
Время на прочтение
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
- Что такое Pandas?
- Что такое анализ данных?
- Вводная
- Основные библиотеки Python
- Jupyter
- NumPy
- SciPy
- Постановка задачи
- Анализ входных данных
- Предварительная обработка входных данных
- Построение моделей классификации и их анализ
- Заключение
- Разработка
- Анализ данных в Pandas
- Структуры данных в Pandas
- Отсутствующие данные
- Matplotlib
- Библиотеки для интеллектуального анализа и обработки естественного языка
- Scrapy
- NLTK (Natural Language Toolkit)
- Pattern
- Библиотеки Python для визуализации
- Seaborn
- Bokeh
- Basemap
- NetworkX
- Требования и план разработки
- Среда разработки
- Библиотеки для работы с данными
- Scikit-learn
- TensorFlow
- Keras
- Работа с отдельными столбцами или строками
- Добавление новых строк и столбцов
- Удаление строк и столбцов
- Копирование датафрейма
- Уникальные значения
- Группировка данных
- Сводные таблицы
- Сортировка данных
- Фильтрация
- Применение функций к столбцам
- Очистка данных
- Построение графиков
- Сохранение датафрейма на компьютер
- Результат
Что такое Pandas?
Pandas — это библиотека Python с открытым исходным кодом, используемая для манипулирования данными. Это быстрая и высокоэффективная библиотека с инструментами для загрузки нескольких видов данных в память. Его можно использовать для изменения формы, маркировки среза, индексации или даже группировки нескольких форм данных.
Наука данных является обширной областью исследования с большим количеством областей, из которых анализ данных является неоспоримо один из наиболее важных из всех этих областей, и независимо от своего уровня мастерства в науке данных, она становится все более важной для понимания.
Если вы новичок в Python, советуем прочитать книги по языку программирования Python
Что такое анализ данных?
Анализ данных — это обработка и преобразование большого количества неструктурированных или неорганизованных данных с целью генерирования ключевой информации об этих данных, которые могли бы помочь в принятии обоснованных решений.
Существуют различные инструменты, используемые для анализа данных, Python, Microsoft Excel, Tableau, SaS и т. Д., Но в этой статье мы сосредоточимся на том, как анализ данных выполняется в python. Более конкретно, как это делается с библиотекой Python под названием Pandas.
Язык Python часто применяется в Data Science, потому что, во-первых, по сравнению с другими языками код для сложных задач на Python проще и короче. А во-вторых, есть много мощных прикладных библиотек для решения разных задач: первичной обработки и анализа данных, обработки естественного языка и визуализации. Эта подборка будет полезна аналитикам данных, математикам и тем, кто занимается Data Science на разных уровнях. Составить ее нам помогли эксперты старший аналитик «Ростелеком» Константин Башевой, руководитель отдела аналитики в Mail.ru Петр Ермаков и ментор курса SkillFactory Анна Агабекян.
Библиотеки Python — это файлы с шаблонами кода. Их придумали для того, чтобы людям не приходилось каждый раз заново набирать один и тот же код: они просто открывают файл, вставляют свои данные и получают нужный результат. В этом материале вы найдете описание библиотек, которые используются чаще всего для анализа данных на Python.
Вводная
В рамках расширения своих компетенций периодически провожу анализ данных датасетов. В какой-то момент осознал, что трачу время на столбцы с аналитиками, в которых все в порядке. Данные полные, тип данных единый, интерпретация понятна. Если столбцов несколько десятков, то обзорная проверка атрибутов каждого столбца занимает довольно значительное время.
Посмотрел в сторону библиотеки pandas-profiling.
Мне показалось, что инструмент хорошо подходит для датасета в котором отработаны аномалии, пропуски, выбросы, типы данных. Вызвав df.profile_report() получаешь добротный отчет и остается только рыться во всех вкладках отчета и анализировать интересующие столбцы.
Меня смутил большой объем информации, который выдает profile_report(). Мне не хватило более простой обзорной формы, где легко можно сделать вывод и решить для себя стоит обратить внимание на столбец или нет. Возникла потребность самому настроить выдачу отчета под себя.
Разработчиком я не являюсь, поэтому попытался накидать простой код своими силами, который бы позволил немного ускорить процесс проверки. Возможно он поможет и вам. Был бы признателен, если в комментариях, напишите ваше предложение, что можно улучшить, добавить, скорректировать.
Основные библиотеки Python
Вот базовые библиотеки, которые делают из языка программирования Python инструмент для анализа и визуализации данных. Иногда их называют SciPy Stack. На них основываются более специализированные библиотеки.
Jupyter
Интерактивная оболочка для языка Python. В ней есть дополнительный командный синтаксис; она сохраняет историю ввода во всех сеансах, подсвечивает и автоматически дополняет код. Если вы когда-либо пользовались Mathematica или MATLAB, то разберетесь и в Jupyter.
Интерфейс библиотеки подходит для исследования и первичной обработки данных, тестирования первых версий кода и его улучшения. Используя язык разметки Markdown для форматирования текста и библиотеки для визуализации, можно формировать аналитические отчеты в браузере или преобразовать отчет в презентацию. С помощью JupyterHub можно настроить совместную работу команды на сервере.
Пример небольшого анализа данных в браузере:

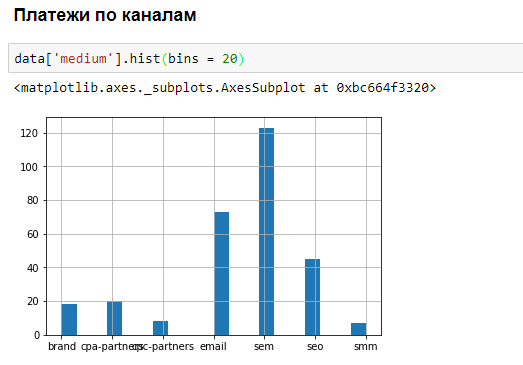

NumPy
NumPy — основная библиотека Python, которая упрощает работу с векторами и матрицами. Содержит готовые методы для разных математических операций: от создания, изменения формы, умножения и расчета детерминанта матриц до решения линейных уравнений и сингулярного разложения. Например, возьмем такую систему уравнений:
Чтобы ее решить, достаточно воспользоваться методом lialg.solve:

SciPy
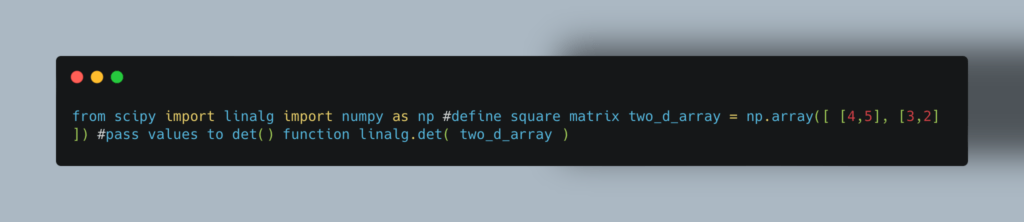
Библиотека SciPy основывается на NumPy и расширяет ее возможности. SciPy похожа на Matlab. Включает методы линейной алгебры и методы для работы с вероятностными распределениями, интегральным исчислением и преобразованиями Фурье.
Пример расчета определителя двумерной матрицы:
Добрый день уважаемые читатели. В сегодняшней посте я продолжу свой цикл статей посвященный анализу данных на python c помощью модуля Pandas и расскажу один из вариантов использования данного модуля в связке с модулем для машинного обучения scikit-learn. Работа данной связки будет показана на примере задачи про спасенных с «Титаника". Данное задание имеет большую популярность среди людей, только начинающих заниматься анализом данных и машинным обучением.
Постановка задачи
Итак суть задачи состоит в том, чтобы с помощью методов машинного обучения построить модель, которая прогнозировала бы спасется человек или нет. К задаче прилагаются 2 файла:
Как было написано выше, для анализ понадобятся модули Pandas и scikit-learn. С помощью Pandas мы проведем начальный анализ данных, а sklearn поможет в вычислении прогнозной модели. Итак, для начала загрузим нужные модули:
Кроме того даются пояснения по некоторым полям:
Анализ входных данных
from pandas import read_csv, DataFrame, Series
data = read_csv(‘Kaggle_Titanic/Data/train.csv’)
Можно предположить, что чем выше социальный статус, тем больше вероятность спасения. Давайте проверим это взглянув на количество спасшихся и утонувших в зависимости в разрезе классов. Для этого нужно построить следующую сводную:
data.pivot_table(‘PassengerId’, ‘Pclass’, ‘Survived’, ‘count’).plot(kind=’bar’, stacked=True)
Наше вышеописанное предположение про то, что чем выше у пассажиров их социальное положение, тем выше их вероятность спасения. Теперь давайте взглянем, как количество родственников влияет на факт спасения:
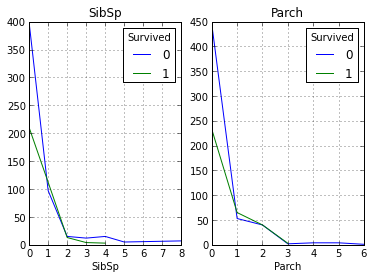
Как видно из графиков наше предположение снова подтвердилось, и из людей имеющих больше 1 родственников спаслись не многие.
Сейчас порассуждаем на предмет данных, которые находятся номера кают. Теоретически данных о каютах пользователей может не быть, так что давайте посмотрим на столько это поле заполнено:
В итоге заполнено всего 204 записи и 890, на основании этого можно сделать вывод, что данное поле при анализе можно опустить.
Следующее поле, которое мы разберем будет поле с возрастом (Age). Посмотрим на сколько оно заполнено:
Данное поле практически все заполнено (714 непустых записей), но есть пустые значения, которые не определены. Давайте зададим ему значение равное медиане по возрасту из всей выборки. Данный шаг нужен для более точного построения модели:
data. Age = data. Age.median()
У нас осталось разобраться с полями Ticket, Embarked, Fare, Name. Давайте посмотрим на поле Embarked, в котором находится порт посадки и проверим есть ли такие пассажиры у которых порт не указан:
Итак у нас нашлось 2 таких пассажира. Давайте присвоим эти пассажирам порт в котором село больше всего людей:
Ну что же разобрались еще с одним полем и теперь у нас остались поля с имя пассажира, номером билета и ценой билета.
По сути нам из этих трех полей нам нужна только цена(Fare), т.к. она в какой-то мере определяем ранжирование внутри классов поля Pclass. Т. е. например люди внутри среднего класса могут быть разделены на тех, кто ближе к первому(высшему) классу, а кто к третьему(низший). Проверим это поле на пустые значения и если таковые имеются заменим цену медианой по цене из все выборки:
В нашем случае пустых записей нет.
