
- Обнаружение выбросов
- Python3
- Normalization or Standardization
- Statistical Analysis
- Drop the outliers
- Выбор признаков (Feature selection)
- Статистические подходы
- Отбор с использованием моделей
- Перебор
- Check Outcomes Proportionality
- Кодирование данных
- Битва за память
- Что еще можно сделать
- Конструирование и выбор признаков
- Нормализация тренировочных данных
- Преобразования признаков (Feature transformations)
- Взаимодействия (Interactions)
- Заполнение пропусков
- Разделение на обучающую выборку и целевую переменную
- Разделение данных для обучения и тестирования
- Разделение данных на три подвыборки
- Load the dataset
- Need of Data Preprocessing
- Check the outliers
- Check the data info
Обнаружение выбросов
Как уже упоминалось ранее, оказалось, что для Age существуют значения, которые кажутся ошибочными. Такие как отрицательный возраст или чрезвычайно большие целые числа, могут негативно повлиять на результат работы алгоритма машинного обучения, и нам нужно будет их устранить.
Для этого возьмем нашу эвристическую оценку, в каком возрасте могут работать люди: от 14 до 100 лет. И все величины, не попадающие в этот диапазон, преобразуем в формат Not-a-Number.
Эти нулевые значения затем могут быть обработаны с использованием описанного выше sklearn Imputer.
После определения диапазона для работающего человека, визуализируем распределение возраста, присутствующего в этом наборе данных.
seaborn as sns
sns.set(color_codes=True)
= sns.distplot(df. Age.dropna())
.figure.set_size_inches(,)
Python3
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
Whether you’re preparing for your first job interview or aiming to upskill in this ever-evolving tech landscape, GeeksforGeeks Courses are your key to success. We provide top-quality content at affordable prices, all geared towards accelerating your growth in a time-bound manner. Join the millions we’ve already empowered, and we’re here to do the same for you. Don’t miss out — check it out now!
Y = df. Outcome
Normalization or Standardization
Pregnancies 0
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64
Statistical Analysis
In statistical analysis, first, we use the df.describe() which will give a descriptive overview of the dataset.
fig, axs = plt.subplots(9,1,dpi=95, figsize=(7,17))
for col in df.columns:
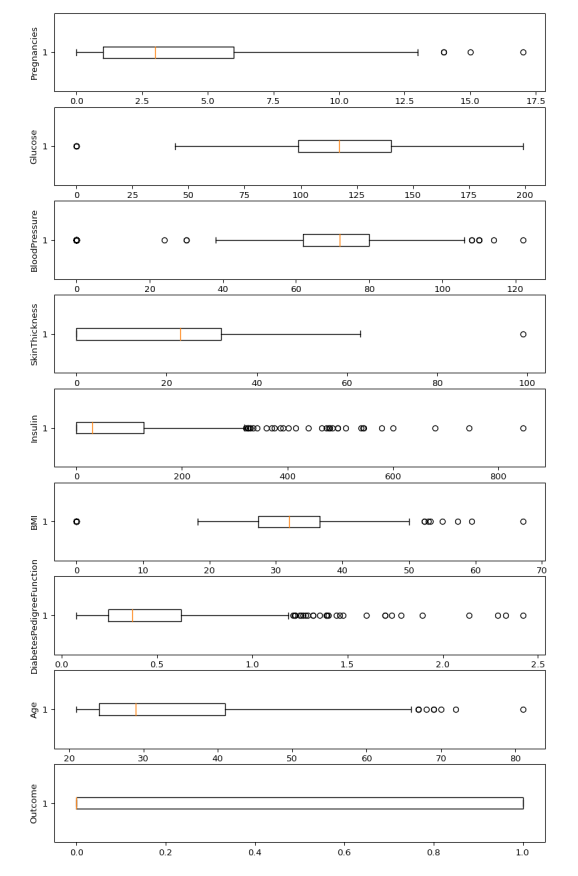
from the above boxplot, we can clearly see that all most every column has some amounts of outliers.
