
Время на прочтение
Технологии анализа текстовой информации стремительно меняются под влиянием машинного обучения. Нейронные сети из теоретических научных исследований перешли в реальную жизнь, и анализ текста активно интегрируется в программные решения. Нейронные сети способны решать самые сложные задачи обработки естественного языка, никого не удивляет машинный перевод, «беседа» с роботом в интернет-магазине, перефразирование, ответы на вопросы и поддержание диалога. Почему же Сири, Алекса и Алиса не хотят нас понимать, Google находит не то, что мы ищем, а машинные переводчики веселят нас примерами «трудностей перевода» с китайского на албанский? Ответ кроется в мелочах – в алгоритмах, которые правильно работают в теории, но сложно реализуются на практике. Научитесь применять методы машинного обучения для анализа текста в реальных задачах, используя возможности и библиотеки Python. От поиска модели и предварительной обработки данных вы перейдете к приемам классификации и кластеризации текстов, затем приступите к визуальной интерпретации, анализу графов, а после знакомства с приемами масштабирования научитесь использовать глубокое обучение для анализа текста.
- О чем рассказывается в этой книге
- Кому адресована эта книга
- Отрывок. Извлечение графов из текста
- Создание социального графа
- Графы свойств
- Об авторах
- Техники предварительной обработки текста в NLP с использованием NLTK
- Удаление стоп-слов
- Стемминг
- Лемматизация
- Анализ настроений
- Простая классификация с использованием предварительно обученных данных
- Классификация с использованием настраиваемых тренировочных данных
- Анализ настроений с использованием токенизатора и списка стоп-слов
- Модель BoW
- Создание BoW с NLTK и использование его для классификации
- Введение
- Постановка задачи
- Предварительная обработка данных
- Анализ данных
- Построение модели
- Заключение
О чем рассказывается в этой книге
В этой книге рассказывается о применении методов машинного обучения для анализа текста с использованием только что перечисленных библиотек на Python. Прикладной характер книги предполагает, что мы сосредоточим свое внимание не на академической лингвистике или статистических моделях, а на эффективном развертывании моделей, обученных на тексте внутри приложения.
Предлагаемая нами модель анализа текста напрямую связана с процессом машинного обучения — поиска модели, состоящей из признаков, алгоритма и гиперпараметров, которая давала бы лучшие результаты на обучающих данных, с целью оценки неизвестных данных. Этот процесс начинается с создания обучающего набора данных, который в сфере анализа текстов называют корпусом. Затем мы исследуем методы извлечения признаков и предварительной обработки для представления текста в виде числовых данных, понятных методам машинного обучения. Далее, познакомившись с некоторыми основами, мы перейдем к исследованию приемов классификации и кластеризации текста, рассказ о которых завершает первые главы книги.
В последующих главах основное внимание уделяется расширению моделей более богатыми наборами признаков и созданию приложений анализа текстов. Сначала мы посмотрим, как можно представить и внедрить контекст в виде признаков, затем перейдем к визуальной интерпретации для управления процессом выбора модели. Потом мы посмотрим, как анализировать сложные отношения, извлекаемые из текста с применением приемов анализа графов. После этого обратим свой взгляд в сторону диалоговых агентов и углубим наше понимание синтаксического и семантического анализа текста. В заключение книги будет представлено практическое обсуждение приемов масштабирования анализа текста в многопроцессорных системах с применением Spark, и, наконец, мы рассмотрим следующий этап анализа текста: глубокое обучение.
Кому адресована эта книга
Эта книга адресована программистам на Python, интересующимся применением методов обработки естественного языка и машинного обучения в своих программных продуктах. Мы не предполагаем наличия у наших читателей специальных академических или математических знаний и вместо этого основное внимание уделяем инструментам и приемам, а не пространным объяснениям. В первую очередь в этой книге обсуждается анализ текстов на английском языке, поэтому читателям пригодится хотя бы базовое знание грамматических сущностей, таких как существительные, глаголы, наречия и прилагательные, и того, как они связаны между собой. Читатели, не имеющие опыта в машинном обучении и лингвистике, но обладающие навыками программирования на Python, не будут чувствовать себя потерянными при изучении понятий, которые мы представим.