В свою очередь номер билета и имя пассажира нам никак не помогут, т. к. это просто справочная информация. Единственное для чего они могут пригодиться — это определение кто из пассажиров потенциально являются родственниками, но так как люди у которых есть родственники практически не спаслись (это было показано выше) можно пренебречь этими данными.
Теперь, после удаления всех ненужных полей, наш набор выглядит так:
Предварительная обработка входных данных
Предварительный анализ данных завершен, и по его результатам у нас получилась некая выборка, в которой содержатся несколько полей и вроде бы можно преступить к построению модели, если бы не одно «но»: наши данные содержат не только числовые, но и текстовые данные.
Поэтому переде тем, как строить модель, нужно закодировать все наши текстовые значения.
Можно это сделать в ручную, а можно с помощью модуля sklearn.preprocessing. Давайте воспользуемся вторым вариантом.
Закодировать список с фиксированными значениями можно с помощью объекта LabelEncoder(). Суть данной функции заключается в том, что на вход ей подается список значений, который надо закодировать, на выходе получается список классов индексы которого и являются кодами элементов поданного на вход списка.
В итоге наши исходные данные будут выглядеть так:
Теперь нам надо написать код для приведения проверочного файла в нужный нам вид. Для этого можно просто скопировать куски кода которые были выше(или просто написать функцию для обработки входного файла):
Код описанный выше выполняет практически те же операции, что мы проделали с обучающей выборкой. Отличие в том, что добавилась строка для обработки поля Fare, если оно вдруг не заполнено.
Построение моделей классификации и их анализ
Ну что же, данные обработаны и можно приступить к построению модели, но для начала нужно определиться с тем, как мы будем проверять точность полученной модели. Для данной проверки мы будем использовать скользящий контроль и ROC-кривые. Проверку будем выполнять на обучающей выборке, после чего применим ее на тестовую.
Итак рассмотрим несколько алгоритмов машинного обучения:
Загрузим нужные нам библиотеки:
from sklearn import cross_validation, svm
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
import pylab as pl
Для начала, надо разделить нашу обучаюшую выборку на показатель, который мы исследуем, и признаки его определяющие:
Теперь наша обучающая выборка выглядит так:
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split модуля cross_validation:
ROCtrainTRN, ROCtestTRN, ROCtrainTRG, ROCtestTRG = cross_validation.train_test_split(train, target, test_size=0.25)
В качестве параметров ей передается:
На выходе функция выдает 4 массива:
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
model_rfc = RandomForestClassifier(n_estimators = 70) #в параметре передаем кол-во деревьев
model_knc = KNeighborsClassifier(n_neighbors = 18) #в параметре передаем кол-во соседей
model_lr = LogisticRegression(penalty=’l1′, tol=0.01)
model_svc = svm. SVC() #по умолчанию kernek=’rbf’
Теперь проверим полученные модели с помощью скользящего контроля. Для этого нам необходимо воcпользоваться функцией cross_val_score
Давайте посмотрим на графике средний показатель тестов перекрестной проверки каждой модели:
DataFrame.from_dict(data = itog_val, orient=’index’).plot(kind=’bar’, legend=False)
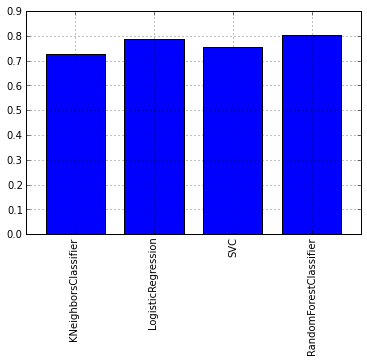
Как можно увидеть из графика лучше всего себя показал алгоритм RandomForest. Теперь же давайте взглянем на графики ROC-кривых, для оценки точности работы классификатора. Графики будем рисовать с помощью библиотеки matplotlib:
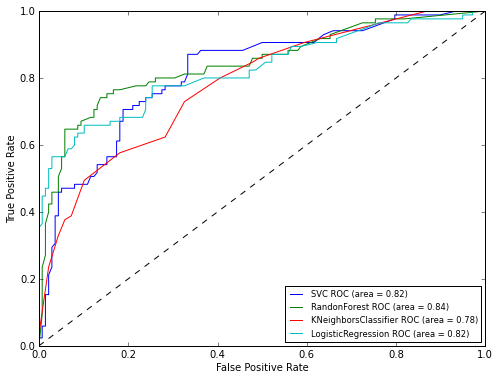
Как видно по результатам ROC-анализа лучший результат опять показал RandomForest. Теперь осталось только применить нашу модель к тестовой выборке:
model_rfc.fit(train, target)
result.insert(1,’Survived’, model_rfc.predict(test))
result.to_csv(‘Kaggle_Titanic/Result/test.csv’, index=False)
Заключение
В данной статье я постарался показать, как можно использовать пакет pandas в связке с пакетом для машинного обучения sklearn. Полученная модель при сабмите на Kaggle показала точность 0.77033. В статье я больше хотел показать именно работу с инструментарием и ход выполнения исследования, а не построение подробного алгоритма, как например в этой серии статей.
Разработка
На вход подаем Dataframe
Делаем доступными для функций:
CreateDf принимает список с результатом анализа и создает DataFrame. Очищает список, в котором хранились результаты с целью использования в следующих функциях.
def CreateDf(self,BoxResult:list):
OutputDf = pd. DataFrame(data=BoxResult, columns=list(self. СolumnsDict.keys()))
self. BoxResult.clear()
return OutputDf
Напишем несколько простых функций с анализом. Проанализируем имена столбцов на предмет наличия пробелов. Ранее при использовании query в pandas пробелы в названиях столбцов попортили нервы.
Второй анализ будет связан с наличием пустых строк в столбце. Выведем абсолютное и относительное число.
Каждая функция завершается созданием отдельного dataframe
Третья функция немного сложнее. Анализируем состав типа данных внутри столбца. Результаты выводим так же в абсолютных и относительных значениях.
Функции для анализа выбросов и анализ уникальности я оставлю в коде на GitHub.
Сбор всего анализа
Наши функции выдают отдельные DataFrame, соберем их в отдельный список. При помощи concat объединим в один.
В качестве демонстрации работы с итоговой таблицей, изменил порядок столбцов и добавил сортировку.
Анализ данных в Pandas
Для этой статьи какие-либо установки не требуются. Мы будем использовать инструмент под названием colaboratory, созданный Google. Это онлайн среда Python для анализа данных, машинного обучения и искусственного интеллекта. Это просто облачный Jupyter Notebook, который поставляется с предустановленным почти каждым пакетом Python, который вам понадобится как специалист по данным.
Теперь перейдите на сайт https://colab.research.google.com/notebooks/intro.ipynb. Вы должны увидеть картинку ниже.
В левом верхнем углу, выберите опцию «File» и нажмите «New notebook». Вы увидите новую страницу записной книжки Jupyter, загруженную в ваш браузер. Первое, что нам нужно сделать, это импортировать Pandas в нашу рабочую среду. Мы можем сделать это, с помощью строки:
import pandas as pd
Для этой статьи мы будем использовать набор данных о ценах на жилье для нашего анализа данных. Набор данных, который мы будем использовать, можно найти здесь. Первое, что мы хотели бы сделать, это загрузить этот набор данных в нашу среду.
Мы можем сделать это с помощью следующего кода в новой ячейке;
df = pd.read_csv(‘https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ‘, sep=’,’)
read_csv Используется, чтобы прочитать файл CSV и мы прошли SEP свойство, чтобы показать, что файл CSV разделяются запятыми.
Также следует отметить, что наш загруженный CSV-файл хранится в переменной df.
Нам не нужно использовать функцию print() в Jupyter Notebook. Мы можем просто ввести имя переменной в нашей ячейке, и Jupyter Notebook распечатает его для нас.
Мы можем попробовать это, набрав df новую ячейку и запустив ее, она распечатает все данные в нашем наборе данных в виде DataFrame для нас.
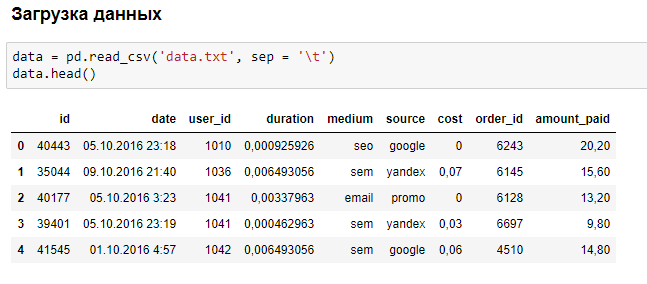
Но мы не всегда хотим видеть все данные, иногда просто хотим видеть первые несколько данных и имена их столбцов. Мы можем использовать df.head() функцию, чтобы напечатать первые пять столбцов и df.tail() распечатать последние пять. Вывод любого из двух будет выглядеть как таковой;
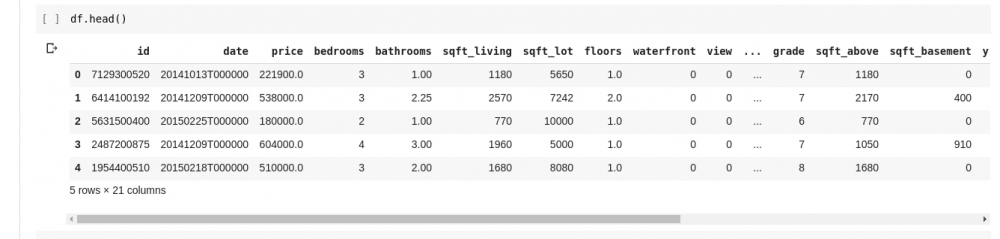
Если мы хотим проверить наличие связей между этими несколькими строками и столбцами данных, функция describe() поможет нам в этом.
Запуск df.describe() дает следующий вывод;
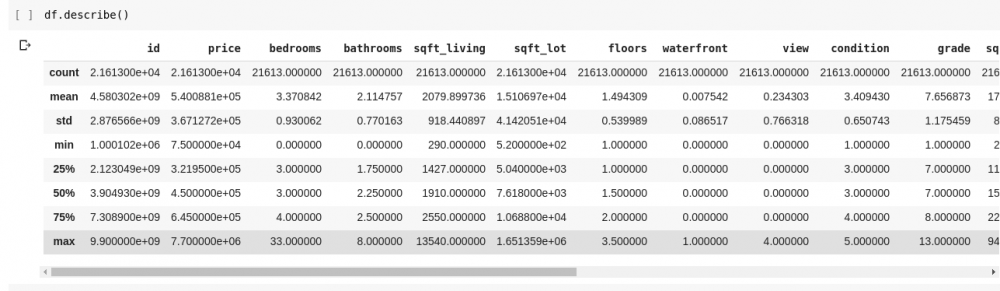
Сразу видим, что функция describe() дает среднее, стандартное отклонение, минимальное и максимальное значения.