Drop the outliers
scaler = MinMaxScaler(feature_range=(0, 1))
rescaledX = scaler.fit_transform(X)
corr = df.corr()
sns.heatmap(df.corr(), annot=True, fmt= ‘.2f’)
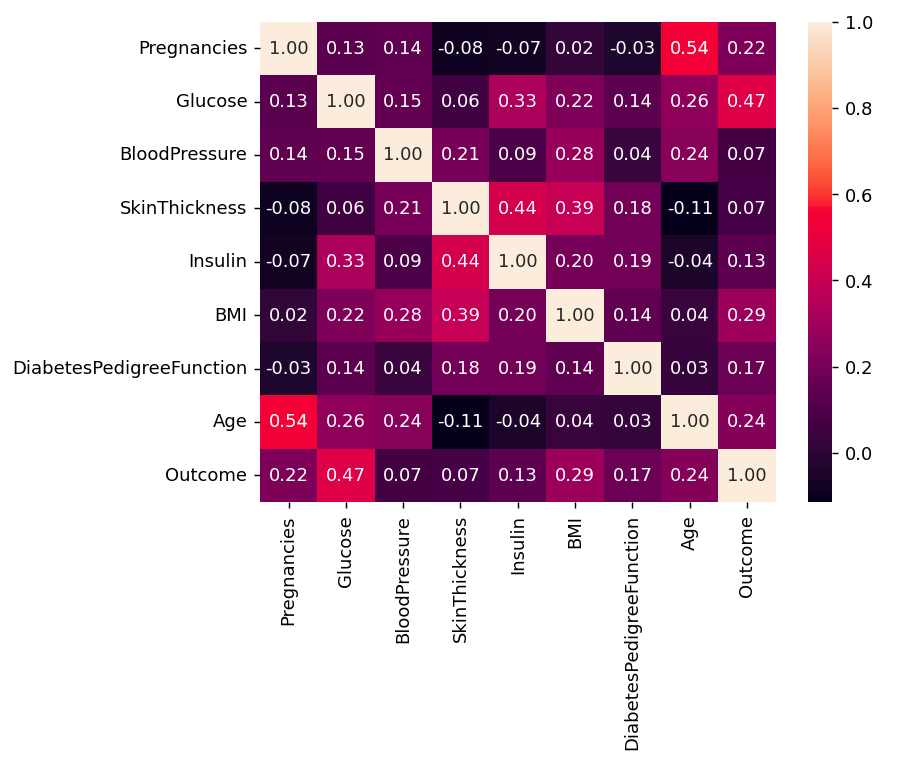
We can also camapare by single columns in descending order
Выбор признаков (Feature selection)
Зачем вообще может понадобиться выбирать фичи? Кому-то эта идея может показаться контринтуитивной, но на самом деле есть минимум две важные причины избавляться от неважных признаков. Первая понятна всякому инженеру: чем больше данных, тем выше вычислительная сложность. Пока мы балуемся с игрушечными датасетами, размер данных – это не проблема, а для реального нагруженного продакшена лишние сотни признаков могут быть ощутимы. Другая причина – некоторые алгоритмы принимают шум (неинформативные признаки) за сигнал, переобучаясь.
Статистические подходы
Самый очевидный кандидат на отстрел – признак, у которого значение неизменно, т.е. не содержит вообще никакой информации. Если немного отойти от этого вырожденного случая, резонно предположить, что низковариативные признаки скорее хуже, чем высоковариативные. Так можно придти к идее отсекать признаки, дисперсия которых ниже определенной границы.
In : from sklearn.feature_selection import VarianceThreshold
In : from sklearn.datasets import make_classification
In : x_data_generated, y_data_generated = make_classification()
In : x_data_generated.shape
Out: (100, 20)
In : VarianceThreshold(.7).fit_transform(x_data_generated).shape
Out: (100, 19)
In : VarianceThreshold(.8).fit_transform(x_data_generated).shape
Out: (100, 18)
In : VarianceThreshold(.9).fit_transform(x_data_generated).shape
Out: (100, 15)
Есть и другие способы, также основанные на классической статистике.
In : from sklearn.feature_selection import SelectKBest, f_classif
In : x_data_kbest = SelectKBest(f_classif, k=5).fit_transform(x_data_generated, y_data_generated)
In : x_data_varth = VarianceThreshold(.9).fit_transform(x_data_generated)
In : from sklearn.linear_model import LogisticRegression
In : from sklearn.model_selection import cross_val_score
In : cross_val_score(LogisticRegression(), x_data_generated, y_data_generated, scoring=’neg_log_loss’).mean()
Out: -0.45367136377981693
In : cross_val_score(LogisticRegression(), x_data_kbest, y_data_generated, scoring=’neg_log_loss’).mean()
Out: -0.35775228616521798
In : cross_val_score(LogisticRegression(), x_data_varth, y_data_generated, scoring=’neg_log_loss’).mean()
Out: -0.44033042718359772
Видно, что отобранные фичи повысили качество классификатора. Понятно, что этот пример сугубо искусственный, тем не менее, прием достоин проверки и в реальных задачах.