Отрывок. Извлечение графов из текста
Извлечение графа из текста — сложная задача. Ее решение обычно зависит от предметной области, и, вообще говоря, поиск структурированных элементов в неструктурированных или полуструктурированных данных определяется контекстно-зависимыми аналитическими вопросами.
Мы предлагаем разбить эту задачу на более мелкие шаги, организовав простой процесс анализа графов, как показано на рис. 9.3.
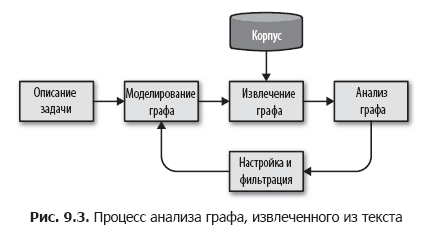
В этом процессе мы сначала определяем сущности и связи между ними, исходя из описания задачи. Далее, на основе этой схемы определяем методику выделения графа из корпуса, используя метаданные, документы в корпусе и словосочетания или лексемы в документах для извлечения данных и связей между ними. Методика выделения графа — это циклический процесс, который можно применить к корпусу, сгенерировать граф и сохранить этот граф на диск или в память для дальнейшей аналитической обработки.
Создание социального графа
Рассмотрим наш корпус новостных статей и задачу моделирования связей между разными сущностями в тексте. Если рассматривать вопрос различий в охвате между разными информационными агентствами, можно построить граф из элементов, представляющих названия публикаций, имена авторов и источники информации. А если целью является объединение упоминаний одной сущности во множестве статей, в дополнение к демографическим деталям наши сети могут зафиксировать форму обращения (уважительную и другие). Интересующие нас сущности могут находиться в структуре самих документов или содержаться непосредственно в тексте.
Допустим, наша цель — выяснить людей, места и все что угодно, связанные друг с другом в наших документах. Иными словами, нам нужно построить социальную сеть, выполнив серию преобразований, как показано на рис. 9.4. Начнем конструирование графа с применения класса EntityExtractor, созданного в главе 7. Затем добавим преобразователи, один из которых отыскивает пары связанных сущностей, а второй преобразует эти пары в граф.
Поиск пар сущностей
Наш следующий шаг — создание класса EntityPairs, который получает документы в виде списков сущностей (созданных классом EntityExtractor из главы 7). Этот класс должен действовать как преобразователь в конвейере Pipeline из Scikit-Learn, а значит, наследовать классы BaseEstimator и TransformerMixin, как рассказывалось в главе 4. Предполагается, что сущности в одном документе безусловно связаны друг с другом, поэтому добавим метод pairs, использующий функцию itertools.permutations для создания всех возможных пар сущностей в одном документе. Наш метод transform будет вызывать pairs для каждого документа в корпусе:
Теперь можно последовательно извлечь сущности из документов и составить пары. Но мы пока не можем отличить пары сущностей, встречающихся часто, от пар, встречающихся только один раз. Мы должны как-то закодировать вес связи между сущностями в каждой паре, чем мы и займемся в следующем разделе.
Графы свойств
Математическая модель графа определяет только наборы узлов и ребер и может быть представлена в виде матрицы смежности (adjacency matrix), которой можно пользоваться в самых разных вычислениях. Но она не поддерживает механизм моделирования силы или типов связей. Появляются ли две сущности только в одном документе или во многих? Встречаются ли они вместе в статьях определенного жанра? Для поддержки подобных рассуждений нам нужен некий способ, позволяющий сохранить значимые свойства в узлах и ребрах графа.
Модель графа свойств позволяет встроить в граф больше информации, тем самым расширяя наши возможности. В графе свойств узлами являются объекты с входящими и исходящими ребрами и, как правило, содержащие поле type, напоминая таблицу в реляционной базе данных. Ребра — это объекты, определяющие начальную и конечную точки; эти объекты обычно содержат поле label, идентифицирующее тип связи, и поле weight, определяющее силу связи. Применяя графы для анализа текста, в роли узлов мы часто используем существительные, а в роли ребер — глаголы. После перехода к этапу моделирования это позволит нам описать типы узлов, метки связей и предполагаемую структуру графа.