Также можем проверить форму нашего 2D DataFrame, чтобы узнать, сколько у него строк и столбцов. Можем сделать это, используя df.shape() который возвращает кортеж в формате (строки, столбцы).
Мы также можем проверить имена всех столбцов в нашем DataFrame, используя df.columns().
Что если мы хотим выбрать только один столбец и вернуть все данные в нем? Это сделано способом, похожим на прорезание словаря. Введите следующий код в новую ячейку и запустите его
Приведенный выше код возвращает столбец цены, мы можем пойти дальше, сохранив его в новой переменной
Теперь мы можем выполнить любое другое действие, которое может быть выполнено в DataFrame с нашей ценовой переменной, поскольку оно является лишь подмножеством фактического DataFrame. Мы можем использовать такие функции, как df.head()df.shape() т.д.
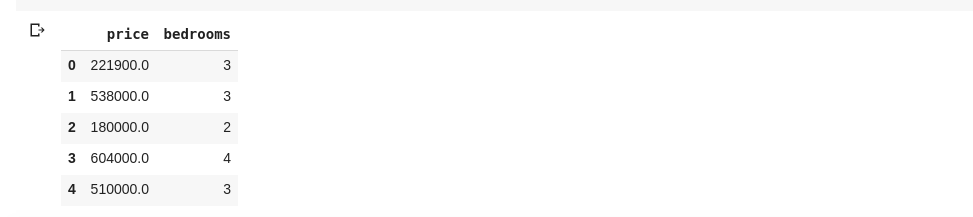
Также можем выбрать несколько столбцов, передав список имен столбцов в df как таковой
Приведенный выше выбор столбцов с именами «цена» и «спальни», если мы введем в data.head() новую ячейку, у нас будет следующее
Вышеупомянутый способ нарезки столбцов возвращает все элементы строк в этом столбце, что если мы хотим вернуть подмножество строк и подмножество столбцов из нашего набора данных? Это можно сделать с помощью iloc индексации и аналогично спискам Python. Таким образом, мы можем сделать что-то вроде
Который возвращает 3-й столбец от 50-го ряда до конца. Это довольно аккуратно и точно так же, как нарезка списков в Python.
Теперь давайте сделаем несколько действительно интересных вещей: в нашем наборе данных о ценах на жилье есть столбец, в котором указывается цена дома, а в другом столбце — количество спален в конкретном доме. Цена на жилье является постоянной величиной, поэтому возможно, что у нас нет двух домов с одинаковой ценой. Но количество спален несколько дискретно, поэтому у нас может быть несколько домов с двумя, тремя, четырьмя спальнями и т.д.
Что если мы хотим получить все дома с одинаковым количеством спален и определить среднюю цену каждой отдельной спальни? Это относительно легко сделать в Pandas:
Вышеупомянутые сначала группируют DataFrame по наборам данных с идентичным номером спальни, используя df.groupby() функцию, затем мы говорим, что мы даем нам только столбец спальни и используемmean() функцию, чтобы найти среднее значение каждого дома в наборе данных.
Что если мы хотим визуализировать вышесказанное? Мы хотели бы иметь возможность проверить, как меняется средняя цена каждого отдельного номера спальни? Нам просто нужно связать предыдущий код с plot() функцией:
У нас будет вывод, который выглядит таковым;
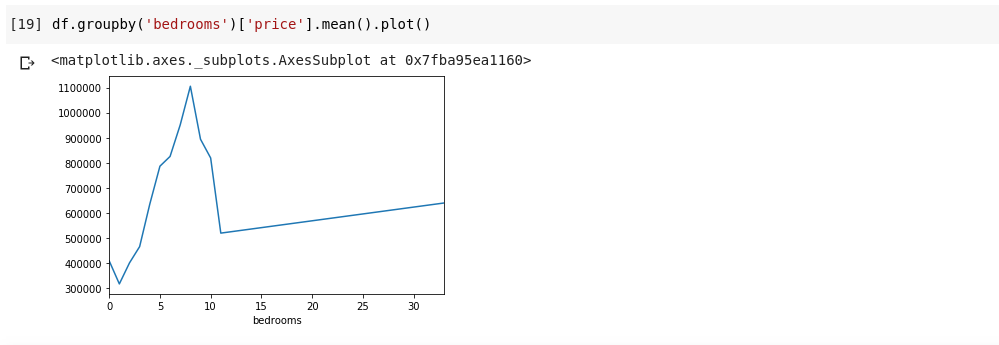
График показывает нам некоторые тенденции в данных. На горизонтальной оси у нас есть различное количество спален (обратите внимание, что более чем один дом может иметь Х количество спален). На вертикальной оси мы имеем среднее значение цен в отношении соответствующего количества спален на горизонтальной ось. Теперь мы можем сразу заметить, что дома с 5-10 спальнями стоят намного дороже, чем дома с 3 спальнями. Также станет очевидным, что дома с 7 или 8 спальнями стоят намного больше, чем дома с 15, 20 или даже 30 комнатами.
Информация, подобная вышеприведенной, объясняет, почему анализ данных очень важен, мы можем извлечь полезную информацию из данных, которые не сразу или совсем невозможно заметить без анализа.
Пошаговая инструкция по анализу данных на Python.
Структуры данных в Pandas
В Pandas есть 3 структуры данных, а именно:
Лучший способ различить три из них — это видеть, что один содержит несколько стеков другого. Итак, DataFrame — это стек Series, а Panel — это стек DataFrame.
Series — это одномерный массив.
Стек из нескольких Series составляет двухмерный DataFrame
Стек из нескольких DataFrames образует трехмерный Panel
Структура данных, с которой мы будем работать больше всего, — это двухмерный DataFrame, который также может быть средством представления по умолчанию для некоторых наборов данных, с которыми мы можем столкнуться.
Отсутствующие данные
Давайте предположим, что я провожу опрос, который состоит из серии вопросов. Я делюсь ссылкой на опрос с тысячами людей, чтобы они могли высказать свое мнение. Моя конечная цель — провести анализ данных на этих данных, чтобы я мог получить некоторые ключевые выводы из этих данных.
Теперь многое может пойти не так, некоторые геодезисты могут чувствовать себя неловко, отвечая на некоторые мои вопросы, и оставить это поле пустым. Многие люди могут сделать то же самое для нескольких частей моего опроса. Это не может считаться проблемой, но представьте, что если бы я собирал числовые данные в своем опросе, а часть анализа требовала, чтобы я получил либо сумму, среднее значение, либо какую-то другую арифметическую операцию. Несколько пропущенных значений приведут к большому количеству неточностей в моем анализе, я должен найти способ найти и заменить эти пропущенные значения некоторыми значениями, которые могут быть их близкой заменой.
Pandas предоставляют нам функцию для поиска пропущенных значений в вызываемом DataFrame isnull().
Оно возвращает DataFrame с логическими значениями, который сообщает нам, действительно ли изначально присутствующие данные отсутствовали. Вывод будет выглядеть таким:
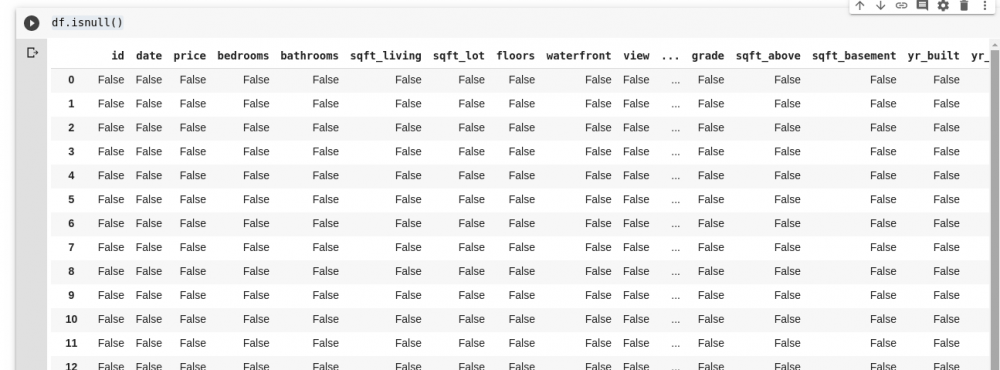
Нам нужен способ заменить все эти пропущенные значения, чаще всего выбор пропущенных значений можно принять за ноль. Иногда это может быть принято как среднее значение всех других данных или, возможно, среднее значение данных вокруг него, в зависимости от варианта использования анализируемых данных.
Чтобы заполнить все пропущенные значения в DataFrame, мы используем функцию fillna():
Выше мы заполняем все пустые данные значением ноль. Это может быть любой другой номер, который мы указали.
Важность анализа не может быть переоценена, он помогает нам получить ответы прямо из наших данных! Многие утверждают, что анализ данных — это новая нефть для цифровой экономики.
Все примеры в этой статье можно найти здесь.
Matplotlib
Matplotlib — низкоуровневая библиотека для создания двумерных диаграмм и графиков. С ее помощью можно построить любой график, но для сложной визуализации потребуется больше кода, чем в продвинутых библиотеках.
Библиотеки для интеллектуального анализа и обработки естественного языка
Полезные иблиотеки для работы с текстом, которые используются для извлечения данных из интернет-ресурсов и обработки естественного языка.
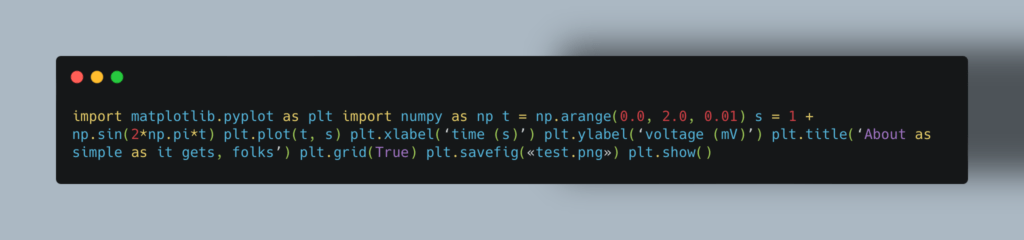
Scrapy
Библиотека используется для создания ботов-пауков, которые сканируют страницы сайтов и собирают структурированные данные: цены, контактную информацию и URL-адреса. Кроме этого, Scrapy может извлекать данные из API.