Отбор с использованием моделей
Другой подход: использовать какую-то baseline модель для оценки признаков, при этом модель должна явно показывать важность использованных признаков. Обычно используются два типа моделей: какая-нибудь «деревянная» композиция (например, Random Forest) или линейная модель с Lasso регуляризацией, склонной обнулять веса слабых признаков. Логика интутивно понятна: если признаки явно бесполезны в простой модели, то не надо тянуть их и в более сложную.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
x_data_generated, y_data_generated = make_classification()
pipe = make_pipeline(SelectFromModel(estimator=RandomForestClassifier()),
LogisticRegression())
lr = LogisticRegression()
rf = RandomForestClassifier()
print(cross_val_score(lr, x_data_generated, y_data_generated, scoring=’neg_log_loss’).mean())
print(cross_val_score(rf, x_data_generated, y_data_generated, scoring=’neg_log_loss’).mean())
print(cross_val_score(pipe, x_data_generated, y_data_generated, scoring=’neg_log_loss’).mean())
-0.184853179322
-0.235652626736
-0.158372952933
Нельзя забывать, что это тоже не серебряная пуля — может получиться даже хуже.
Давайте вернемся к датасету Renthop.
x_data, y_data = get_data()
x_data = x_data.values
pipe1 = make_pipeline(StandardScaler(),
SelectFromModel(estimator=RandomForestClassifier()),
LogisticRegression())
pipe2 = make_pipeline(StandardScaler(),
LogisticRegression())
rf = RandomForestClassifier()
print(‘LR + selection: ‘, cross_val_score(pipe1, x_data, y_data, scoring=’neg_log_loss’).mean())
print(‘LR: ‘, cross_val_score(pipe2, x_data, y_data, scoring=’neg_log_loss’).mean())
print(‘RF: ‘, cross_val_score(rf, x_data, y_data, scoring=’neg_log_loss’).mean())
LR + selection: -0.714208124619
LR: -0.669572736183
# стало только хуже!
RF: -2.13486716798
Перебор
Наконец, самый надежный, но и самый вычислительно сложный способ основан на банальном переборе: обучаем модель на подмножестве «фичей», запоминаем результат, повторяем для разных подмножеств, сравниваем качество моделей. Такой подход называется Exhaustive Feature Selection.
Перебирать все комбинации – обычно слишком долго, так что можно пробовать уменьшить пространство перебора. Фиксируем небольшое число N, перебираем все комбинации по N признаков, выбираем лучшую комбинацию, потом перебираем комбинации из N+1 признаков так, что предыдущая лучшая комбинация признаков зафиксирована, а перебирается только новый признак. Таким образом можно перебирать, пока не упремся в максимально допустимое число признаков или пока качество модели не перестанет значимо расти. Этот алгоритм называется Sequential Feature Selection.
Этот же алгоритм можно развернуть: начинать с полного пространства признаков и выкидывать признаки по одному, пока это не портит качество модели или пока не достигнуто желаемое число признаков.
Время неспешного перебора!
Outcome 1.000000
Glucose 0.466581
BMI 0.292695
Age 0.238356
Pregnancies 0.221898
DiabetesPedigreeFunction 0.173844
Insulin 0.130548
SkinThickness 0.074752
BloodPressure 0.0
Check Outcomes Proportionality
As we can see from the above info that the our dataset has 9 columns and each columns has 768 values. There is no Null values in the dataset.
We can also check the null values using df.isnull()
Кодирование данных
Многие алгоритмы машинного обучения ожидают числовые входные данные, поэтому нам нужно выяснить способ представления наших категориальных данных численным образом.
Одним из решений этого было бы произвольное присвоение числового значения для каждой категории и отображение набора данных из исходных категорий в каждое соответствующее число. Например, давайте посмотрим на столбец «leave» (как легко вам взять отпуск по болезни для состояния психического здоровья?) В нашем наборе данных
Который возвращает следующие значения
t know
Somewhat easy
Very easy
Somewhat difficult
Very difficult
leave, dtype
Для кодирования этих данных, сопоставим каждое значение с числом.
Этот процесс известен как Label Encoding и sklearn может сделать это за нас.
Проблема с этим подходом заключается в том, что вы вводите порядок, который может отсутствовать в исходных данных. В нашем случае можно утверждать, что данные являются ранжированными («Very difficult» меньше «Somewhat difficult», который меньше «Very easy», который меньше «Somewhat easy»), но в большинстве своем категориальные данные не имеют порядка. Например, если у вас есть признак обозначающий вид животного, зачастую высказывание кошка больше собаки не имеет смысла. Опасность кодирования меток заключается в том, что ваш алгоритм может научиться отдавать предпочтение собак, кошкам из-за искусственных порядковых значений, введенных вами во время кодирования.
Общим решением для кодирования номинальных данных является one-hot-encoding.