Об авторах
Бенджамин Бенгфорт (Benjamin Bengfort) — специалист в области data science, живущий в Вашингтоне, внутри кольцевой автострады, но полностью игнорирующий политику (обычное дело для округа Колумбия) и предпочитающий заниматься технологиями. В настоящее время работает над докторской диссертацией в Университете штата Мериленд, где изучает машинное обучение и распределенные вычисления. В его лаборатории есть роботы (хотя это не является его любимой областью), и к его большому огорчению, помощники постоянно вооружают этих роботов ножами и инструментами, вероятно, с целью победить в кулинарном конкурсе. Наблюдая, как робот пытается нарезать помидор, Бенджамин предпочитает сам хозяйничать на кухне, где готовит французские и гавайские блюда, а также шашлыки и барбекю всех видов. Профессиональный программист по образованию, исследователь данных по призванию, Бенджамин часто пишет статьи, освещающие широкий круг вопросов — от обработки естественного языка до исследования данных на Python и применения Hadoop и Spark в аналитике.
Д-р Ребекка Билбро (Dr. Rebecca Bilbro) — специалист в области data science, программист на Python, учитель, лектор и автор статей; живет в Вашингтоне (округ Колумбия). Специализируется на визуальной оценке результатов машинного обучения: от анализа признаков до выбора моделей и настройки гиперпараметров. Проводит исследования в области обработки естественного языка, построения семантических сетей, разрешения сущностей и обработки информации с большим количеством измерений. Как активный участник сообщества пользователей и разработчиков открытого программного обеспечения, Ребекка с удовольствием сотрудничает с другими разработчиками над такими проектами, как Yellowbrick (пакет на языке Python, целью которого является прогнозное моделирование на манер черного ящика). В свободное время часто катается на велосипедах с семьей или практикуется в игре на укулеле. Получила докторскую степень в Университете штата Иллинойс, в Урбана-Шампейн, где занималась исследованием практических приемов коммуникации и визуализации в технике.
Для Хаброжителей скидка 20% по купону — Python
По факту оплаты бумажной версии книги на e-mail высылается электронная версия книги.
P. S.: 7% от стоимости книги пойдет на перевод новых компьютерных книг, список сданных в типографию книг здесь.
По кнопке выше «Купить бумажную книгу» можно купить эту книгу с доставкой по всей России и похожие книги по самой лучшей цене в бумажном виде на сайтах официальных интернет магазинов Лабиринт, Озон, Буквоед, Читай-город, Литрес, My-shop, Book24, Books.ru.
On the buttons above you can buy the book in official online stores Labirint, Ozon and others. Also you can search related and similar materials on other sites.
Прикладной анализ текстовых данных на Python, Машинное обучение и создание приложений обработки естественного языка, Бенгфорт Б., Билбро Р., Охеда Т., 2019.
Технологии анализа текстовой информации стремительно меняются под влиянием машинного обучения. Нейронные сети из теоретических научных исследований перешли в реальную жизнь, и анализ текста активно интегрируется в программные решения. Нейронные сети способны решать самые сложные задачи обработки естественного языка, никого не удивляет машинный перевод, «беседа» с роботом в интернет-магазине, перефразирование, ответы на вопросы и поддержание диалога. Почему же Сири, Алекса и Алиса не хотят нас понимать. Google находит не то. что мы ищем, а машинные переводчики веселят нас примерами «трудностей перевода» с китайского на албанский? Ответ кроется в мелочах — в алгоритмах, которые правильно работают в теории, но сложно реализуются на практике. Научитесь применять методы машинного обучения для анализа текста в реальных задачах, используя возможности и библиотеки Python. От поиска модели и предварительной обработки данных вы перейдете к приемам классификации и кластеризации текстов, затем приступите к визуальной интерпретации, анализу графов, а после знакомства с приемами масштабирования научитесь использовать глубокое обучение для анализа текста.