Пример кода для создания бота-паука:
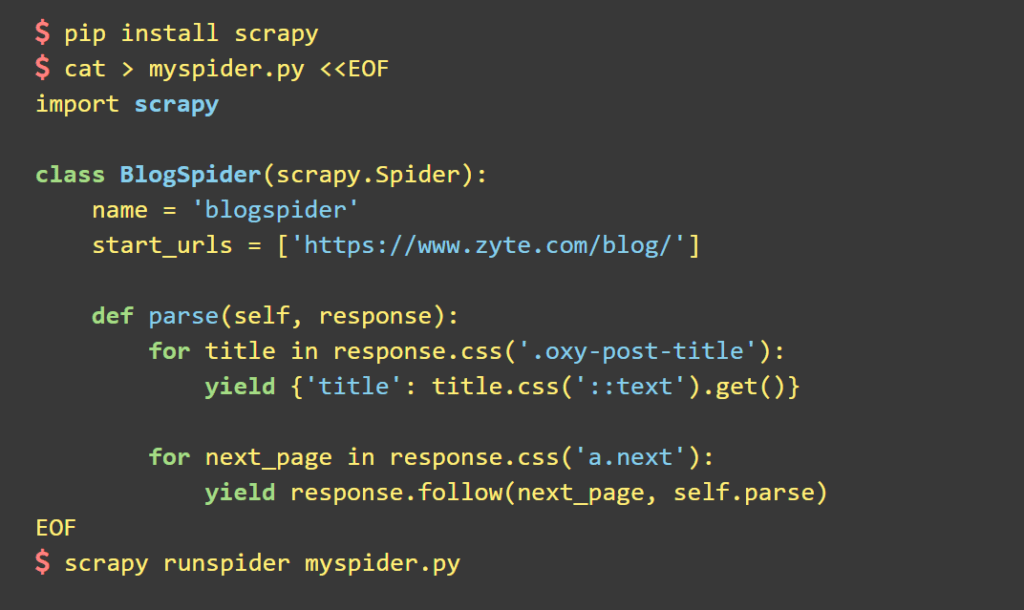
NLTK (Natural Language Toolkit)
Набор библиотек для обработки естественного языка. Основные функции: разметка текста, определение именованных объектов, отображение синтаксического дерева, раскрывающего части речи и зависимости.
Например, так выглядит обучение классификатора, который будет определять тональность текста:
Pattern
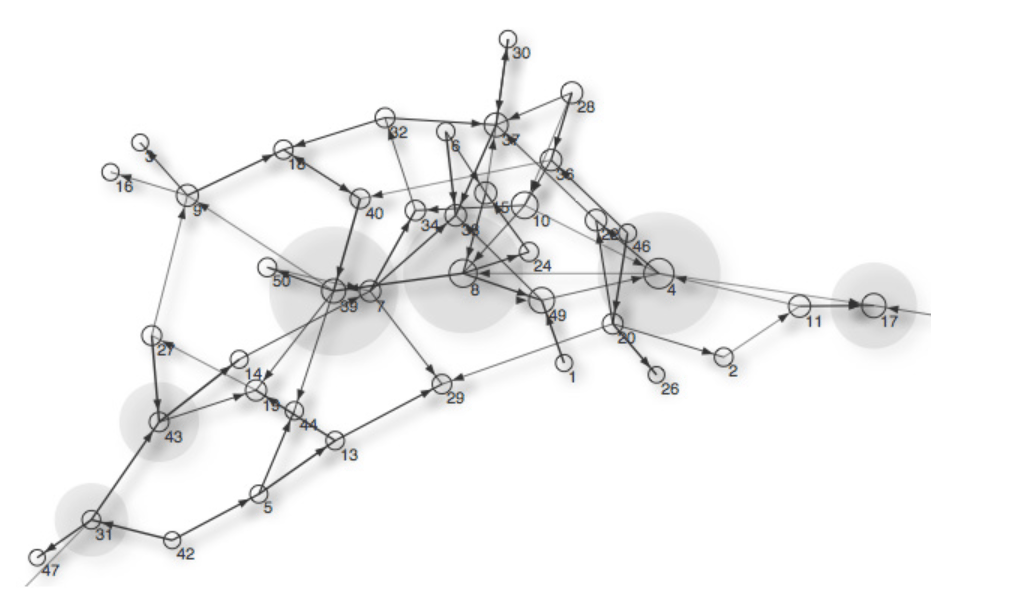
Пример визуализации графа:
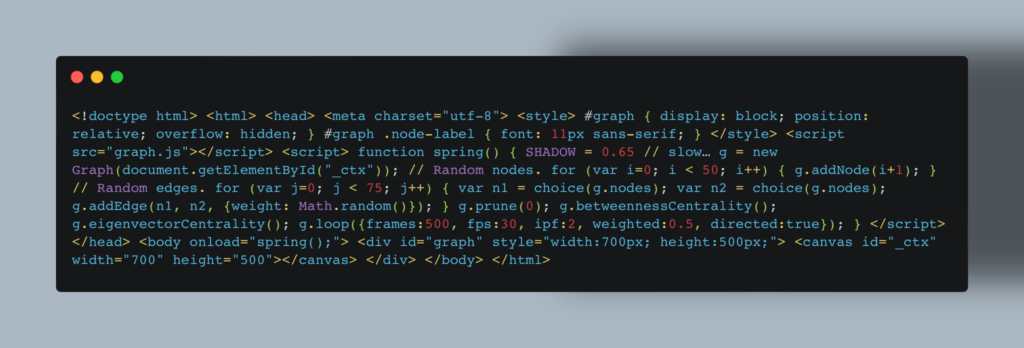
Библиотеки Python для визуализации
Библиотеки, которые пригодятся в визуализации данных и построении графиков.
Seaborn
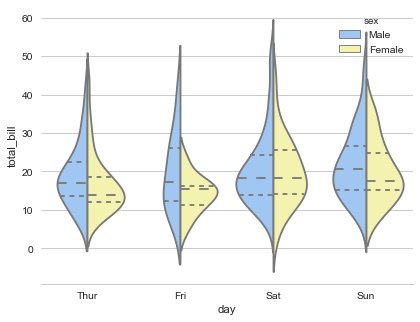
Библиотека более высокого уровня, чем matplotlib. С ее помощью проще создавать специфическую визуализацию: тепловые карты, временные ряды и скрипичные диаграммы. Пример визуализации:
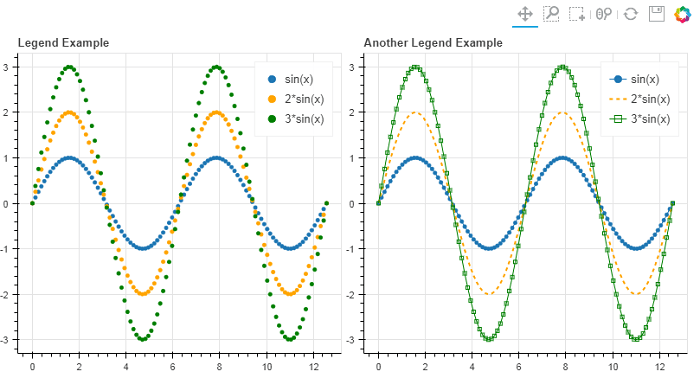
Bokeh
Создает интерактивные и масштабируемые графики в браузерах, используя виджеты JavaScript. Сложность графиков может быть разная: от стандартных диаграмм до сложных кастомизированных схем. Примеры визуализации:
Basemap
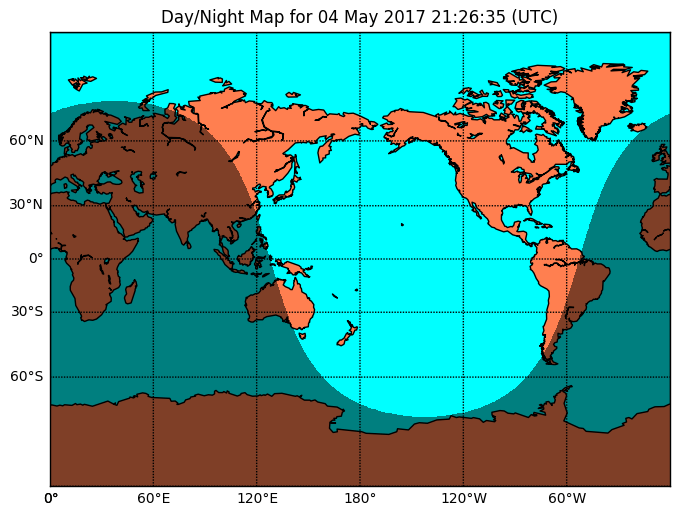
Basemap используется для создания карт. На ее основе сделана библиотека Folium, с помощью которой создают интерактивные карты в интернете. Пример карты:
NetworkX
Используется для создания и анализа графов и сетевых структур. Предназначена для работы со стандартными и нестандартными форматами данных.
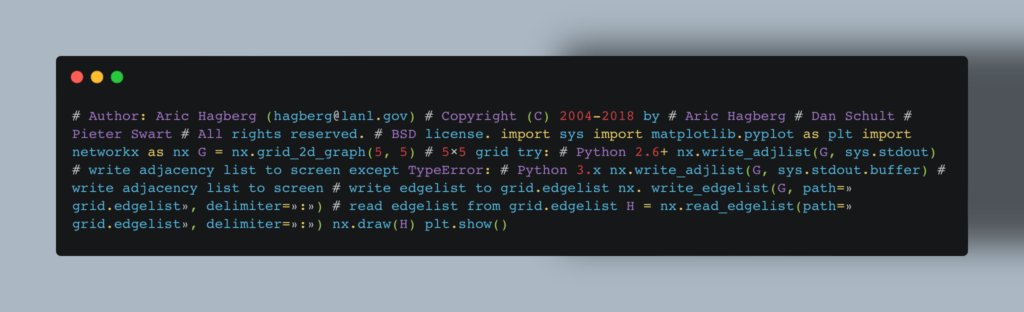
Это малая часть библиотек Python, но и их достаточно, чтобы на серьезном уровне анализировать данные, создавать и обучать нейронные сети и визуализировать результаты.
Требования и план разработки
При построении нужно предусмотреть добавление функций для анализа данных, если возникнет потребность расширить пул анализируемых параметров. Возможность вызывать, как отдельную функцию с конкретным анализом, так и все сразу. Функции должны перебирать каждый столбец в DateFrame.
