
Автор этого материала — программист и ML-инженер — собрала Open Source библиотеки Python, которые помогут вам сделать данные лучше, чтобы избежать траты времени и упростить анализ данных. Подборкой делимся к старту курса по анализу данных
.
- Профилирование и оценка
- Разведочный анализ данных
- 1. Pandas Profiling
- 2. Great Expectations
- 3. SodaSQL
- Прогнозная аналитика
- 4. Ydata
- 5. DeepChecks
- 6. Evidently AI
- 7. Alibi Detect
- Очистка и форматирование данных
- 1. Scrabadub
- 2. Arrow
- 3. Beautifier
- 4. Ftfy
- 5. Dora
- 6. DataCleaner
- Предварительный просмотр таблиц
- 1. Tabulate
- 2. PrettyPandas
- Используемые языки
- Песочница дата-сайентиста
- Среда разработки и другие программы
- Библиотеки анализа данных
- Машинное обучение
- Работа с данными
- Автоматизация процессов
- DevOps и другие полезные практики
- Библиотеки для форматирования и очистки данных
- Dora
- Datacleaner
- PrettyPandas
- Tabulate
- Scrubadub
- Arrow
- Beautifier
- Ftfy
- Библиотеки для визуализации данных
- Matplotlib
- Seaborn
- Ggplot
- Bokeh
- Pygal
- Plotly
- Geoplotlib
- Gleam
- Missingno
- Leather
- Обзор Data Science
- Почему Python используется в сфере Data Science?
- ▍Для решения сложных задач требуется писать сравнительно небольшие объёмы кода
- Python-пакеты для Data Science
Профилирование и оценка
Разведочный анализ данных
1. Pandas Profiling
Pandas Profiling
генерирует отчёт о профилировании фреймов данных Pandas.
Профилирование данных: недостающие и уникальные значения и т. д.
Распределения данных и гистограммы.
Квантильная и описательная статистика: среднее значение, стандартное отклонение, Q1 и т. д.
Выведение типа данных.
Взаимодействия и корреляции данных.
Создание отчёта в HTML.
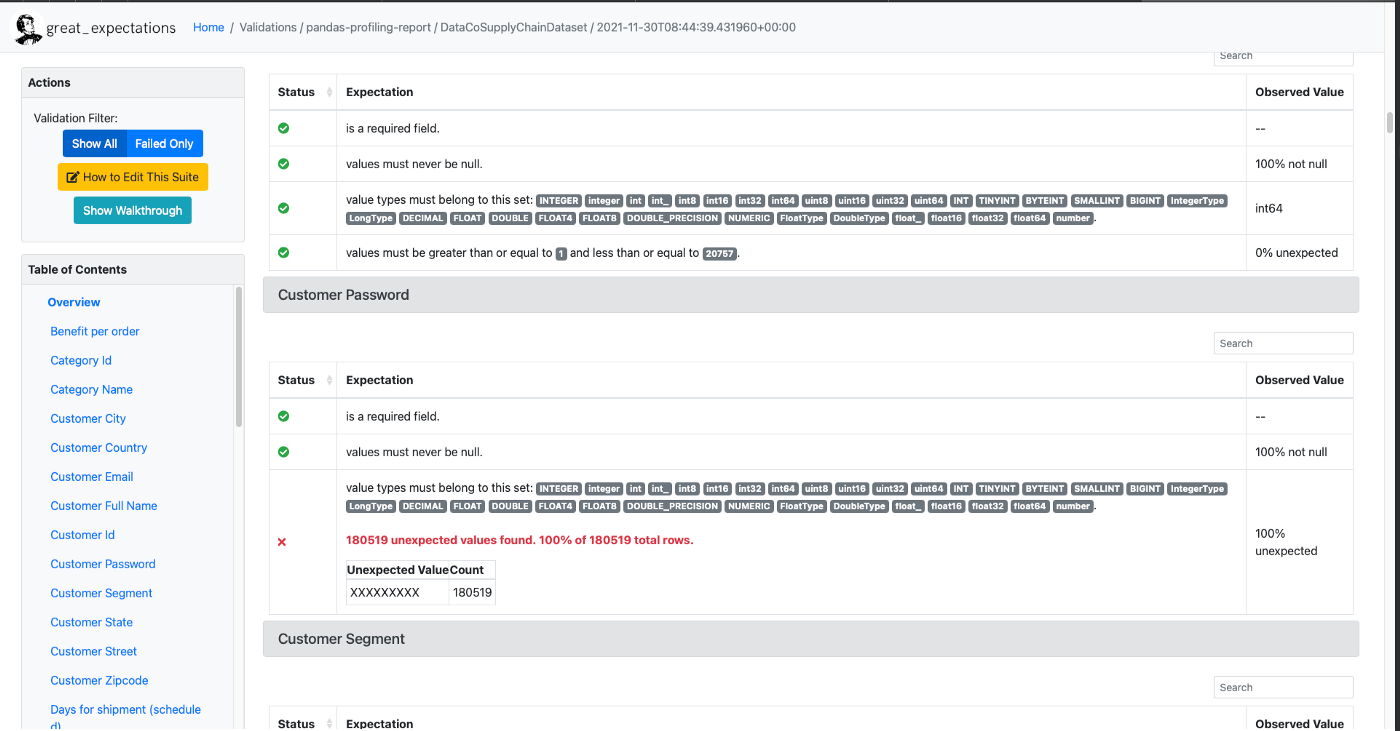
2. Great Expectations
Great Expectations
основана на ассертах данных из библиотеки Expectation.
Это общедоступный, открытый стандарт качества данных, помогающий командам Data Science устранять недоработки конвейера данных, выполняя их тестирование, документирование и профилирование.
Декларативные тесты данных на:
ожидаемое количество строк в таблице — от x до y;
ожидаемое число недостающих значений не превысит 20%;
ожидаемый формат даты в столбцах — MM-DD-YYYY;
дополнительные конструкции «из коробки»: уникальность, отклоняющиеся значения и другие
характеристики данных;
Автоматическое профилирование данных.
Визуализация тестов в удобных для человека формах и документах.
Интеграция со многими инструментами и системами: Pandas, Jupyter Notebook, Spark, mysql, databricks и т. д.;

3. SodaSQL
SodaSQL
— это инструмент командной строки, выполняющий SQL-запросы на основе входных данных. Вот что он делает:
Запускает тесты на разных наборах данных в разных источниках данных: Snowflake, PostgreSQL, Athena, и т. д., ищет недопустимые или недостающие данные.
Собирает метрики: минимальные, максимальные и средние значения, стандартное отклонение и многие другие метрики.
Пользовательские тесты на SQL.
Определение тестов для каждой таблицы в формате yml.
Интеграция с инструментом оркестрации данных.
Подключение и сканирование наборов данных.
Определение формата столбцов: электронная почта, дата, номера телефонов и т. д.
Сохранение результатов сканирования в JSON.