Вместо того, чтобы заменять категориальное значение на числовое значение (кодирование меток), как показано ниже
Вместо этого мы создаем столбец для каждого значения и используем 1 и 0 для обозначения выражения каждого значения. Эти новые столбцы часто называются фиктивными переменными.
Вы можете выполнить one-hot-encoding непосредственно в Pandas или использовать sklearn, хотя sklearn немного более прозрачен, поскольку one-hot-encoding из него работает только для целых значений. В нашем примере (где входные данные представляют собой строки) нам нужно сначала выполнить кодировку меток, а затем one-hot-encoding.
Битва за память
На самом деле Pandas группирует и хранит “столбцы” блоками, разбитыми по типам. Иными словами float, int и objects хранятся раздельно, причем оптимизировано, без индексов. С числами все просто — столбцы в блоке объединяются в многомерный массив NumPy. При запросе значения происходит сопоставление индекса с массивом. С объектами немного сложнее. Все это означает, что разные объекты по-разному используют память.
Поработаем с разными типами объектов отдельно.
Для начала разберемся с наименьшим злом — с числами. В Pandas используются подтипы int8, int16, int32, int64, float16, float32, float64. В нашем случае в результате сравнения при извлечении, числа оказались в наиболее затратном по памяти формате.
Изменим эту ситуацию и вот как: получим минимальное и максимальное значение в серии, затем сравним его с машинными лимитами для типов Numpy, после чего заменим на наименьшее.
# последовательно сравниваем от наименьшего инта начиная с np.int8
# наверх и переопределяем тип для серии
# и т.д.
# аналогично для float
Мы выполнили самопальный вариант понижающего преобразования, выиграв 74.4Mb.
<class
RangeIndex: 200000 entries, 0 to 199999
Columns: 66 entries, event_code to dinosaur_count
dtypes: float1661, float323, int162
memory usage: 26.3 MB
Но у нас все еще есть проблема:
Оказывается, везде в датасете использовано число с плавающей точкой, хотя на самом деле никакой потребности в этом нет — в этих данных все числа целые. Исправим эту ситуацию:
В данном случае мы заменили все пропуски в данных на -1, что открыло для нас возможность применить преобразование типов. Прием замены пропусков на число довольно часто встречается — обычно выбирают число, которое не встречается в данных, к примеру -9999. В нашем случае в данных вообще нет отрицательных чисел, поэтому мы просто взяли наименьшее кешированное, что бы сэкономить и тут. К тому же этот трюк окажется полезен в будущем. Смотрим на результат преобразования:
Итого, по числам нам удалось сэкономить 83.5% по памяти! Неплохо.
Переходим к объектам. Тип object в Pandas хранит строковое представление. Строки хранятся фрагментировано — значение в ячейке по сути является указателем. При этом резервируется много памяти и это для нас плохо.
<class
RangeIndex: 200000 entries, 0 to 199999
Columns: 70 entries, version to chests
dtypes: object70
memory usage: 443.1 MB
Pandas предоставляет подтип category, который отображает строковые данные на индекс в int, а это то, что нам нужно, т.к. данные будут храниться не в виде указателя, а в виде словаря, в котором целочисленным значениям сопоставлены уникальным значениям данных. Перегоним наши объекты в «категории»:
# subtype categoty
# unhashable objects can’t be categorised
Мы отбросим часть объектов, т.к. договорились ранее не работать с нераспакованной частью json
Обратите внимание, что мы сами управляем какие именно объекты представлять в виде категорий через отношение количества уникальных значений к общему количеству значений в серии. Теперь посмотрим объем нераспакованных данных и сложим с оптимизированными распакованными:
<class
RangeIndex: 200000 entries, 0 to 199999
Columns: 31 entries, castles_placed to chests
dtypes: object31
memory usage: 193.0 MB
193.0MB + 7.9MB — нам удалось сэкономить 242.2MB, больше половины. Если мы применим наш метод ко всему дата-сету, то мы увидим, что не все объекты укладываются в наш формат категорий. часть объектов имеет слишком большое число уникальных значений (хешы, айдишники и т.д.) и есть смысл оставить их в объектах.
Кстати, при определении подтипа category, пропуски в списке заменяются на дефолтное значение -1. Это очень удачно совпало с принятым нами ранее решением 🙂
Отдельно стоит отметить колонку timestamp. Это временная метка и в неоптимизированном виде она тоже занимает избыточное пространство.
Временную метку оптимизируем с помощью функции pandas pd.to_datetime. Параметр format позволяет задать тип представления временной отметки. Дефолтный вот такой: “%d/%m/%Y”. Теперь метка будет выглядеть так:
В этом оптимизированном виде мы сэкономим дополнительные 14Mb памяти.