Подумав над решением пришел к выводу, что понадобиться класс, в котором инициализируются переменные, которые будут доступны всем функциям. Графически вижу это так:
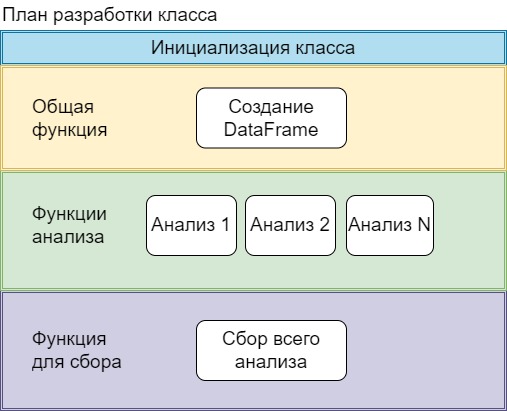
Графическое изображение плана разработки класса
Подумал, как выстроить алгоритм для анализа столбцов. На вход функция получает таблицу с данными, анализирует через цикл каждый столбец. По итогу должна родиться строка с результатом. Один столбец = одной строке с результатом.
Функция должна иметь возможность быть вызвана независимо от других, следовательно, чтобы удовлетворить это требование результатом работы (return) должен быть DateFrame
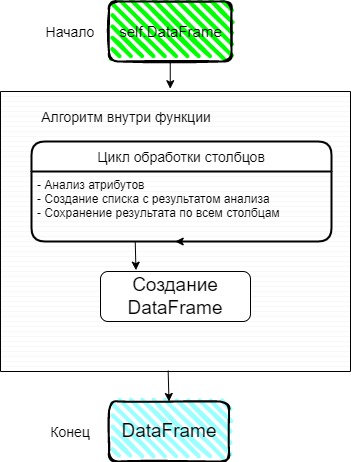
Графическое изображение алгоритма работы функции для анализа
Функция вывода всех результатов анализа, решил построить следующим образом
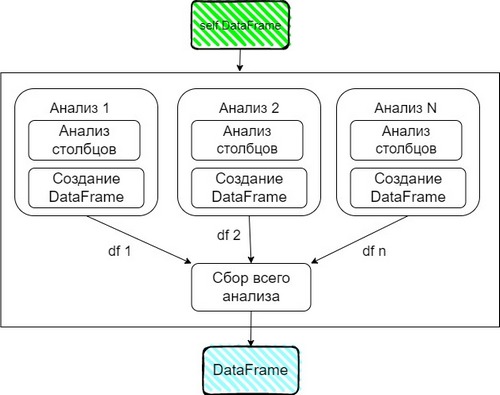
Графическое изображение алгоритма работы функции для сбора всего анализа
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре.
Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.
Библиотеки для работы с данными
Библиотеки Python для анализа данных, Machine Learning и обучения сложных нейронных сетей.
Scikit-learn
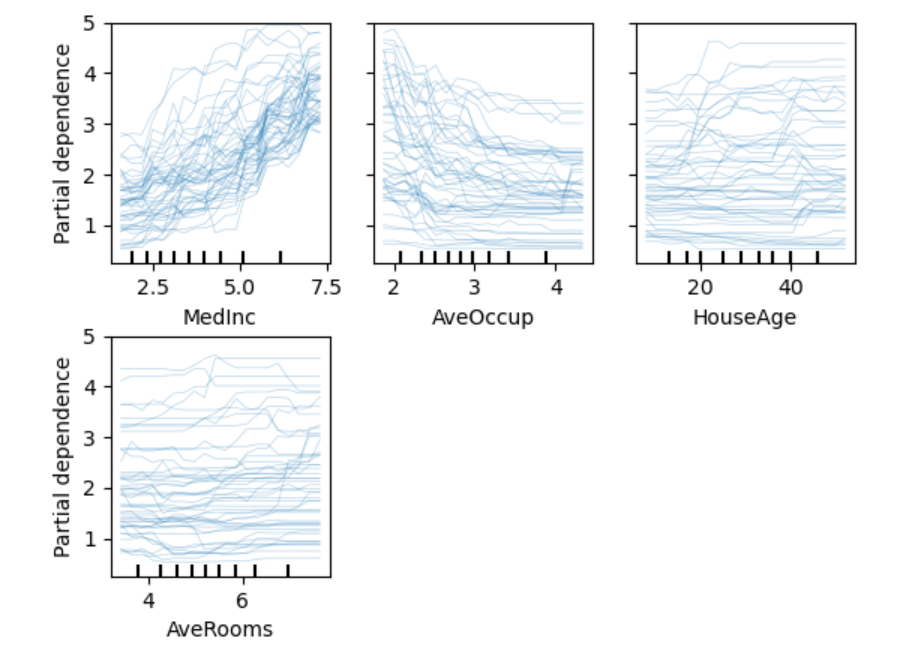
Scikit-learn основана на NumPy и SciPy. В ней есть алгоритмы для машинного обучения и интеллектуального анализа данных: кластеризации, регрессии и классификации. Это одна из самых лучших библиотек для компаний, работающих с огромным объемом данных — ее используют Evernote, OKCupid, Spotify и Birchbox.
Пример визуализации частичной зависимости стоимости домов в Калифорнии в зависимости от особенностей местности:

TensorFlow
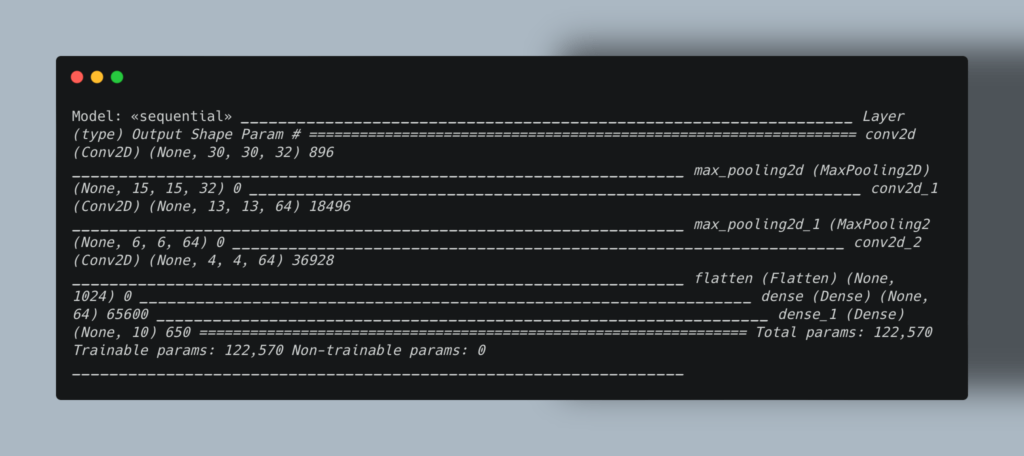
Библиотеку создали в Google, чтобы заменить DistBelief — фреймворк для обучения, настройки и тренировки нейронных сетей. Благодаря этой библиотеке Google может определять объекты на фотографиях, а приложение для распознавания голоса — понимать речь.
Пример архитектуры сверточной нейронной сети:
Keras
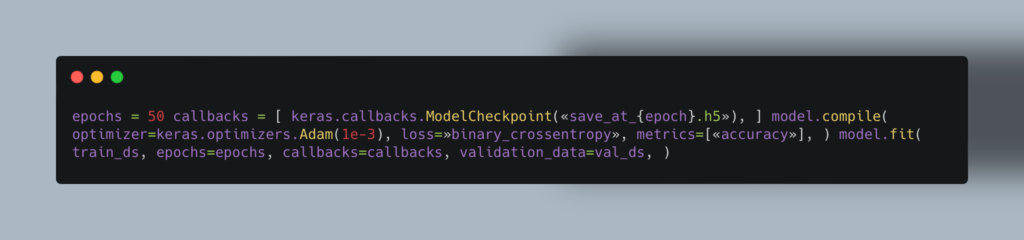
Библиотека глубокого обучения. Благодаря модульности и масштабированию она позволяет легко и быстро создавать прототипы. Keras поддерживает как сверточные и рекуррентные сети, так и их комбинации.
Пример кода обучения модели по классификации изображений:
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.

Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
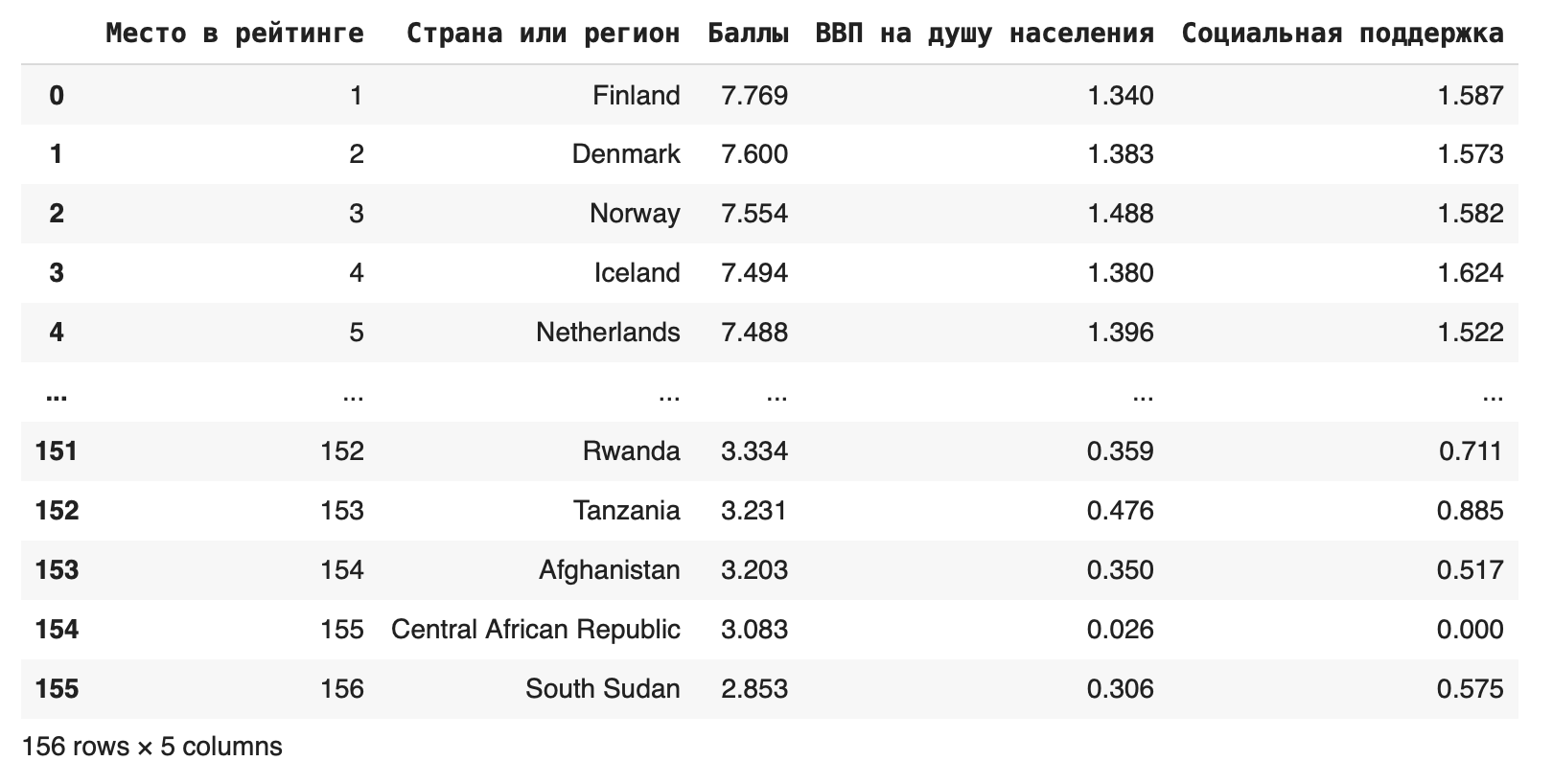
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.