Прогнозная аналитика
4. Ydata
Ydata
оценивает качество данных конвейера данных на разных этапах его разработки. Она помогает составить целостное представление о данных, рассматривая их с разных точек зрения на предмет:
отклоняющихся значений и дрейфа данных;
отношений данных и корреляции данных.
Библиотека интегрируется с Great Expectations
, в которой запускаются ассерты данных, позволяющие проверять, профилировать данные и автоматически генерировать отчёты:
5. DeepChecks
DeepChecks
— это пакет Python, позволяющий легко проверять модели ML и связанные с различными задачами данные, например производительность модели; также DeepChecks обнаруживает:
специальные символы и т. д.;
Библиотека сравнивает строки, обнаруживает их несоответствия. Она видит следующие характеристики данных:
смещения в распределении;
Целостность данных и обнаружение смещения пригодятся при тестировании данных.
Работая с данными для обучения модели, тестовыми данными и текущими фреймами данных, можно воспользоваться набором тестов SingleDatasetIntegrity или специальными тестами из других наборов.
В DeepChecks можно писать свои тесты и их наборы, красиво отображая результаты в таблице или на графике Plotly:
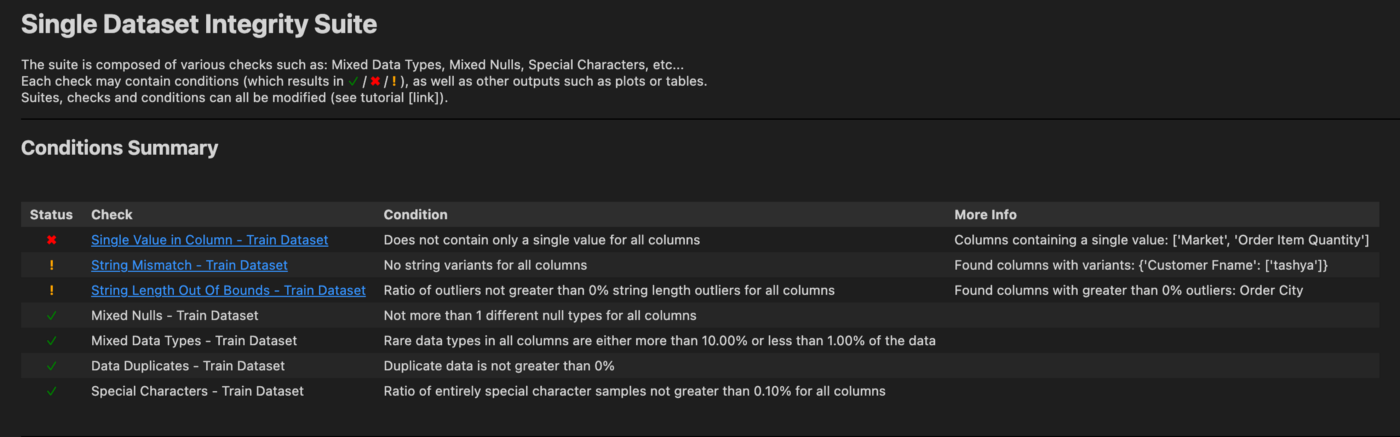

6. Evidently AI
Evidently AI
— это инструмент для анализа и наблюдения за моделями ML.
Evidently AI интегрируется с Grafana и Prometheus, можно создать пользовательский дашборд.

7. Alibi Detect
Alibi Detect
— специализированная библиотека ML для обнаружения отклоняющихся значений (выбросов), состязательности и дрейфа данных.
Обнаружение дрейфа и отклоняющихся значений в табличных данных, тексте, изображениях и временных рядах.
Обнаружение с предварительно тренированным и нетренированным детектором.
Поддержка бэкендов TensorFlow и PyTorch для обнаружения дрейфа.
Очистка и форматирование данных
1. Scrabadub
Scrabadub
— это инструмент выявляет и удаляет из любого текста личную информацию: имена, номера телефонов, адреса, номера кредитных карт и т. д. Можно реализовать собственные средства обнаружения данных:
text = "My cat can be contacted on [email protected], or 1800 555-5555" scrubadub.clean(text)
>>'My cat can be contacted on {{EMAIL}}, or {{PHONE}}'
2. Arrow
В Arrow
реализован разумный, удобный подход к созданию, обработке, форматированию и преобразованию дат, времени и временных меток:
utc = arrow.utcnow()
time= utc.to('US/Pacific')
past = time.dehumanize("2 days ago")
print(past)
>> 2022-01-09T10:11:11.939887+00:00
print(past.humanize(locale="ar"))
>> 'منذ يومين'
3. Beautifier
Beautifier
— библиотека для очистки шаблонов URL и адресов электронной почты. Она позволяет:
Проверить корректность электронного адреса.
Анализировать электронные письма по домену и имени пользователя.
Анализировать URL по доменам и параметрам.
Очистить URL от символов Unicode, специальных символов и ненужных шаблонов перенаправления.
4. Ftfy
Ftfy
расшифровывается как Fixes text for you («Исправляет текст для вас»). Вот её функции:
Исправление текста с неподходящими
для языков разметки символами Unicode.Удаление разрывов строк.
Преобразование HTML-сущностей в обычный текст.
Выявление текста с вероятностью искажения из-за неверной кодировки.
Объяснения того, что произошло с текстом.
ftfy.fix_text('The Mona Lisa doesn’t have eyebrows.')
>>"The Mona Lisa doesn't have eyebrows."
5. Dora
Dora
— это инструментарий разведочного анализа данных для Python.
Очистка данных от «null», преобразование из категориальных данных в порядковые данные, преобразование данных в столбцах и удаление столбцов.
Выделение и извлечение признаков.
Отображение признаков на графике.
Разделение данных для валидации модели.
Преобразования данных с их версионированием.
Для работы многих функций, включая графики, данные должны быть числовыми.
6. DataCleaner
Data Cleaner
автоматически очищает наборы данных и подготавливает их к анализу.
Удаление строк с пропущенными значениями.
Замена отсутствующих значений.
Кодирование нечисловых переменных.
Работа с фреймами данных Pandas.
Работа в скриптах и в командной строке.
Предварительный просмотр таблиц
1. Tabulate
Вызов одной функции Tabulate
выводит небольшие, красивые таблицы.
Удобные для восприятия таблицы.
Форматирование таблиц в HTML и других форматах.

2. PrettyPandas
PrettyPandas
— инструмент с простым API, генерирующий достойные табличные отчёты. Они хорошо воспринимаются благодаря:
добавлению итоговых строк и столбцов;
форматированию чисел валют и процентов.

На сегодня всё. Попробовать все эти инструменты в деле вы сможете на наших курсах. А мы поможем вам прокачать навыки или с самого начала освоить профессию в IT, востребованную в любое время:
Выбрать другую востребованную профессию
.