Естественные языки и вычисления. Приложения, использующие приемы обработки естественного языка для анализа текстовых и аудиоданных, становятся неотъемлемой частью нашей жизни. От нашего имени они просматривают огромные объемы информации в Сети и предлагают новые и персонализированные механизмы взаимодействия человека с компьютерами. Эти приложения настолько распространены, что мы привыкли к широкому спектру закулисных инструментов: от спам-фильтров, следящих за нашим почтовым трафиком, до поисковых систем, которые ведут нас прямо туда, куда мы хотим попасть, и виртуальных помощников, всегда готовых выслушать и ответить.
Информационные продукты с поддержкой анализа естественного языка находятся на пересечении экспериментальных исследований и практической разработки ПО. Приложения, анализирующие речь и текст, взаимодействуют непосредственно с пользователем, чьи ответы обеспечивают обратную связь, которая оказывает влияние и на приложение, и на результаты анализа. Этот благотворный цикл часто начинается с самого простого, но с течением времени может перерасти в мощную систему, возвращающую ценные результаты.
Как ни странно, даже при том, что потенциальные возможности внедрения анализа естественного языка в приложения продолжают увеличиваться, непропорционально большое количество внедрений осуществляется крупными игроками. Но почему этим не занимаются другие? Возможно, отчасти потому, что по мере распространения этих возможностей они становятся все менее заметными, маскируя сложность их реализации. А также потому, что развитие науки о данных еще не достигло уровня, необходимого для проникновения в культуру разработки программного обеспечения.
Купить
.
Дата публикации: 25.02.2020 06:46 UTC
учебник по программированию :: программирование :: Бенгфорт :: Билбро :: Охеда
Следующие учебники и книги:
Технологии анализа текстовой информации стремительно меняются под влиянием машинного обучения. Нейронные сети из теоретических научных исследований перешли в реальную жизнь, и анализ текста активно интегрируется в программные решения. Нейронные сети способны решать самые сложные задачи обработки естественного языка, никого не удивляет машинный перевод, «беседа» с роботом в интернет-магазине, перефразирование, ответы на вопросы и поддержание диалога. Почему же Сири, Алекса и Алиса не хотят нас понимать, Google находит не то, что мы ищем, а машинные переводчики веселят нас примерами «трудностей перевода» с китайского на албанский? Ответ кроется в мелочах — в алгоритмах, которые правильно работают в теории, но сложно реализуются на практике. Научитесь применять методы машинного обучения для анализа текста в реальных задачах, используя возможности и библиотеки Python. От поиска модели и предварительной обработки данных вы перейдете к приемам классификации и кластеризации текстов, затем приступите к визуальной интерпретации, анализу графов, а после знакомства с приемами масштабирования научитесь использовать глубокое обучение для анализа текста.
Сложности компьютерной обработки естественного языка.
Естественные языки определяются не правилами, а контекстом использования, который требуется реконструировать для компьютерной обработки. Часто мы сами определяем значения используемых слов, хотя и совместно с другими участниками беседы. Словом «краб» мы можем обозначить морское животное или человека с унылым нравом или имеющего характерную привычку двигаться бочком, но при этом оба — говорящий/автор и слушатель/читатель — должны согласиться с общим пониманием в ходе диалога. Поэтому язык обычно ограничивается обществом и регионом — передать смысл часто намного проще людям, имеющим жизненный опыт, похожий на ваш.
Вступление. Глава 1. Естественные языки и вычисления. Глава 2. Создание собственного корпуса. Глава 3. Предварительная обработка и преобразование корпуса. Глава 4. Конвейеры векторизации и преобразования. Глава 5. Классификация в текстовом анализе. Глава 6. Кластеризация для выявления сходств в тексте. Глава 7. Контекстно-зависимый анализ текста. Глава 8. Визуализация текста. Глава 9. Графовые методы анализа текста. Глава 10. Чат-боты. Глава 11. Масштабирование анализа текста. Глава 12. Глубокое обучение и не только. Глоссарий.