3. Использовать метод iloc
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
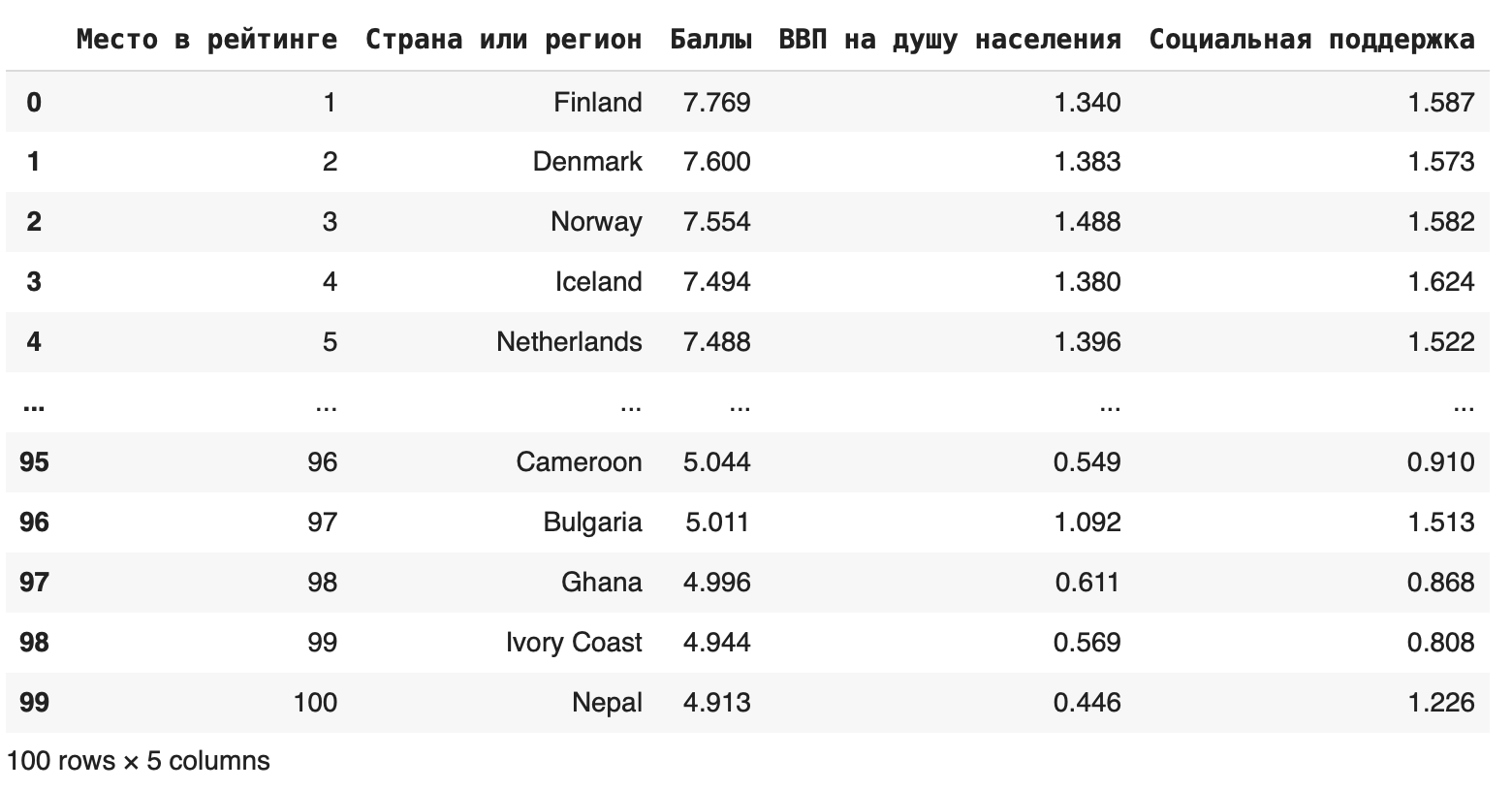
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов

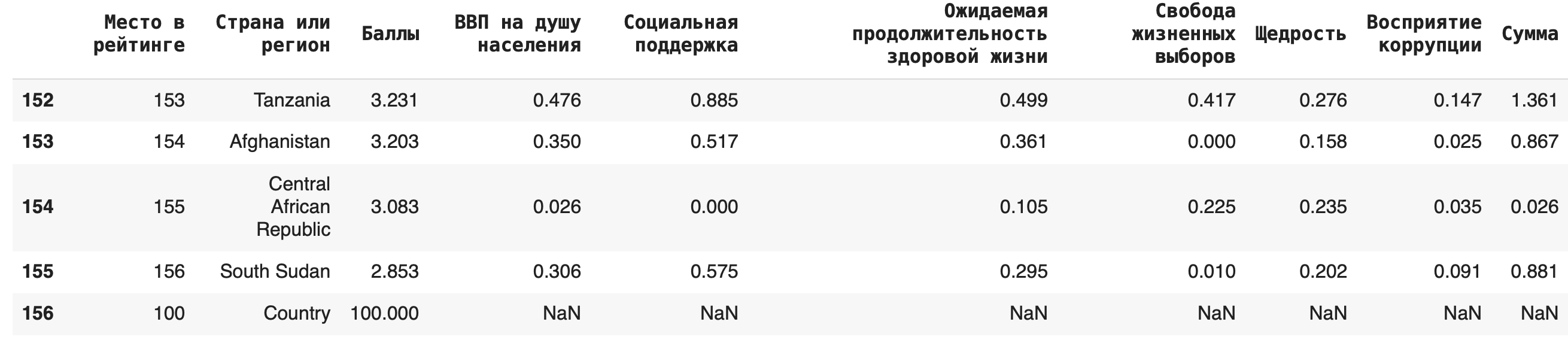
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
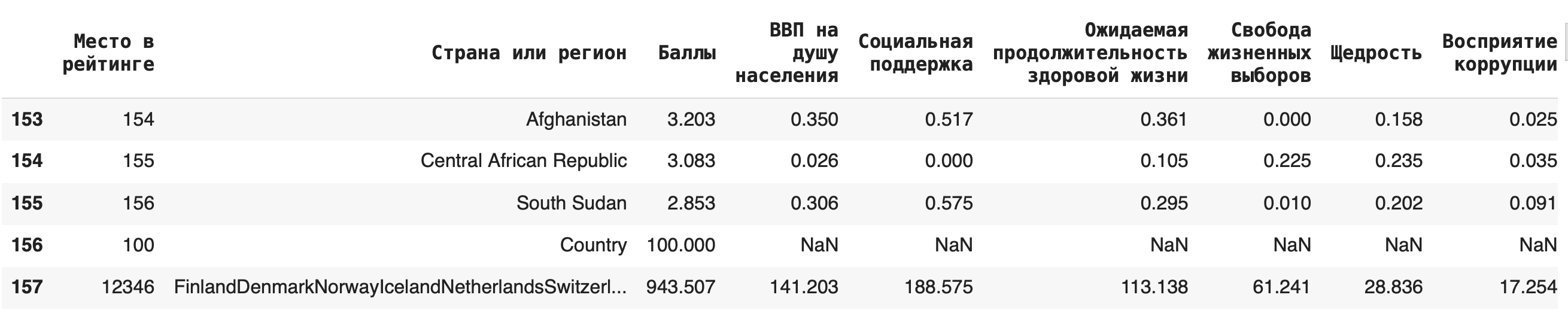
Удаление строк и столбцов
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
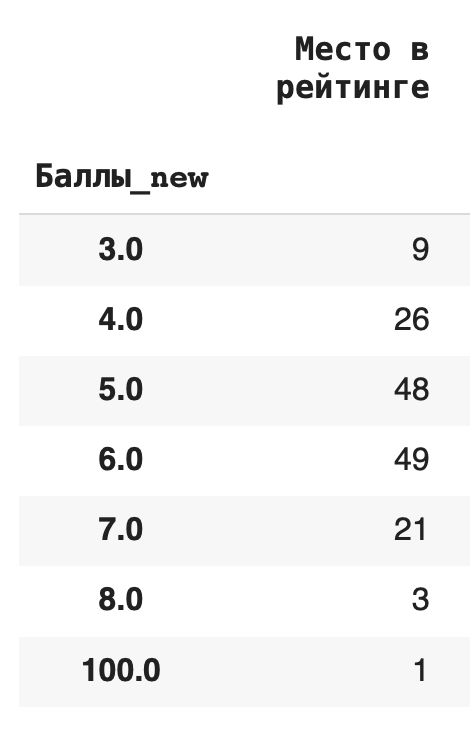
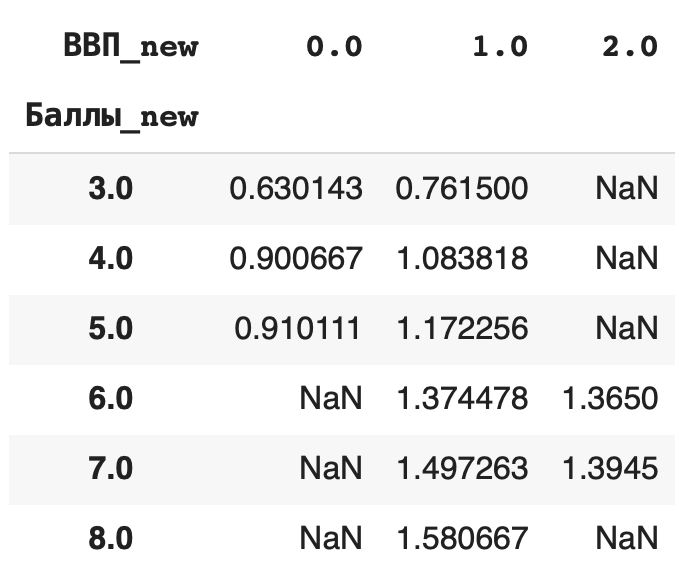
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count():df.groupby(‘Баллы_new’).count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
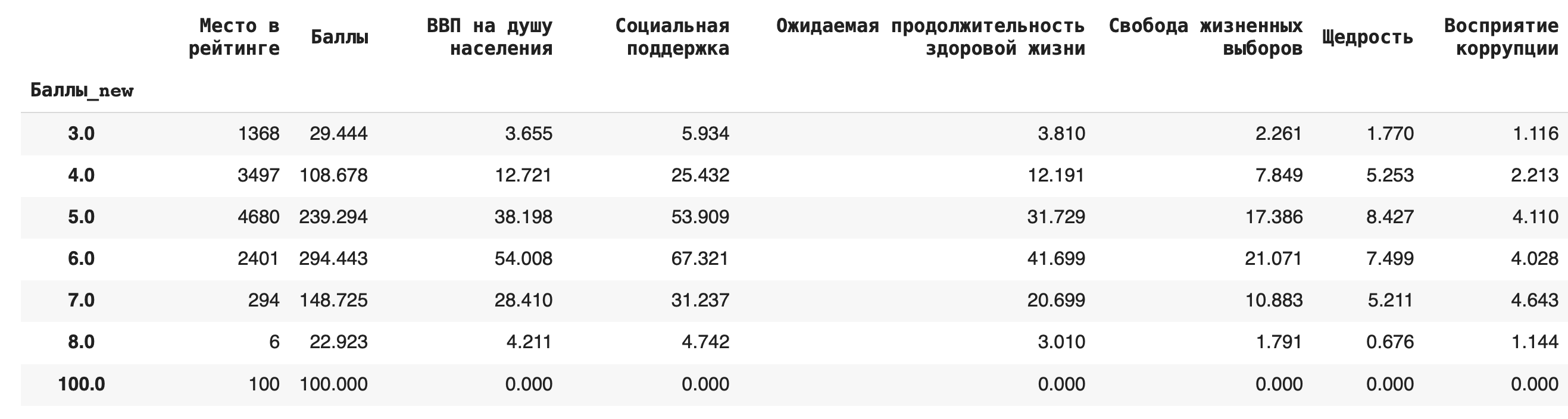
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum():df.groupby(‘Баллы_new’).sum()
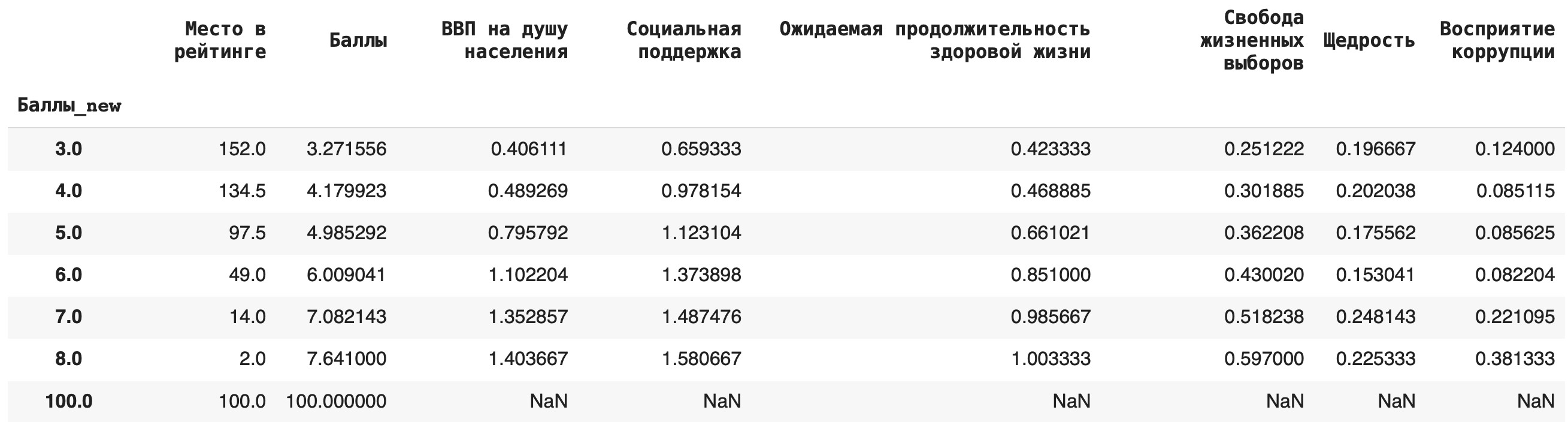
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean():df.groupby(‘Баллы_new’).mean()