Краткий каталог курсов и профессий
Подборка инструментов для работы специалиста по Data Science: от самых простых и повседневных до более специфических и редких
Используемые языки
Основным языком программирования для дата-сайентиста является Python. Это наиболее широко распространенный язык в области data science, он применяется для анализа данных, написания рабочего кода, создания моделей, проведения экспериментов и др. Также встречается анализ данных на R: этот язык чаще используется для статистических исследований, в эконометрике. Для работы с данными также нужен язык запросов SQL, на нем пишут запросы к источникам данных и получают результат в нужном формате. Если дата-сайентист разрабатывает ML модели на низком уровне, т.е. он, если быть точным, ML Engineer, — то он будет писать на С++.
Песочница дата-сайентиста
В качестве «песочницы» используют Jupyter Notebook. Это интерактивная веб- оболочка для экспериментов и разведочного анализа данных, в рамках которой дата-сайентист смотрит, что из себя представляют данные, с которыми он работает, какие в них закономерности, аномалии, какие величины есть в данных, как они распределены, строит гистограммы и другие графики, позволяющие наглядно визуализировать данные.
Помимо разведочного анализа, в Jupyter Notebook удобно отлаживать различные части кода, методы, классы, а также это подходящий формат, чтобы создавать сводки по аналитике, потому что помимо кода и отрисовывания графиков и картинок, там можно использовать форматирование markdown, в котором поддерживается синтаксис LaTex для отображения формул, систем уравнений, выражений со сложными индексами. Обобщая, можно сказать, что Jupyter Notebook является «рабочим столом» дата-сайентиста.
Среда разработки и другие программы
Код проекта, который будет использоваться в продакшене, нужно писать в полноценной среде разработки. Одна из самых часто используемых сред — это PyCharm IDE. В ней удобно писать код на Python, реализовывать модули, классы, настраивать и использовать интерпретаторы для Python, работать с Git, делать умный рефакторинг, следить за чистотой кода с помощью подсказок и помощи в форматировании. Расширенная версия PyCharm также позволяет настраивать удаленный интерпретатор, работать с базами данных и с теми же Jupyter-ноутбуками прямо внутри IDE. Есть, конечно, и другие IDE, в которых можно писать на Python: VS Code, Spider, PyDev и др.
При продуктивизации решения применяют CI/CD практики (Continuous Integration / Continuous Delivery) и часто встречающийся GitLab — продукт для хранения кода и совместной разработки больших программных проектов. В этом контексте дата-сайентист близок по инструментам к Python-разработчику.
Из программных инструментов в работе дата-сайентиста также стоит упомянуть и очевидный MS Excel, который является общепонятным форматом и в нем можно что-то быстро и наглядно показать бизнесу.
Помимо этого в работе дата-сайентиста можно встретить инструменты визуализации, например, Tableau (для построения различных бордов и отчетов), SAS (готовое решение по анализу данных) и другие более специфичные вещи, редко встречающиеся в работе и являющиеся скорее исключением, чем правилом, так как это больше про BI и продуктовую аналитику.
Библиотеки анализа данных
Что касается разведочного анализа данных, или же EDA (Exploratory Data Analysis), в Jupyter Notebook для построения графиков используют Matpotlib, Seaborn, Plotly. Обычно этих библиотек хватает, чтобы строить красивые и наглядные визуализации, исследовать зависимости в данных, видеть в данных их физическую сущность. Если говорить про язык R, то там используется библиотека ggplot2 для визуализации.
Помимо этого популярна библиотека scikit-learn. В ней реализовано множество полезных функций, несложных моделей машинного обучения, вспомогательные инструменты, в том числе и для визуализации, подсчет различных статистик.
Для работы с массивами данных используют Pandas. С помощью этой библиотеки можно работать с данными разных форматов, представлять их в виде удобного дата-фрейма, производить операции, рассчитывать статистики, применять функции к колонкам и пр. Также есть библиотека Numpy: с ней удобно оперировать матрицами, векторами, выполнять преобразования из линейной алгебры. Библиотека SciPy содержит дополнительные математические операции: методы оптимизации, преобразования сигналов, интегралы, разреженные матрицы и др.
Машинное обучение
Если говорить про машинное обучение и создание моделей, частично простые модели уже есть в scikit-learn, помимо этого есть отдельные библиотеки для создания чуть более сложных моделей-ансамблей, например, XGBoost, CatBoost и LightGBM. Это библиотеки с бустинговыми алгоритмами, которые можно применять для задач регрессии, классификации. Для интерпретации работы модели есть библиотеки SHAP и DiCE. Если нужно работать с текстами, то стоит упомянуть библиотеку NLTK, если же с нейросетями, то это TensorFlow, PyTorch, Keras. С помощью этих фреймворков создаются нейронные сети для самых разных задач: сегментация, детекция, распознавание, speech-to-text, генерация речи и др.
Работа с данными
Дата-сайентист может тратить на работу с данными до 80 процентов своего времени, и только остальные 20 процентов уходят на запуск и настройку модели, оценку результатов. Основная работа связана со сбором данных, их преобразованием, очисткой, написанием пайплайнов. В первую очередь для этого требуется знание различных баз данных: как классических (PostgreSQL, MySQL, Oracle), так и более специфичных хранилищ данных (ClickHouse, Greenplum, Vertica), использование которых разнится от команды к команде.
Если говорить о больших массивах данных, с которыми нужно выполнять распределенные вычисления, то здесь стоит упомянуть экосистему Hadoop. Распределенная файловая система (HDFS), поверх которой работает множество технологий, также часто используется в работе дата-сайентиста. Это может быть база HBase, СУБД для работы с данными (Hive, Impala, Pig), фреймворк для распределенных вычислений Spark, который имеет множество различных приложений, таких как машинное обучение (Spark MLlib), выполнение SQL-запросов (Spark SQL), процессинг потока данных (Spark Streaming) и др.
Для удобства работы с кластером Hadoop можно использовать Hue, в котором можно писать SQL-запросы, анализировать результаты, просматривать файлы HDFS. Также есть продукт Ambari для решения схожих задач.
Для работы с множеством источников данных одновременно можно использовать DBeaver или DataGrip. Эти программы позволяют подключаться к различным источникам, писать запросы к таблицам и отлаживать запросы на выгрузку данных.
С помощью всех упомянутых технологий можно изучать данные в различных источниках, обрабатывать их, раскладывать в витрины, делать вычисления.
Помимо традиционных баз данных и кластера Hadoop, стоит упомянуть облачные решения для работы с данными от Google, Amazon и др. У Google есть Cloud Platform, а также Colab и Drive. Они позволяют делать удаленные вычисления и экспериментировать в ноутбуках. В амазоновских сервисах (AWS, S3, Redshift etc.) также можно обрабатывать и хранить данные, запускать вычисления. Такой стек можно встретить в небольших компаниях, которым выгоднее арендовать ресурсы, нежели купить свои, которые могут простаивать.
