline_guess))
The baseline guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164
Средняя абсолютная ошибка на тестовом наборе составила около 25 пунктов. Поскольку мы оцениваем в диапазоне от 1 до 100, то ошибка составляет 25 % — довольно низкий барьер для модели!
Заключение
Вы этой статье мы прошли через три первых этапа решения задачи с помощью машинного обучения. После постановки задачи мы:
Наконец, мы вычислили базовый уровень, с помощью которого будем оценивать наши алгоритмы.
В следующей статье мы научимся с помощью Scikit-Learn оценивать модели машинного обучения, выбирать лучшую модель и выполнять её гиперпараметрическую настройку.
Руководство написано для тех, кто раннее не был знаком с машинным обучением. Это введение в машинное обучение на основе написания алгоритма, который будет предсказывать, сколько человек выживет при крушении «Титаника». Предполагается, что вы уже имеете опыт работы с Python и что вы знакомы с Pandas на базовом уровне.
Начало работы
Многие другие руководства по машинному обучению рассчитаны на то, что ученик уже является кандидатом наук в области математики или статистики. Настоящее руководство написано для тех, кто раннее не был знаком с машинным обучением.
Формат работы: вы начнёте с введения в машинное обучение на основе написания алгоритма, который будет предсказывать, сколько человек выживет при крушении «Титаника». Затем последуют две тренировочные сессии. Руководство будет направлять вас в дальнейшей работе, но код вы должны будете писать самостоятельно.
Требуемые знания: предполагается, что вы уже имеете опыт работы с Python или знаете его на уровне выше базового. Также предполагается, что вы знакомы с Pandas на базовом уровне. Если вы желаете подтянуть знания по Pandas, предлагаем ознакомиться со специальной статьёй. Также предлагаем вам посмотреть курс по основам Pandas.
Разработка будет выполняться с использованием Ipython (если вы раньше не работали с этой оболочкой, можете посмотреть вводный видеоурок и ознакомиться с командной оболочкой для интерактивных вычислений Jupyter Notebook в нашей статье). По определённым причинам рекомендуется использовать пакет Anaconda с Python 3.
Введение в машинное обучение
Презентация к уроку
В презентации вам дано небольшое задание на проверку логики (чем чаще вы будете уделять время на подобные упражнения, тем лучше вы сможете организовать рабочий процесс). Следует открыть файл titanic_train.csv и определить, какие поля, на ваш взгляд, имеют наибольшее значение для обучения. Вы можете сделать это сейчас, чтобы в середине статьи сравнить свой результат и результат автора.