В завершении операций по оптимизации необходимо данные сериализовать. Сделать это можно, к примеру, с помощью стандартного модуля shelve. Чуть позже, в отдельной статье я расскажу про сложности и пути их решения, которые могут возникнуть при сериализации.
Что еще можно сделать
Кроме того, можно не ограничиться представлением, а закодировать столбцы цифрами. Есть методы в самом Pandas. Я рекомендую использовать внешний модуль category_encoders:
Ну и, наконец, можно перегнать все в Numpy! 🙂
Конструирование и выбор признаков
Конструирование и выбор признаков зачастую приносит наибольшую отдачу с точки зрения времени, потраченного на машинное обучение. Сначала дадим определения:
Модель машинного обучения может учиться только на предоставленных нами данных, поэтому крайне важно удостовериться, что мы включили всю релевантную для нашей задачи информацию. Если не предоставить модели корректные данные, она не сможет научиться и не будет выдавать точные прогнозы!
Мы сделаем следующее:
One-hot кодирование необходимо для того, чтобы включить в модель категориальные переменные. Алгоритм машинного обучения не сможет понять тип «офис», так что если здание офисное, мы присвоим ему признак 1, а если не офисное, то 0.
Добавление преобразованных признаков поможет модели узнать о нелинейных взаимосвязях внутри данных. В анализе данных является нормальной практикой извлекать квадратные корни, брать натуральные логарифмы или ещё как-то преобразовывать признаки, это зависит от конкретной задачи или вашего знания лучших методик. В данном случае мы добавим натуральный логарифм всех числовых признаков.
Этот код выбирает числовые признаки, вычисляет их логарифмы, выбирает два категориальных признака, применяет к ним one-hot кодирование и объединяет оба множества в одно. Судя по описанию, предстоит куча работы, но в Pandas всё получается довольно просто!
Теперь у нас есть больше 11 000 наблюдений (зданий) со 110 колонками (признаками). Не все признаки будут полезны для прогнозирования Energy Star Score, поэтому займёмся выбором признаков и удалим часть переменных.
Многие из имеющихся 110 признаков избыточны, потому что сильно коррелируют друг с другом. К примеру, вот график EUI и Weather Normalized Site EUI, у которых коэффициент корреляции равен 0,997.
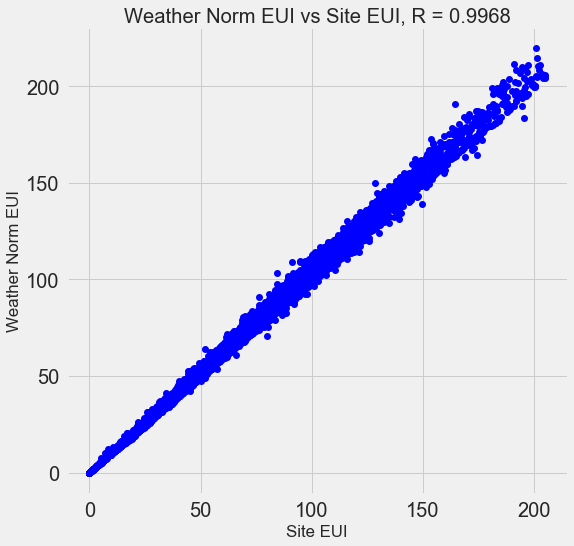
Признаки, которые сильно коррелируют друг с другом, называются коллинеарными. Удаление одной переменной в таких парах признаков часто помогает модели обобщать и быть более интерпретируемой. Обратите внимание, что речь идёт о корреляции одних признаков с другими, а не о корреляции с целью, что только помогло бы нашей модели!
Существует ряд методов вычисления коллинеарности признаков, и один из самых популярных — фактор увеличения дисперсии (variance inflation factor). Мы для поиска и удаления коллинеарных признаков воспользуемся коэффициентом В-корреляции (thebcorrelation coefficient). Отбросим одну пару признаков, если коэффициент корреляции между ними больше 0,6. Код приведён в блокноте (и в ответе на Stack Overflow).
Это значение выглядит произвольным, но на самом деле я пробовал разные пороги, и приведённый выше позволил создать наилучшую модель. Машинное обучение эмпирично, и часто приходится экспериментировать, чтобы найти лучшее решение. После выбора у нас осталось 64 признака и одна цель.
# Remove any columns with all na values
features = features.dropna(axis=1, how = ‘all’)
print(features.shape)
(11319, 65)
Нормализация тренировочных данных
На этом этапе мы успешно очистили наши данные и превратили их в форму, которая подходит для алгоритмов машинного обучения. Однако на данном этапе мы должны рассмотреть вопрос о том, полезен ли какой-либо метод нормализации данных для нашего алгоритма. Это зависит от данных и алгоритма, который мы планируем реализовать.