Купить
.
Дата публикации: 12.11.2020 13:11 UTC
Бенгфорт :: Билбро :: Охеда :: 2019 :: Python :: анализ :: данные

NLTK предлагает удобные инструменты для множества задач NLP: токенизация, стемминг, лемматизация, морфологический и синтаксический анализ, а также анализ настроений. Библиотека идеально подходит как для начинающих, так и для опытных разработчиков, предоставляя интуитивно понятный интерфейс и обширную документацию.
В NLTK включены корпуса текстов и словарные ресурсы, такие как WordNet, позволяющие работать с огромным объемом текстовых данных. Это делает NLTK мощным инструментом для анализа и обработки текста на разных языках.
NLTK — это свободно распространяемая библиотека Python, разработанная для работы с человеческим языком. Это комплексный набор инструментов, предназначенный для символьной и статистической обработки естественного языка. Она предоставляет легкий доступ к более чем 50 корпусам текстов и лексическим ресурсам, таким как WordNet, а также набор библиотек для классификации, токенизации, стемминга, метки частей речи, синтаксического анализа и семантического рассуждения.
Откройте командную строку или терминал и выполните следующую команду:
pip install nltk
NLTK предоставляет доступ к множеству текстовых корпусов и предварительно обученных моделей, которые могут быть полезны в различных задачах NLP. Эти данные не устанавливаются автоматически с библиотекой, поэтому их нужно загрузить отдельно. Для этого используйте следующий код:
Команда nltk.download(‘popular’) загружает наиболее часто используемые корпуса и модели. Если вам требуются конкретные ресурсы, вы можете загрузить их, заменив ‘popular’ на соответствующее название. Например, для загрузки WordNet используйте nltk.download(‘wordnet’).
Если вы видите список английских стоп-слов, значит, библиотека NLTK установлена правильно.
Техники предварительной обработки текста в NLP с использованием NLTK
Токенизация — это процесс разбиения текста на более мелкие части, такие как слова или предложения. Это первый шаг в анализе текста, который позволяет преобразовать непрерывный текст в дискретные элементы, с которыми можно работать отдельно. Этот процесс помогает в выявлении ключевых слов и фраз, а также в упрощении последующего анализа текста.
Токенизация полезна в задачах, где необходимо анализировать отдельные слова или фразы, например, при определении ключевых слов в тексте, анализе частотности слов или при обучении моделей машинного обучения для классификации текста.
Удаление стоп-слов
Стоп-слова — это общеупотребительные слова в языке, которые обычно несут мало смысловой нагрузки (например, «и», «в», «на»). Их удаление позволяет сократить объем данных для анализа и сосредоточиться на более значимых словах, что повышает точность и эффективность обработки текста.
Удаление стоп-слов часто юзается в задачах обработки текста, таких как анализ настроений, классификация текстов, создание облаков слов и в информационном поиске, где важно выделить ключевую информацию из текста.
Стемминг
Стемминг — это процесс сведения слов к их основной (корневой) форме, удаляя окончания и суффиксы. Это помогает уменьшить сложность текста и улучшить производительность алгоритмов анализа.
Стемминг наиболее полезен в задачах, где важно уменьшить разнообразие словоформ, например, при индексации текста для поисковых систем, в аналитике текстов большого объема и при обучении моделей машинного обучения для классификации или кластеризации текстов.
Лемматизация
В отличие от стемминга, лемматизация сводит слова к их лемме — это более сложный процесс, который учитывает морфологический анализ слов. Лемматизация более точно обрабатывает слова, приводя их к словарной форме.
Лемматизация важна в задачах, где требуется высокая точность обработки текста, таких как машинный перевод, семантический анализ текста и создание систем вопросов-ответов, где важно точно понимать значение слов в контексте.
Анализ настроений
Анализ настроений, иногда называемый «определением тональности», включает использование NLP, статистических или машинно-обученных алгоритмов для изучения, идентификации и извлечения информации о настроениях из текстов. Он может быть столь же простым, как определение положительной или отрицательной окраски отзыва, или настолько сложным, как определение более тонких эмоциональных состояний, таких как ирония или разочарование.