4) Рассчитаем медиану. Для этого пишем команду median():df.groupby(‘Баллы_new’).median()
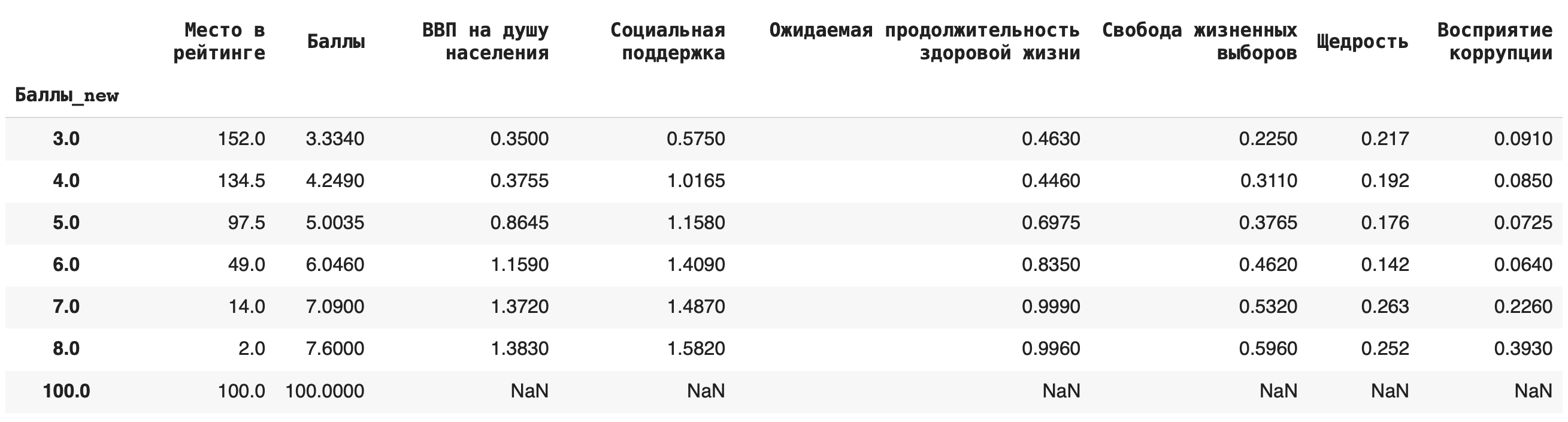
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
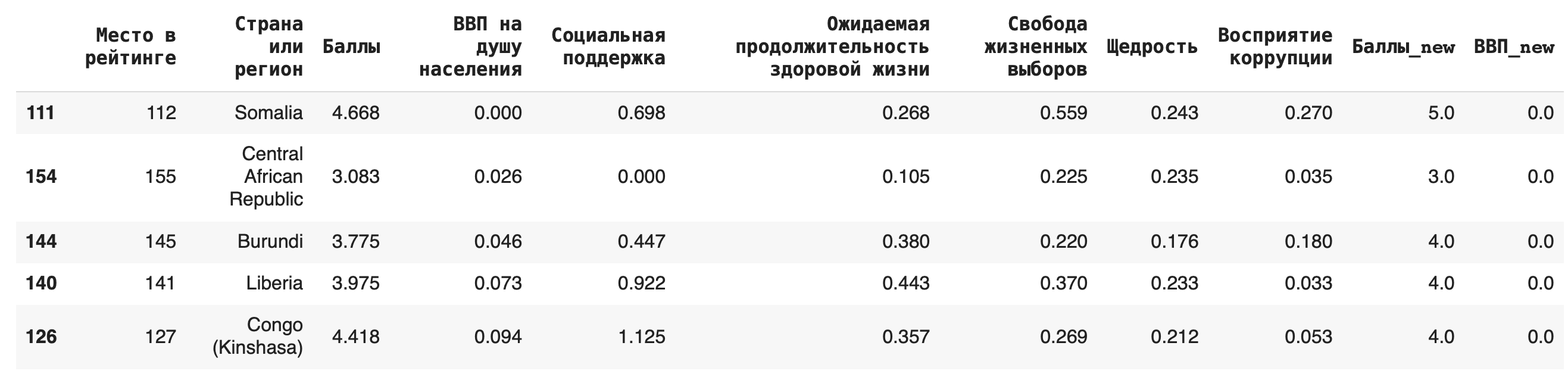
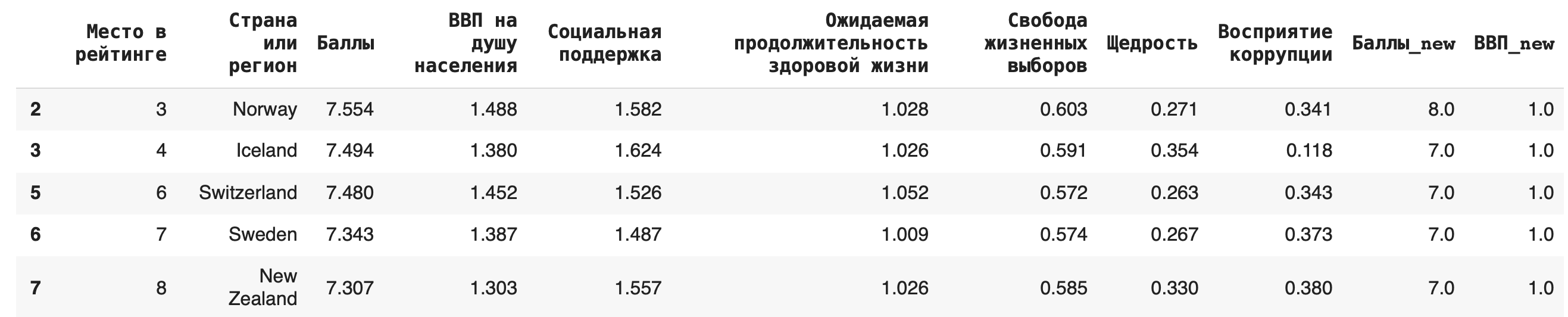
Сортировка данных
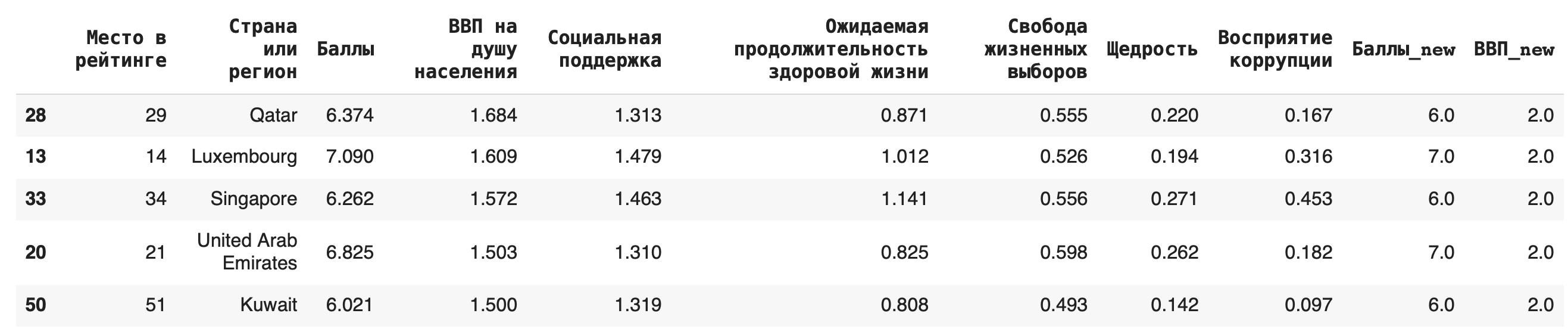
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = ‘ВВП на душу населения’, ascending=False)
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:



Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
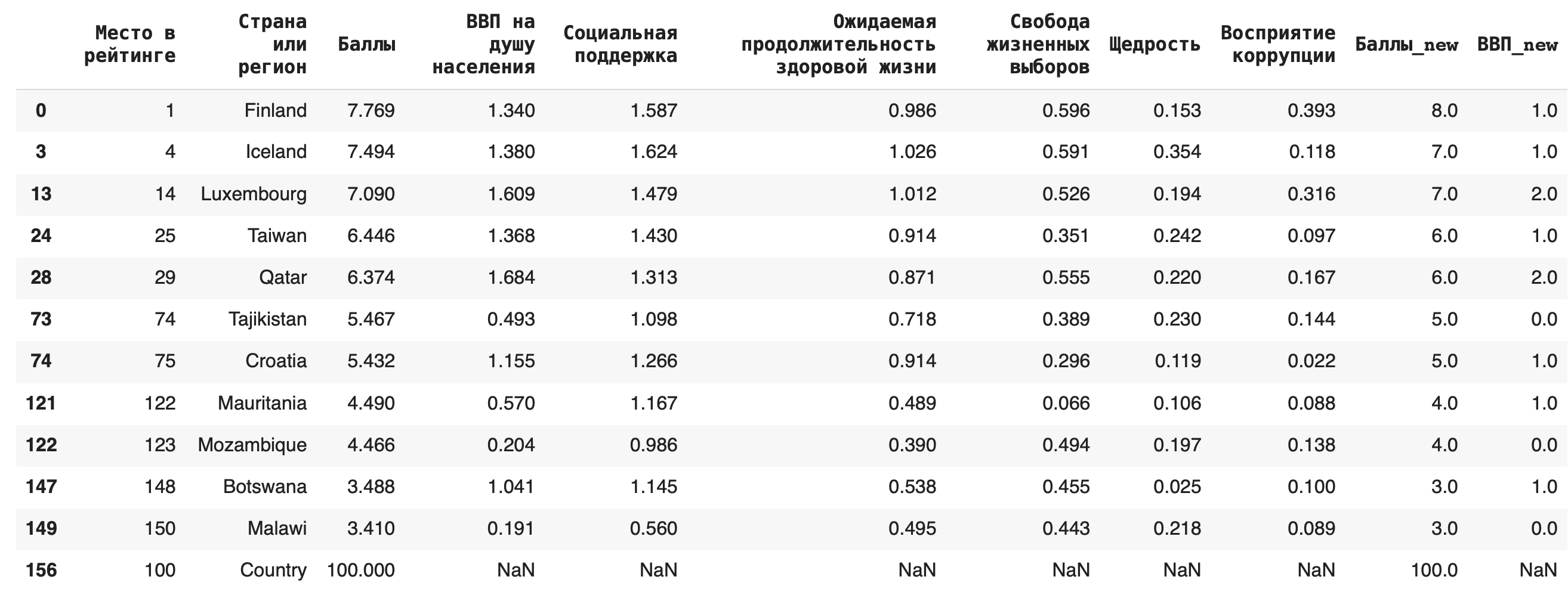
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
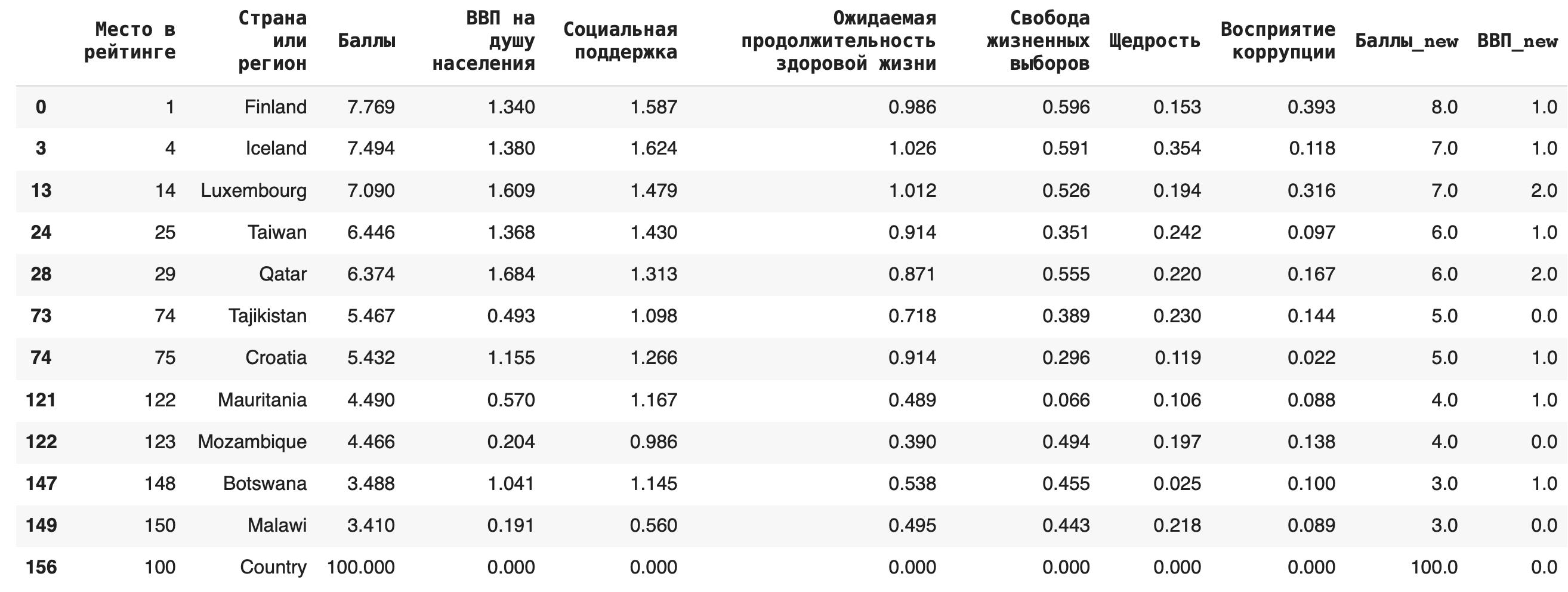
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
1) Обычный график по точкам.
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