ML алгоритмы, которые требуют нормализации данных:
ML алгоритмы, которые не требуют нормализации данных:
Примечание: приведенные выше списки ни в коем случае не являются исчерпывающими, а просто служат примером.
Предположим, у вас есть набор данных с различными единицами: температура в Кельвине, относительная влажность и день года. Мы можем увидеть следующие диапазоны для каждой функции.
Когда вы смотрите на эти значения, вы интуитивно нормализуете значения. Например, вы знаете, что увеличение на 0,5 (=50%) для влажности намного более значимо, чем увеличение на 0,5 для температуры. И если мы не будем нормализовать эти данные, наш алгоритм может научиться использовать температуру в качестве основного предиктора просто потому, что масштаб является наибольшим (и, следовательно, изменения в значениях температуры наиболее значительны для алгоритма). Нормализация данных позволяет всем признакам вносить одинаковый вклад (или, что более точно, позволяет добавлять признаки в зависимости от их важности, а не их масштаба).
Преобразования признаков (Feature transformations)
Монотонное преобразование признаков критично для одних алгоритмов и не оказывает влияния на другие. Кстати, это одна из причин популярности деревьев решений и всех производных алгоритмов (случайный лес, градиентный бустинг) – не все умеют/хотят возиться с преобразованиями, а эти алгоритмы устойчивы к необычным распределениям.
Бывают и сугубо инженерные причины: np.log как способ борьбы со слишком большими числами, не помещающимися в np.float64. Но это скорее исключение, чем правило; чаще все-таки вызвано желанием адаптировать датасет под требования алгоритма. Параметрические методы обычно требуют как минимум симметричного и унимодального распределения данных, что не всегда обеспечивается реальным миром. Могут быть и более строгие требования (уместно вспомнить урок про линейные модели).
Впрочем, требования к данным предъявляют не только параметрические методы: тот же метод ближайших соседей предскажет полную чушь, если признаки ненормированы: одно распределение расположено в районе нуля и не выходит за пределы (-1, 1), а другой признак – это сотни и тысячи.
Простой пример: предположим, что стоит задача предсказать стоимость квартиры по двум признакам – удаленности от центра и количеству комнат. Количество комнат редко превосходит 5, а расстояние от центра в больших городах легко может измеряться в десятках тысяч метров.
Самая простая трансформация – это Standart Scaling (она же Z-score normalization).
In : from sklearn.preprocessing import StandardScaler
In : from scipy.stats import beta
In : from scipy.stats import shapiro
In : data = beta(1, 10).rvs(1000).reshape(-1, 1)
In : shapiro(data)
Out: (0.8783774375915527, 3.0409122263582326e-27)
# значение статистики, p-value
In : shapiro(StandardScaler().fit_transform(data))
Out: (0.8783774375915527, 3.0409122263582326e-27)
# с таким p-value придется отклонять нулевую гипотезу о нормальности данных
Другой достаточно популярный вариант – MinMax Scaling, который переносит все точки на заданный отрезок (обычно (0, 1)).
StandartScaling и MinMax Scaling имеют похожие области применимости и часто сколько-нибудь взаимозаменимы. Впрочем, если алгоритм предполагает вычисление расстояний между точками или векторами, выбор по умолчанию – StandartScaling. Зато MinMax Scaling полезен для визуализации, чтобы перенести признаки на отрезок (0, 255).
Если мы предполагаем, что некоторые данные не распределены нормально, зато описываются логнормальным распределением, их можно легко привести к честному нормальному распределению:
In : from scipy.stats import lognorm
In : data = lognorm(s=1).rvs(1000)
In : shapiro(data)
Out: (0.05714237689971924, 0.0)
In : shapiro(np.log(data))
Out: (0.9980740547180176, 0.3150389492511749)
Логнормальное распределение подходит для описания зарплат, стоимости ценных бумаг, населения городов, количества комментариев к статьям в интернете и т.п. Впрочем, для применения такого приема распределение не обязательно должно быть именно логнормальным – все распределения с тяжелым правым хвостом можно пробовать подвергнуть такому преобразованию. Кроме того, можно пробовать применять и другие похожие преобразования, ориентируясь на собственные гипотезы о том, как приблизить имеющееся распределение к нормальному. Примерами таких трансформаций являются преобразование Бокса-Кокса (логарифмирование – это частный случай трансформации Бокса-Кокса) или преобразование Йео-Джонсона, расширяющее область применимости на отрицательные числа; кроме того, можно пробовать просто добавлять константу к признаку – np.log(x + const).