Анализ настроений не без проблем. Одна из основных сложностей заключается в интерпретации сарказма, иронии и фигуративного языка. Например, фраза «Ну да, конечно, мне очень понравилось, когда мой телефон перестал работать» на самом деле выражает разочарование, хотя на первый взгляд может показаться положительной. Распознавание таких тонкостей требует продвинутых алгоритмов и, часто, контекстуального анализа.
Анализ настроений (или сентимент-анализ) в NLTK часто сводится к классификации текста на позитивный или негативный. Чтобы реализовать анализ настроений, можно использовать разные подходы.
Простая классификация с использованием предварительно обученных данных
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download(‘vader_lexicon’)
sia = SentimentIntensityAnalyzer()
text = «NLTK is amazing for natural language processing!»
print(sia.polarity_scores(text))
Классификация с использованием настраиваемых тренировочных данных
from textblob import TextBlob
import nltk
nltk.download(‘movie_reviews’)
nltk.download(‘punkt’)
text = «I love NLTK. It’s incredibly helpful!»
blob = TextBlob(text)
print(blob.sentiment)
Анализ настроений с использованием токенизатора и списка стоп-слов
Важно отметить, что для корректной работы некоторых примеров может потребоваться установка дополнительных библиотек, таких как textblob.
Модель «Мешок слов» (Bag of Words, BoW) является основным методом представления текстовых данных в обработке естественного языка (Natural Language Processing, NLP). Она преобразует текст в числовой вектор, где каждое слово в тексте представляется количеством его появлений.
Модель BoW
В модели BoW текст (например, предложение или документ) представляется в виде «мешка» его слов, не учитывая грамматику и порядок слов, но сохраняя мультиплицивность. Это преобразование текста в набор чисел позволяет использовать стандартные методы машинного обучения, которые работают на числовых данных.
В анализе настроений модель BoW используется для преобразования текстовых данных в формат, пригодный для алгоритмов машинного обучения. Так, текстовые данные (например, отзывы пользователей) преобразуются в числовые векторы, на которых можно обучать классификаторы для определения, например, позитивного или негативного отношения.
Создание BoW с NLTK и использование его для классификации
BoW служит мостом между текстовыми данными и числовыми методами.
NLTK с его легкостью использования делают его идеальным выбором для широкого спектра задач обработки текстовых данных.
Более подробно с NLTK можно ознакомиться здесь.
А практические навыки по аналитике вы можете получить от экспертов отрасли в рамках онлайн-курсов от моих коллег из OTUS. Подробнее в каталоге.
Введение
Сегодня я продолжу рассказ о применении методов анализа данных и машинного обучения на практических примерах. В прошлой статье мы с вами разбирались с задачей кредитного скоринга. Ниже я попытаюсь продемонстрировать решение другой задачи с того же турнира, а именно «Задачи о паспортах» (Задание №2).
При решении будут показаны основы анализа текстовой информации, а также ее кодирование для построения модели с помощью Python и модулей для анализа данных (pandas, scikit-learn, pymorphy).
Постановка задачи
При работе с большим объёмом данных важно поддерживать их чистоту. А при заполнении заявки на банковский продукт необходимо указывать полные паспортные данные, в том числе и поле «кем выдан паспорт», число различных вариантов написаний одного и того же отделения потенциальными клиентами может достигать нескольких сотен. Важно понимать, не ошибся ли клиент, заполняя другие поля: «код подразделения», «серию/номер паспорта». Для этого необходимо сверять «код подразделения» и «кем выдан паспорт».
Задача заключается в том, чтобы проставить коды подразделений для записей из тестовой выборки, основываясь на обучающей выборке.