3) Точечный график. df.plot.scatter(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
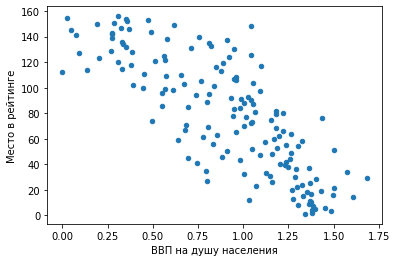
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv(‘WHR_2019.csv’)
Теперь с ним можно работать и в других программах.
Тест-симулятор по аналитике данных
Данное решение является для меня самым первым этапом анализа. Потенциальные проблемы или их отсутствие видны в таблицы. После этого можно начинать следующие шаги и сфокусироваться на требующих детальной разборки столбцах.
Код и данные на GitHub
Результат
Тестируем на реальных данных. Вызовем весь анализ. Размер таблицы (7043, 24)
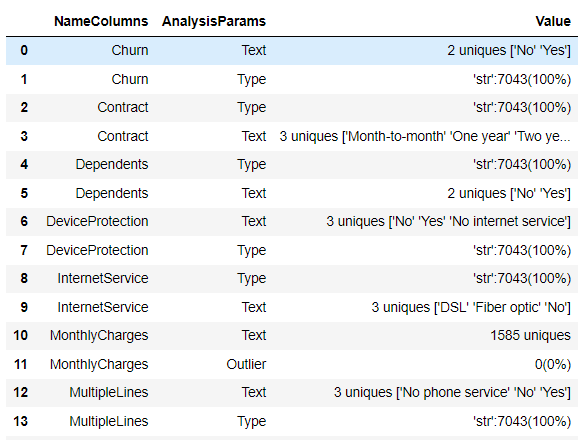
Вывод функции AnalysisOfDf
Посмотрим, как работает отдельно функция по анализу типов данных
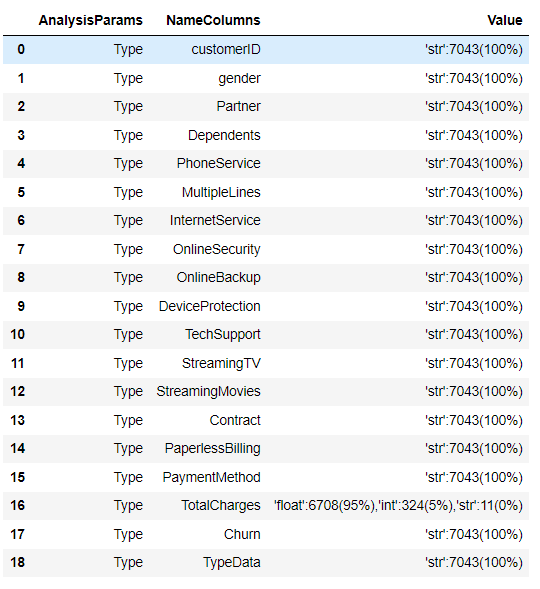
Вывод функции AnalysisOfType