В примерах выше мы работали с синтетическими данными и строго проверяли нормальность при помощи критерия Шапиро-Уилка. Давайте попробуем посмотреть на реальные данные, а для проверки на нормальность будем использовать менее формальный метод – Q-Q график. Для нормального распределения он будет выглядеть как ровная диагональная линия, и визуальные отклонения интуитивно понятны.
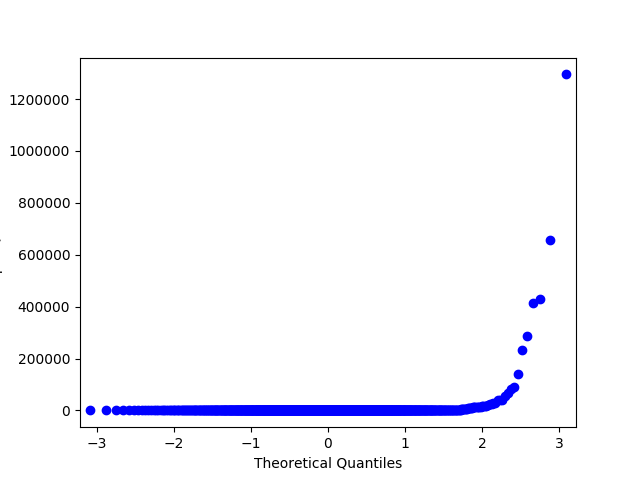
Q-Q график для логнормального распределения

Q-Q график для того же распределения после логарифмирования
Давайте рисовать графики!

Q-Q график исходного признака

Q-Q график признака после StandartScaler. Форма не меняется
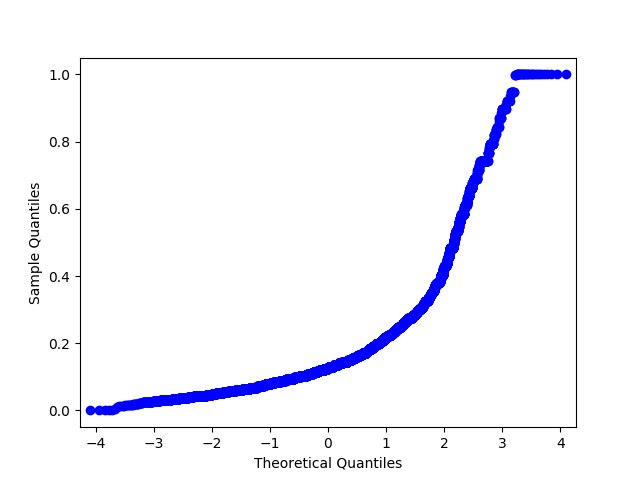
Q-Q график признака после MinMaxScaler. Форма не меняется

Q-Q график признака после логарифмирования. Дела пошли на поправку!
Давайте посмотрим, могут ли преобразования как-то помочь реальной модели. Я сделал небольшой скрипт, который читает данные соревнования Renthop, выбирает некоторые признаки (остальные по-диктаторски выброшены для простоты), и возвращает нам более или менее готовые данные для демонстрации.
Довольно много кода
Взаимодействия (Interactions)
Если предыдущие преобразования диктовались скорее математикой, то этот пункт снова обоснован природой данных; его можно отнести как к трансформациям, так и к созданию новых признаков.
Снова обратимся к задаче Two Sigma Connect: Rental Listing Inquires. Среди признаков в этой задаче есть количество комнат и стоимость аренды. Житейская логика подсказывает, что стоимость в пересчете на одну комнату более показательна, чем общая стоимость – значит, можно попробовать выделить такой признак.
Заполнение пропусков
Не многие алгоритмы умеют работать с пропущенными значениями «из коробки», а реальный мир часто поставляет данные с пропусками. К счастью, это одна из тех задач, для решения которых не нужно никакого творчества. Обе ключевые для анализа данных python библиотеки предоставляют простые как валенок решения: pandas. DataFrame.fillna и sklearn.preprocessing. Imputer.
Готовые библиотечные решения не прячут никакой магии за фасадом. Подходы к обработке отсутствующих значений напрашиваются на уровне здравого смысла:

Удобство использования библиотечных решений иногда подсказывает воткнуть что-то вроде df = df.fillna(0) и не париться о пропусках. Но это не самое разумное решение: большая часть времени обычно уходит не на построение модели, а на подготовку данных; бездумное неявное заполнение пропусков может спрятать баг в обработке и испортить модель.