Предварительная обработка данных
Загрузим данные и посмотрим, что мы имеем:
from pandas import read_csv
import pymorphy2
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.decomposition import PCA
train = read_csv(‘https://static.tcsbank.ru/documents/olymp/passport_training_set.csv’,’;’, index_col=’id’ ,encoding=’cp1251′)
train.head
Теперь можно посмотреть как пользователи записывают поле «кем выдан паспорт» на примере какого-либо подразделения:
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РЕСПУБЛИКЕ КАРЕЛИЯ В МЕДВЕЖ. Р-Е
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО Р. К АРЕЛИЯ В МЕДВЕЖЬЕГОРСКОМ РАЙОНЕ
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РЕСП КАРЕЛИЯ В МЕДВЕЖЬЕГОРСКОМ Р-НЕ
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РЕСПУБЛИКЕ КАРЕЛИЯ В МЕДВЕЖЬЕГОРСКОМ РАЙОНЕ
ОУФМС РОССИИ ПО РЕСПУБЛИКЕ КАРЕЛИЯ В МЕДВЕЖЬЕГОРСКОМ РАЙОНЕ
УФМС РОССИИ ПО РК В МЕДВЕЖЬЕГОРСКОМ РАЙОНЕ
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РЕСПУБЛИКЕ КАРЕЛИЯ МЕДВЕЖЬЕГОРСКОМ Р-ОНЕ
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РК В МЕДВЕЖЬЕГОРСКОМ РАЙОНЕ
ОТДЕЛЕНИЕМ УФМС РОССИИ ПО РЕСПУБЛИКЕ КОРЕЛИЯ В МЕДВЕЖИГОРСКОМ РАЙОНЕ
УФМС РОССИИ ПО Р. К АРЕЛИЯ МЕДВЕЖЬЕГОРСКОГО Р-НА
ОТДЕЛОМ УФМС РОССИИ ПО РЕСПУБЛИКЕ КАРЕЛИЯ В МЕДВЕЖЬЕГОРСКОМ
УФМС РЕСПУБЛИКИ КАРЕЛИИ МЕДВЕЖЬЕГОРСКОГО Р-ОН
МЕДВЕЖЬЕГОРСКИМ ОВД
Как можно заметить нужно на поле действительно заполняется криво. Но для нормально кодирования мы должны привести это поле к более-менее нормальному (однозначному) виду.
Для начала я бы предложил привести все записи к одному регистру, например, чтобы все буквы стали строчными. Это легко сделать с помощью атрибута str, столбца DataFrame’a. Этот атрибут позволяет работать со столбцом как с строкой, а также выполнять различного рода поиск и замену по регулярным выражениям:
C регистром определились. Далее надо по возможности избавиться от популярных сокращений, например район, город и т.д. Сделаем это с помощью регулярных выражений. Pandas предоставляет удобное использование регулярных выражений применительно к каждому столбцу. Это выглядит так:
Теперь избавимся от всех лишних символов, кроме русских букв, дефисов и пробелов. Это связано с тем, что паспорт о одинаковым подразделением может выдаваться отделами с разными номерами, и это ухудшит дальнейшую кодировку:
На следующем шаге, надо расшифровать аббревиатуры, типа УВД, УФНС, ЦАО, ВАО и т.д., т.к. этих их в принципе не много, но на качестве дальнейшего кодирования это скажется положительно. Например если у нас будет две записи «УВД» и «управление внутренних дел», то закодированы они будут по разному, т. к. для компьютера это разные значения.
Итак перейдем к расшифровке. И, для начала, заведем словарь сокращений, с помощью которого мы и сделаем расшифровку:
Теперь, собственно произведем расшифровку абривеатур и отформатируем полученные записи:
Предварительный этап обработки поля «кем выдан паспорт» на этом закончим. И перейдем к полю, в котором находится дата выдачи.
Как можно заметить данные в нем хранятся в виде: месяцMгод.
Соответственно можно просто убрать букву «M» и привести поле к числовому типу. Но если хорошо подумать, то это поле можно удалить, т.к. на один месяц в году может приходиться несколько подразделений выдававших паспорт, и соответственно это может испортить нашу модель. Исходя из этого удалим его из выборки:
Анализ данных
Итак, данные для построения модели у нас есть, но они находятся в текстовом виде. Для построения модели хорошо бы было их закодировать в числовом виде.