Автоматизация процессов
После того, как процесс обработки данных описан, расчет показателей определен и уже сформирован, нужно дальше автоматизировать все эти пайплайны для регулярного запуска. Здесь потребуется инструмент для настройки пайплайнов, который умеет работать по расписанию и следить за всеми задачами, — это Apache Airflow. Иногда используют Luigi, инструмент попроще, с помощью него можно также описывать DAG (Directed Acyclic Graph), производить вычисления, сбор данных, создание витрин, обучение и валидацию моделей, сохранение прогнозов рекомендаций. Это может быть сохранение в Excel-файл, запись в таблицу, либо подготовка аналитического отчета в Jupyter Notebook.
DevOps и другие полезные практики
Стоит теперь упомянуть про другие практики, в которых дата-сайентист может не быть глубоким экспертом, но с которыми он может столкнуться в работе. Это технологии контейнеризации (Docker, Kubernetes) и в целом элементы DevOps. В контейнерах можно разворачивать приложения, создавать изолированные среды для выполнения своих программ. Понимание DevOps дает возможность самостоятельно настраивать взаимодействие между системами. Также есть MLOps: это область на стыке машинного обучения, разработки и эксплуатации. Это вспомогательные инструменты для проведения различных экспериментов, версионирования моделей и данных: MLflow, DVC, Kubeflow, Hydrosphere. Эти инструменты направлены на продуктивизацию машинного обучения, создание ML-платформы, когда у специалиста есть много моделей и версий, за которыми надо следить.
Наша подборка будет разбита на две части — первые 8 библиотек предназначены для предварительной обработки и очистки данных от мусора, следующие 10 — для визуализации подготовленных данных.
Библиотеки для форматирования и очистки данных
В нашем мире всё запутано и переплетено — то же самое можно сказать и об информации. Недавнее исследование
показывает, что очистка данных занимает до 60% времени у специалистов по Data Scienсe. И 57% из них считают, что это самая утомляющая часть работы. Чтобы сделать этот процесс более приятным и быстрым, существует множество библиотек, о которых мы вам и расскажем.
Dora
Эта библиотека
предназначена для разведочного анализа данных, а именно — для автоматизации самых болезненных его частей, в том числе и для очистки данных — говорящий пример
её работы можно посмотреть на странице проекта на Github.
Datacleaner
Этот проект
также может принимать на вход данные в DataFrame (как утверждает разработчик, “datacleaner — не что-то магическое, просто взять необработанный текст и автоматически распарсить его он не может”), и затем выбирает строки с пропущенными или некорректными значениями и исправляет их таким образом, каким вы ему скажете (например, заменяет их на средние или медианные значения).
PrettyPandas
DataFrames, конечно, сильный инструмент, но он создаёт не те таблицы, которые вы бы хотели показать своему боссу. PrettyPandas
использует pandas Style API
, чтобы привести датафреймы в удобоваримый вид.
Tabulate
Tabulate
позволяет выводить в удобном виде списки списков (или другие iterable структуры из iterable структур), списки (или другие структуры) из словарей), двумерные массивы NumPy, pandas. DataFrame и массивы записей NumPy. Причём выгружать он их может не только в консоль, но и в HTML, PHP или Markdown Extra, что является очень приятным дополнением.
Scrubadub
Часто приходится обрабатывать конфиденциальные данные, выдавать которые не стоит (например, если вы работаете в сфере здравоохранения или в сфере финансов). На помощь приходит scrubadub
, которая может удалять из списка данных имена, телефоны, URL’и, идентификаторы Skype и многое другое. Естественно, присутствует возможность гибкой настройки того, что именно вы хотите убрать и каким образом.
Arrow
Отдельной проблемой для нативного Python является работа с временем. Нужно парсить строки, учитывать часовые пояса, и на всё это уходят многие строки не очень интересного кода. Эту проблему должна решить библиотека Arrow
.
Beautifier
У этой библиотеки
довольно простая задача — упростить работу с URL’ами и email-адресами. С её помощью вы можете парсить почтовые адреса по доменами и именам пользователей, а URL-адреса — по доменам и различным параметрам (например, UTM’ам или токенам).
Ftfy
Полное название этой библиотеки — Fixes text for you
. Она предназначена для того, чтобы превращать плохие Unicode строки ( “quotesâ€\x9d
или ü
) в хорошие Unicode строки ( "quotes"
или ü
соответственно).
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Библиотеки для визуализации данных
Если просматривать страницы Python Package Index, можно найти библиотеки практически для любого отображения данных, от GazeParser
‘а для отслеживания движения глаз, до pastalog
‘а для отображения развития нейронной сети в реальном времени. Некоторые из этих библиотек крайне узкоспециализированы, а некоторые могут использоваться почти для любой задачи. В этой подборке мы приводим 10 достаточно универсальных Python библиотек для отображения данных.
Matplotlib
Matplotlib
за более чем 10 лет своего существования уже фактически стала стандартом визуализации на Python. Многие современные библиотеки для построения графиков проектируются для работы совместно с matplotlib. Некоторые библиотеки, например, pandas
или Seaborn
, представляют из себя обёртки над matplotlib. Однако вместе с широтой возможностей приходит и сложность в устройстве, и, как следствие, работать с библиотекой тоже не всегда легко. Ещё один минус — оформление в духе 90-х, которое явно не подойдёт для презентаций. Последнее, однако, должен
решить релиз 2.0.
Seaborn
Как уже было сказано выше, Seaborn
— обёртка над matplotlib, привносящая в неё улучшения (главным образом в плане эстетики).
Ggplot
Ggplot базируется на ggplot2 (система построения графиков на языке R) и использует принципы Grammar of Graphics
. Как следствие, работа с ней сильно отличается от работы с matplotlib. Если верить автору, библиотека не предназначена для создания сложных персонализированных графиков, а ориентирована скорее на простоту.
Bokeh
Bokeh
также использует Grammar of Graphics, однако, в отличии от ggplot, он не портирован с R, а написан на самом Python. Библиотека поддерживает выгрузку в виде объектов JSON, в HTML-документы или интерактивные веб-приложения, равно как и поддерживает передачу данных в реальном времени и в виде потоков.
Pygal
Из основных преимуществ этой библиотеки
можно выделить предельную простоту, возможность выгрузки данных в SVG-файлы (аккуратно, при больших объёмах данных SVG, пожалуй, не стоит использовать из-за проблем производительности) и возможность встраивать результат работы в веб-приложения.
Plotly
Так же, как Pygal и Bokeh, Plotly
адаптирован для работы в интерактивных веб-приложениях. Его уникальные возможности — контурные графики
, дендограммы
и 3D чертежи
.
Geoplotlib
Как можно догадаться из названия, Geoplotlib
предназначена для работы с картами. Для её работы необходим Pyglet (объектно-ориентированный интерфейс). Так как практически ни одна из остальных библиотек не предлагает API для работы с картами, очень приятно иметь ту, которая специально заточена под них.