Разделение на обучающую выборку и целевую переменную
Так как мы сейчас рассматриваем задачу обучения с учителем (несколько сублимированную — сами придумали, сами решаем), нам необходимо разделить на признаки для обучения и на признаки для предсказания. Целевая переменная для текущего датасета зависит от ваших целей. Для примера: вы можете, базируясь на этом наборе данных решать классификационную задачу (определять пол опрашиваемого) или же регрессионную (предсказывать возраст опрашиваемого). Для дальнейшего рассмотрения была взята классификационная задача: будет ли опрашиваемая персона искать лечение.
Разделение данных для обучения и тестирования
Одной из последних вещей, которые нам нужно будет сделать, чтобы подготовить данные для обучения, является разделение данных на обучающую и тестовую выборку. Выделение тестовой выборки необходимо для понимания того, что мы обучили алгоритм в достаточной степени (не произошло переобучение или недообучение)
from sklearnmodel_selection train_test_split
features_train, features_test, labels_train, labels_test train_test_split(features, labels, test_size, random_state )
Разделение данных на три подвыборки
Можно пойти дальше и разделять данные на три подмножества: обучение, валидация и отложенная выборка. Данные обучения используются для «обучения» модели, данные валидации используются для поиска лучшей архитектуры модели, а отложенная выборка зарезервирована для финальной оценки нашей модели. При построении модели нам часто дают выбор в отношении общего дизайна модели; данные валидации позволяют нам оценивать несколько проектов в поисках лучшего дизайна, но при этом мы «подгоняем» дизайн нашей модели по этому подмножеству. Таким образом, тестовые данные по-прежнему полезны при определении того, насколько хорошо наша модель будет обобщать то, чему она научилась для новых данных.
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import seaborn as sns
import matplotlib.pyplot as plt
Load the dataset
Pre-processing refers to the transformations applied to our data before feeding it to the algorithm. Data preprocessing is a technique that is used to convert the raw data into a clean data set. In other words, whenever the data is gathered from different sources it is collected in raw format which is not feasible for the analysis.
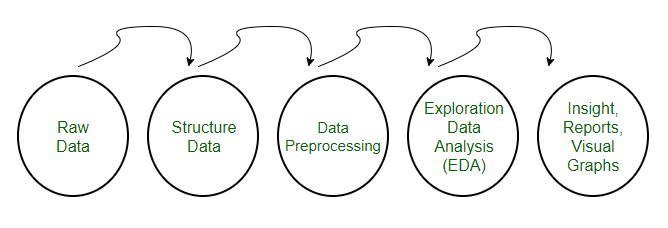
Need of Data Preprocessing
<img class="img-fluid" src="https://media.geeksforgeeks.org/wp-content/uploads/20230512162512/descrive-
.png» title=»»>
The above table shows the count, mean, standard deviation, min, 25%, 50%, 75%, and max values for each column. When we carefully observe the table we will find that. Insulin, Pregnancies, BMI, BloodPressure columns has outliers.
Let’s plot the boxplot for each column for easy understanding.
Check the outliers
df = pd.read_csv(‘Geeksforgeeks/Data/diabetes.csv’)
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI
0 6 148 72 35 0 33.6 1 1 85 66 29 0 26.6
2 8 183 64 0 0 23.3
3 1 89 66 23 94 28.1
4 0 137 40 35 168 43.1
DiabetesPedigreeFunction Age Outcome
0 0.627 50 1
1 0.351 31 0
2 0.672 32 1
3 0.167 21 0
4 2.288 33 1
Check the data info
Для регрессионных задач в качестве базового уровня разумно угадывать медианное значение цели на обучающем наборе для всех примеров в тестовом наборе. Эти наборы задают барьер, относительно низкий для любой модели.
В качестве метрики возьмём среднюю абсолютную ошибку (mae) в прогнозах. Для регрессий есть много других метрик, но мне нравится совет выбирать какую-то одну метрику и с её помощью оценивать модели. А среднюю абсолютную ошибку легко вычислить и интерпретировать.
Прежде чем вычислять базовый уровень, нужно разбить данные на обучающий и тестовый наборы:
Для обучения используем 70 % данных, а для тестирования — 30 %:
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)
Теперь вычислим показатель для исходного базового уровня:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true — y_pred))
baseline_guess = np.median(y)
print(‘The baseline guess is a score of %0.2f’ % baseline_guess)
print(«Baseline Performance on the test set: MAE = %0.4f» % mae(y_test, baseline_guess))
The baseline guess is a score of 66.00
Baseline Performance on the test set: MAE = 24.5164
Средняя абсолютная ошибка на тестовом наборе составила около 25 пунктов. Поскольку мы оцениваем в диапазоне от 1 до 100, то ошибка составляет 25 % — довольно низкий барьер для модели!