Авторы пакета scikit-learn заботливо о нас позаботились и добавили несколько способов для извлечения и кодирования текстовых данных. Из них мне больше всего нравятся два:
FeatureHasher преобразовывает строку в числовой массив заданной длинной с помощью хэш-функции (32-разрядная версия Murmurhash3)
CountVectorizer преобразовывает входной текст в матрицу, значениями которой, являются количества вхождения данного ключа(слова) в текст. В отличие от FeatureHasher имеет больше настраиваемых параметров(например можно задать токенизатор), но работает медленнее.
Для более точного понимания работы CountVectorizer приведем простой пример. Допустим есть таблица с текстовыми значениями:
Для начала CountVectorizer собирает уникальные ключи из всех записей, в нашем примере это будет:
Длина списка из уникальных ключей и будет длиной нашего закодированного текста (в нашем случае это 4). А номера элементов будут соответствовать, количеству раз встречи данного ключа с данным номером в строке:
Соответственно после кодировки, применения данного метода мы получим:
Функция делает следующее:
Теперь, когда есть функция для нормализации можно приступить к кодированию с помощью метода CountVectorizer. Он выбран потому, что ему можно передать нашу функцию, как токенизатор и он составит список ключей по значениям полученным в результате работы нашей функции:
coder = HashingVectorizer(tokenizer=f_tokenizer, n_features=256)
Как можно заметить при создании метода кроме токенизатора мы задаем еще один параметр n_features. Через данный параметр задается длина закодированной строки (в нашем случае строка кодируется при помощи 256 столбцов). Кроме того, у HashingVectorizer есть еще одно преимущество перед CountVectorizer, но сразу может выполнять нормализацию значений, что хорошо для таких алгоритмов, как SVM.
Теперь применим наш кодировщик к обучающему набору:
TrainNotDuble = train.drop_duplicates()
trn = coder.fit_transform(TrainNotDuble.passport_issuer_name.tolist()).toarray()
Построение модели
Для начала нам надо задать значения для столбца, в котором будут содержаться метки классов:
target = TrainNotDuble.passport_div_code.values
Задача, которую мы решаем сегодня, принадлежит к классу задач классификации со множеством классов. Для решения данной задачи лучше всего подошел алгоритм RandomForest. Остальные алгоритмы показали очень плохие результаты (менее 50%) поэтому я решил не занимать место в статье. При желании любой интересующийся может проверить данные результаты.
Для оценки качества классификации будем использовать количество документов по которым принято правильное решение, т. е.
, где P — количество документов по которым классификатор принял правильное решение, а N – размер обучающей выборки.
В пакете scikit-learn для этого есть функция: accuracy_score
Перед началом построения собственно модели, давайте сократим размерность с помощью «метода главных компонент», т.к. 256 столбцов для обучения довольно много:
pca = PCA(n_components = 15)
trn = pca.fit_transform(trn)
Модель будет выглядеть так:
model = RandomForestClassifier(n_estimators = 100, criterion=’entropy’)
TRNtrain, TRNtest, TARtrain, TARtest = train_test_split(trn, target, test_size=0.4)
model.fit(TRNtrain, TARtrain)
print ‘accuracy_score: ‘, accuracy_score(TARtest, model.predict(TRNtest))
Заключение
В качестве вывода нужно отметить, что полученная точность в 65% близка к угадыванию. Чтобы улучшить нужно при первичной обработке обработать грамматические ошибки и различного рода описки. Данное действие также скажется положительно и на словаре при кодировании поля, т. е. его размер уменьшиться и соответственно уменьшиться длина строки после ее кодировки.
Кроме того этап обучения тестовой выборки опущен специально, т. к. в нем нет ничего особенного, кроме его приведения к нужному виду (это можно легко сделать взяв за основу преобразования обучающей выборки)
В статье я попытался показать минимальный список этапов по обработке текстовой информации для подачи ее алгоритмам машинного обучения. Возможно делающим первые шаги в анализе данных данная информация будет полезной.
UPD: Консоль IPython Notebook TKCTask2Answer.ipynb