Gleam
Эта библиотека
была написана под вдохновением от пакета Shiny
для языка R. Она позволяет превращать результаты анализа данных в интерактивные веб-приложения, используя только Python скрипты, т.е. вам не нужно знать ни HTML, ни CSS, ни JavaScript. Gleam может работать совместно с любой библиотекой визуализации Python. Создав график, вы можете подключить к нему поля для фильтров, чтобы пользователи могли сортировать и отбирать данные, которые им необходимы.
Missingno
Если библиотеки для очистки входных данных от пропущенных полей (путём удаления таких записей целиком, или подстановки средних/медианных значений) вам не подходят, то вы можете легко визуализировать полноту данных с помощью Missingno
. Библиотека может не только визуализировать данные, но и сортировать их или отбирать в зависимости от корреляций с, скажем, дендограммами.
Leather
Создатель Leather
, Кристофер Гроскопф, удачно описал своё творение: “Leather — чертёжная библиотека для Python для тех, кому нужен график прямо сейчас, и его не волнует насколько он идеален”. Он спроектирован для работы со всеми типами данных и выводит данные в SVG, благодаря чему вы можете масштабировать графики без потери качества (к слову, у нас есть отличная статья
о векторных и битовых форматах изображений). Библиотека достаточно новая, поэтому к ней всё ещё отсутствует часть документации. Чертежи с её помощью можно сделать достаточно примитивные, но это только начало ?
На данный момент этот блок не поддерживается, но мы не забыли о нём!
Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Возможно, вам также покажется полезной наша подборка “10 малоизвестных, но полезных библиотек для Python”
.
Язык программирования Python
в последнее время все чаще используется для анализа данных, как в науке, так и коммерческой сфере. Этому способствует простота языка, а также большое разнообразие открытых библиотек.
И так, таблица с наблюдениями имеет следующие столбцы:
- datetime — дата появления объекта
- city — город в котором появился объект
- state — штат
- country — страна
- duration (seconds) — время на которое появился объект в секундах
- duration (hours/min) — время на которое появился объект в часах/минутах
- shape — форма объекта
- comments — коментарий
- date posted — дата публикации
- latitude — широта
- longitude — долгота
Для тех, кто хочет пробовать нуля, подготовим рабочее место. У меня на домашнем ПК стоит Ubuntu, поэтому покажу для нее. Для начала нужно установить сам интерпретатор Python3
с библиотеками. В убунту подобном дистрибутиве это будет:
sudo apt-get install python3
sudo apt-get install python3-pip
pip
— это система управления пакетами, которая используется для установки и управления программными пакетами, написанными на Python. С её помощью устанавливаем библиотеки, которые будем использовать:
sklearn
— библиотека, алгоритмов машинного обучения, она понадобится нам в дальнейшем для классификации исследуемых данных,matplotlib
— библиотека для построения графиков,pandas
— библиотека для обработки и анализа данных. Будем использовать для первичной обработки данных,numpy
— математическая библиотека с поддержкой многомерных массивов,yandex-translate
— библиотека для перевода текста, через yandex API (для использования нужно получить API ключ в яндексе),pycountry
— библиотека, которую будем использовать для преобразования кода страны в полное название страны,
Используя pip
пакеты ставятся просто:
pip3 install sklearn
pip3 install matplotlib
pip3 install pandas
pip3 install numpy
pip3 install yandex-translate
pip3 install pycountry
Файл DataSet — scrubbed.csv
должен лежать в рабочей директории, где создается файл программы.
Итак приступим. Подключаем модули, которые используются нашей программой. Модуль подключается с помощью инструкции:
import <название модуля>
Если название модуля слишком длинное, и/или не нравится по соображениям удобства или политическим убеждениямм, то с помощью ключевого слова as
для него можно создать псевдоним:
import <название модуля> as <псевдоним>
Тогда, чтобы обратиться к определенному атрибуту, который определен в модуле
<название модуля>.<Атрибут>
<псевдоним>.<Атрибут>
Для подключения определенных атрибутов модуля используется инструкция from
. Для удобства, чтобы не писать названия модуля, при обращении к атрибуту, можно подключить нужный атрибут отдельно.
from <Название модуля> import <Атрибут>
Подключение нужных нам модулей:
import pandas as pd
import numpy as np
import pycountry
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from yandex_translate import YandexTranslate # Используем класс YandexTranslate из модуля yandex_translate
from yandex_translate import YandexTranslateException # Используем класс YandexTranslateException из модуля yandex_translate
Для того, что бы улучшить наглядность графиков, напишем вспомогательную функцию для генерации цветовой схемы. На входе функция принимает количество цветов, которое необходимо сгенерировать. Функция возвращает связный список с цветами.
# Размер надписей на графиках
PLOT_LABEL_FONT_SIZE = 14
# Генерация цветовой схемы
# Возвращает список цветов
def getColors(n):
COLORS = []
cm = plt.cm.get_cmap('hsv', n)
for i in np.arange(n):
COLORS.append(cm(i))
return COLORS
Для перевода некоторых названий с англиского на русский язык создадим функцию translate
. И да, нам понадобится интернет, чтобы воспользоваться API переводчика от Яндекс
.
Функция принимает на вход аргументы:
- string
— строка, которую нужно перевести, - translator_obj
— объект в котором реализован переводчик, если равен None
, то строка не переводится.
и возвращает переведенную на русский язык строку.
def translate(string, translator_obj=None):
if translator_class == None:
return string
t = translator_class.translate(string, 'en-ru')
return t['text'][0]
Инициализация объекта переводчика должна быть в начале кода.
YANDEX_API_KEY = 'Здесь должен быть определен API ключ !!!!!'
try:
translate_obj = YandexTranslate(YANDEX_API_KEY)
except YandexTranslateException:
translate_obj = None
YANDEX_API_KEY
— это ключ доступа к API Yandex, его следует получить в Яндексе. Если он пустой, то объект translate_obj
инициализируется значением None
и перевод будет игнорироваться.
Напишем еще одну вспомогательную функцию для сортировки объектов dict
.
dict
— представляет собой встроенный тип Python, где данные хранятся в виде пары ключ-значения. Функция сортирует словарь по значениям в убывающем порядке и возвращает отсортированные список ключей и соответсвуюущий ему по порядку следования элементов список значений. Эта функция будет полезна при построении гистограмм.
def dict_sort(my_dict):
keys = []
values = []
my_dict = sorted(my_dict.items(), key=lambda x:x[1], reverse=True)
for k, v in my_dict:
keys.append(k)
values.append(v)
return (keys,values)
Мы добрались до непосредственно данных. Для чтения файла с таблицей используем метод read_csv
модуля pd
. На вход функции подаем имя csv
файла, и чтобы подавить предупреждения при чтении файла, задаем параметры escapechar
и low_memory
.
- escapechar
— символы, которые следует игнорировать - low_memory
— настройка обработки файла. Задаем False
для считывание файла целиком, а не частями.
df = pd.read_csv('./scrubbed.csv', escapechar='`', low_memory=False)
В некоторых полях таблицы есть поля со значением None
. Этот встроенный тип, обозначающий неопределенность, поэтому некоторые алгоритмы анализа могут работать некорректно с этим значением, поэтому произведем замену None
на строку ‘unknown’
в полях таблицы. Эта процедура называется импутацией
.
df = df.replace({'shape':None}, 'unknown')
Поменяем коды стран на названия на русском языке с помощью библиотеки pycountry
и yandex-translate
.
country_label_count = pd.value_counts(df['country'].values) # Получить из таблицы список всех меток country с их количеством
for label in list(country_label_count.keys()):
c = pycountry.countries.get(alpha_2=str(label).upper()) # Перевести код страны в полное название
t = translate(c.name, translate_obj) # Перевести название страны на русский язык
df = df.replace({'country':str(label)}, t)
Переведем все названия видов объектов на небе на русский язык.
shapes_label_count = pd.value_counts(df['shape'].values)
for label in list(shapes_label_count.keys()):
t = translate(str(label), translate_obj) # Перевести название формы объекта на русский язык
df = df.replace({'shape':str(label)}, t)
Первичную обработку данных на этом завершаем.
country_count = pd.value_counts(df['country'].values, sort=True)
country_count_keys, country_count_values = dict_sort(dict(country_count))
TOP_COUNTRY = len(country_count_keys)
plt.title('Страны, где больше всего наблюдений', fontsize=PLOT_LABEL_FONT_SIZE)
plt.bar(np.arange(TOP_COUNTRY), country_count_values, color=getColors(TOP_COUNTRY))
plt.xticks(np.arange(TOP_COUNTRY), country_count_keys, rotation=0, fontsize=12)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Количество наблюдений', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()
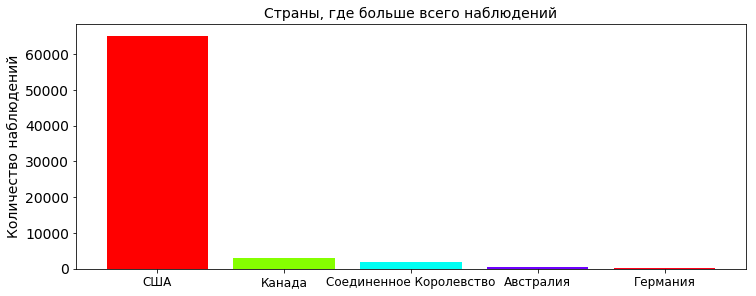
Больше всего наблюдений естественно в США. Тут ведь оно как, все гики, которые следят за НЛО живут в США (о версии, что таблица составлялась гражданами США, лукаво умолчим). Судя по количеству американских фильмов скорее всего второе. От Кэпа: если инопланетяне действительно посещали землю в открытую, то вряд ли бы их заинтересовала одна страна, сообщение об НЛО появлялись бы из разных стран.
Интересно еще посмотреть в какое время года наблюдали больше всего объектов. Есть резонное предположение, что больше всего наблюдений в весеннее время.
MONTH_COUNT = [0,0,0,0,0,0,0,0,0,0,0,0]
MONTH_LABEL = ['Январь', 'Февраль', 'Март', 'Апрель', 'Май', 'Июнь',
'Июль', 'Август', 'Сентябрь' ,'Октябрь' ,'Ноябрь' ,'Декабрь']
for i in df['datetime']:
m,d,y_t = i.split('/')
MONTH_COUNT[int(m)-1] = MONTH_COUNT[int(m)-1] + 1
plt.bar(np.arange, MONTH_COUNT, color=getColors)
plt.xticks(np.arange, MONTH_LABEL, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Частота появления', fontsize=PLOT_LABEL_FONT_SIZE)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.title('Частота появления объектов по месяцам', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()

Ожидалось весеннее обострение, но предположение не подтвердилось. Кажется теплые летние ночи и период отпусков дают о себе знать сильнее.
Посмотрим какие формы объектов на небе видели и сколько раз.
shapes_type_count = pd.value_counts(df['shape'].values)
shapes_type_count_keys, shapes_count_values = dict_sort(dict(shapes_type_count))
OBJECT_COUNT = len(shapes_type_count_keys)
plt.title('Типы объектов', fontsize=PLOT_LABEL_FONT_SIZE)
bar = plt.bar(np.arange(OBJECT_COUNT), shapes_type_count_values, color=getColors(OBJECT_COUNT))
plt.xticks(np.arange(OBJECT_COUNT), shapes_type_count_keys, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Сколько раз видели', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()
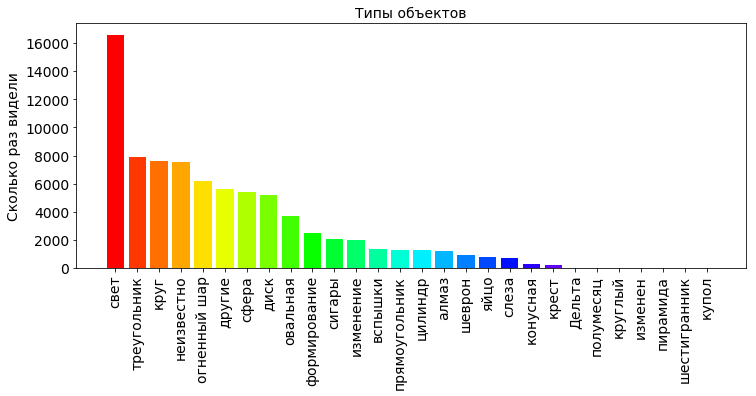
Из графика мы видим, что больше всего на небе видели просто свет, который в принципе необязательно является НЛО. Этому явлению существует внятное объяснение, например, ночное небо отражает свет от прожекторов, как в фильмах про Бэтмена. Также это вполне может быть северным сиянием, которое появляется не только в полярной зоне, но и в средних широтах, а изредка даже и в близи эвкватора. Вообще атмосфера земли пронизана множеством излучений различной природы, электрическими и магнитными полями.
Вообще, атмосфера Земли пронизана множеством излучений различной природы, электрическими и магнитными полями.
Подробнее см.: https://www.nkj.ru/archive/articles/19196/
(Наука и жизнь, Что светится на небе?)
Интересно еще посмотреть среднее время, на которое в небе появлялся каждый из объектов.
shapes_durations_dict = {}
for i in shapes_type_count_keys:
dfs = df[['duration (seconds)', 'shape']].loc[df['shape'] == i]
shapes_durations_dict[i] = dfs['duration (seconds)'].mean(axis=0)/60.0/60.0
shapes_durations_dict_keys = []
shapes_durations_dict_values = []
for k in shapes_type_count_keys:
shapes_durations_dict_keys.append(k)
shapes_durations_dict_values.append(shapes_durations_dict[k])
plt.title('Среднее время появление каждого объекта', fontsize=12)
plt.bar(np.arange(OBJECT_COUNT), shapes_durations_dict_values, color=getColors(OBJECT_COUNT))
plt.xticks(np.arange(OBJECT_COUNT), shapes_durations_dict_keys, rotation=90, fontsize=16)
plt.ylabel('Среднее время появления в часах', fontsize=12)
plt.show()
Из диаграммы видими, что больше всего в небе в среднем висел конус (более 20 часов). Если покопаться в интернетах, то ясно, что конусы в небе, это тоже свечение, только в виде конуса (неожиданно, да?). Вероятнее всего это свет от падающих комет. Среднее время больше 20 часов — это какая-то нереальная величина. В исследуемых данных большой разброс, и вполне могла вкраться ошибка. Несколько очень больших, неверных значений времени появления могут существенно исказить расчет среднего значения. Поэтому при больших отклонениях, считают не среднее значение, а
.
Медиана
— это некоторое число, характеризующее выборку, одна половина в выборке меньше этого числа, другая больше. Для расчета медианы используем функцию
median
.
Заменим в коде выше:
def translate(string, translator_obj=None):
if translator_class == None:
return string
t = translator_class.translate(string, 'en-ru')
return t['text'][0]
Полумесяц видели в небе чуть больше 5-ти часов. Другие объекты не надолго промелькнули в небе. Это уже наиболее достоверно.
Для первого знакомства с методологией обработки данных на Python, думаю, достаточно. В следующих публикациях займемся статистическим анализом, и постараемся выбрать другой не менее актуальный пример.
Ссылка на архив с данными и блоткнотом Jupyter
Библиотека для предварительной обработки данных
Библиотека алгоритмов машинного обучения
Библиотека для визуализации данных
Туториал на русском языке по работе с Jupyter
Python — это один из самых распространённых языков программирования. Хотя стандартные возможности Python достаточно скромны, существует огромное количество пакетов, которые позволяют решать с помощью этого языка самые разные задачи. Пожалуй, именно поэтому Python и пользуется такой популярностью среди программистов. Можно наугад назвать какую-нибудь сферу деятельности и в экосистеме Python, почти гарантированно, найдутся отличные инструменты для решения специфических задач из этой сферы. В наше время весьма востребованы наука о данных (Data Science, DS) и машинное обучение (Machine Learning, ML). И там и там Python показывает себя наилучшим образом.
Помимо Python в DS-проектах часто используют язык программирования R. R быстрее Python и имеет больше статистических и вычислительных библиотек. Но в этом материале мы будем говорить исключительно о библиотеках (пакетах) для Python, о которых стоит знать каждому, кто хочет добраться до профессиональных вершин Data Science.

Прежде чем переходить к обзору библиотек, остановимся на том, что это такое — «наука о данных», и на том, почему в этой сфере стоит пользоваться языком Python.
Обзор Data Science
В наши дни данные в бизнесе ценятся буквально на вес золота. Мы живём во времена больших данных, каждую секунду в мире появляются огромные объёмы информации. Крупные организации пользуются этими данными ради укрепления и расширения своего бизнеса.
Применяя DS и другие подобных технологии, мы извлекаем из данных ценные сведения, которые позволяют решать сложные реальные задачи и строить прогнозные модели. Data Science — это не инструмент или технология. Это — навык, который можно развить, освоив некоторые инструменты и программные пакеты.
Почему Python используется в сфере Data Science?
Python считается одним из ведущих языков программирования, используемых для построения DS- и ML-моделей.
Обсудим основные причины, по которым разработчики и дата-сайентисты предпочитают использовать в своих проектах Python, а не другие языки программирования.
Это — очевидная причина выбора из множества существующих языков программирования именно Python. В этом языке используется простой и понятный синтаксис, писать Python-код совсем несложно. Этот процесс напоминает написание инструкций на обычном английском языке.
▍Для решения сложных задач требуется писать сравнительно небольшие объёмы кода
Алгоритмы из сфер DS и ML весьма сложны. Поэтому для их реализации желательно использовать такой язык программирования, который позволяет кратко и ёмко выражать идеи разработчика. Python, благодаря его синтаксису и чёткой структуре кода, отлично подходит для решения подобных задач. Это помогает программистам создавать компактные и мощные программы.
Главные ресурсы Python-программиста — это дополнительные библиотеки. Создано множество Python-пакетов, ориентированных на сферу Data Science. В них имеются реализации сложных алгоритмов, что позволяет тем, кому нужны эти алгоритмы, не писать код с нуля.
Python-программы могут работать на различных платформах. В частности — на Windows, Linux, macOS. Код, написанный для некоей платформы, может, без изменений, запускаться на других платформах.
Вокруг Python сформировалось огромное сообщество. Существует множество онлайн-площадок, на которых разработчики обсуждают возникшие у них проблемы и помогают друг другу в их решении.
Python-пакеты для Data Science
Мы поговорили о том, что такое Data Science, и о том, почему Python популярен в этой сфере. Теперь давайте рассмотрим некоторые полезные Python-пакеты. В частности, речь пойдёт о следующих пакетах:
- NumPy
- SciPy
- Pandas
- StatsModels
- Matplotlib
- Seaborn
- Plotly
- Bokeh
- Scikit-Learn
- Keras
NumPy — это один из самых широко используемых Python-пакетов. Название пакета, NumPy, расшифровывается как Numerical Python. Здесь реализовано множество вычислительных механизмов, пакет поддерживает специализированные структуры данных, в том числе — одномерные и многомерные массивы, значительно расширяющие возможности Python по выполнению различных вычислений. Возможности структур данных, которые поддерживает Python, уступают возможностям структур данных NumPy.
- Пакет можно использовать как для выполнения простых, так и достаточно сложных научных расчётов.
- Он поддерживает многомерные массивы, расширяя возможности Python.
- В пакете имеется множество встроенных методов, которые можно применять для выполнения различных вычислений на многомерных массивах.
- Пакет позволяет выполнять различные преобразования данных.
- Пакет поддерживает работу не только с числовыми, но и с другими типами данных.
Пакет SciPy построен на основе NumPy, в нём используются и некоторые другие вспомогательные пакеты. Он широко используется для выполнения статистических расчётов. В SciPy можно работать с теми же данными, что и в NumPy. Поэтому SciPy часто используют для решения задач, которые нельзя решить с использованием стандартных механизмов NumPy. SkiPy — это инструмент, которому доверяет огромное количество учёных во всём мире.
- Пакет SciPy основан на NumPy.
- Он поддерживает вычисления, основанные на эффективных структурах данных NumPy.
- Этот пакет, помимо возможностей NumPy, задействует и возможности других пакетов.
- SciPy представляет собой набор подпакетов, в которых реализованы различные вычислительные механизмы. Среди них, например, подпакеты, реализующие быстрое преобразование Фурье, обработку изображений, решение дифференциальных уравнений, механизмы линейной алгебры.
Pandas — это, после NumPy, второй по известности Python-пакет, используемый в Data Science. Его применяют в самых разных местах, например, в сферах статистики, финансов, экономики, анализа данных. Он основан на NumPy, в частности, поддерживает преобразование структур данных NumPy в собственные структуры данных и обратные преобразования. Пакет Pandas часто используют для обработки больших объёмов данных. В ходе обработки данных Pandas прибегает к некоторым возможностям NumPy, в нём применимы и возможности SciPy, например, средства проведения статистических вычислений. Фактически, для проведения DS-вычислений обычно используются все три пакета — Pandas, NumPy и SciPy.
- Он поддерживает объект DataFrame, предназначенный для работы с индексированными массивами.
- Этот пакет является одним из лучших инструментов для исследования данных.
- Его можно использовать для работы с большими наборами данных. В частности, речь идёт о слиянии и объединении наборов данных, о создании срезов данных, о группировке данных, об их визуализации.
- Пакет может работать с различными источниками данных. Например — с CSV- и TSV-файлами, с базами данных.
Пает StatsModels основан на пакетах NumPy и SciPy. Он широко используется для анализа данных, для создания статистических моделей, для выполнения статистических исследований. Данный пакет весьма популярен благодаря своим возможностям в сфере статистических вычислений. Он хорошо интегрируется, например, с Pandas. В других подобных пакетах, в SciPy, например, выполнять статистические вычисления достаточно сложно. StatsModels упрощает решение подобных задач.
- Многие дата-сайентисты используют этот пакет для проведения статистических вычислений.
- В его состав входят некоторые методы, которые знакомы тем, кто пользуется языком R.
- С его помощью создают и исследуют, например, обобщённые линейные модели, он позволяет проводить одномерный и двумерный анализ данных, применяется для проверки гипотез.
Matplotlib — это известнейший Python-пакет для визуализации данных. Его, пожалуй, можно включить в набор основных пакетов, которые нужно освоить тому, кто пользуется Python в сфере Data Science. Он поддерживает множество стандартных средств для визуализации данных, представленных различными графиками и диаграммами.
Этот пакет может работать вместе с другими Python-пакетами, вроде уже известных нам NumPy и SciPy. Он, кроме того, поддерживает API, который позволяет встраивать создаваемые им графические объекты в различные приложения.
- С помощью этого пакета можно очень просто и удобно строить различные графики и диаграммы.
- Графические представления данных, создаваемые этим пакетом, поддаются глубокой настройке.
- Он поддерживает объектно-ориентированный API, позволяющий интегрировать его в различные приложения.
Seaborn — это расширение для Matplotlib, которое направлено на то, чтобы сделать графики Matplotlib привлекательнее и упростить создание сложных визуализаций. Этот пакет, кроме того, содержит API, направленный на изучение взаимоотношений между переменными. В целом, Seaborn можно назвать «улучшенным Matplotlib».
- Встроенные возможности исследования данных.
- Поддержка различных форматов данных.
- Он умеет строить графики моделей линейной регрессии.
- Его используют для создания сложных визуализаций.
- Он поддерживает различные способы настройки внешнего вида графиков.
Plotly — это ещё один известный Python-пакет для визуализации данных. Он даёт в наше распоряжение интерактивные графики, позволяющие исследовать взаимоотношения переменных. Plotly, помимо сферы статистики, используется в финансах, в экономике, в науке. Plotly отличается от Matplotlib гораздо более продвинутыми возможностями по построению трёхмерных графиков.
- Этот пакет поддерживает все необходимые дата-сайентисту виды графиков. Среди них — линейные диаграммы, круговые диаграммы, пузырьковые диаграммы, точечные диаграммы, древовидные диаграммы.
- Он, кроме того, поддерживает специфические виды диаграмм, используемые в статистике и науке.
- Пакет поддерживает трёхмерные визуализации.
- Он экспортирует данные в формат JSON, подходящий для использования в других приложениях.
Bokeh — это пакет, предназначенный для визуализации данных в веб-приложениях. Его можно легко интегрировать с любым Python-фреймворком, с таким, как Flask или Django. Он поддерживает множество видов графиков. Этим пакетом просто и удобно пользоваться. В частности, речь идёт о том, что создавать с его помощью интерактивные графики можно, написав буквально несколько строк кода.
- Поддерживает визуализацию наборов данных, которые обычно используются в статистике и науке.
- Поддерживает различные форматы выходных данных.
- Существуют версии Bokeh для разных языков программирования.
- Пакет хорошо интегрируется с такими Python-фреймворками, как Django и Flask.
Scikit-Learn — это Python-пакет для машинного обучения. Он включает в себя практически всё, что нужно дата-сайентисту. Этот проект появился на мероприятии Google Summer of Code. В нём имеются различные встроенные модули, которые дают возможность работать с множеством популярных алгоритмов машинного обучения. Это, например, алгоритм «случайный лес», алгоритм спектральной кластеризации, алгоритм кросс-валидации, метод k-средних и многие другие. Этот пакет можно использовать для создания моделей машинного обучения с учителем и без учителя.
- На основе этого пакета можно создавать спам-детекторы и системы классификации изображений.
- Поддерживает различные алгоритмы регрессии.
- Позволяет создавать модели машинного обучения с учителем и без учителя.
- Поддерживает механизмы кросс-валидации для оценки моделей.
Keras — это пакет, реализующий механизмы глубокого обучения (Deep Learning, DL), который широко используется при создании нейросетевых моделей. Это — одна из самых мощных опенсорсных Python-библиотек, которая способна работать с самыми разными видами данных, например — с текстами и с изображениями. Существуют и другие надёжные DL-решения, предназначенные для Python-разработчиков, но Keras выгодно отличается от них тем, что упрощает работу со сложными моделями глубокого обучения.
- Поддерживает широкий набор нейросетевых моделей.
- Содержит встроенные средства для работы с изображениями.
- Поддерживает популярные алгоритмы глубокого обучения.
- Отличается высоким уровнем расширяемости, что позволяет, при необходимости, оснащать его новым функционалом.
Все Python-пакеты, о которых мы рассказали, пользуются серьёзной популярностью в среде дата-сайентистов. Есть, конечно, и другие подобные библиотеки. И вам, если вы хотите построить карьеру в сфере Data Science, понадобится разобраться со многими из них, а не только с теми, о которых мы говорили сегодня.
Какими Python-пакетами из сферы Data Science вы пользуетесь чаще всего?


Библиотеки Python — это файлы с шаблонами кода. Их создали для того, чтобы люди не набирали каждый раз заново один и тот же код: достаточно открыть файл, вставить свои данные и получить результат.
Рассказываем, какие библиотеки часто используют разработчики на Python.
