
Рис 1. Зелёная разделительная линия показывает переобученную модель, а чёрная линия — регуляризированную модель. Хотя зелёная линия лучше соответствует образцам, по которым проходило обучение, классификация по зелёной линии очень зависит от конкретных данных, и скорее всего новые данные будут плохо соответствовать классификации по зелёной линии и лучше — классификации по чёрной линии.
Рис 2. Сигнал с шумом (близкий к линейному) аппроксимируется линейной функцией и полиномом. Хотя полином гарантирует идеальное совпадение, линейная аппроксимация лучше генерализирует закономерность и будет давать лучшие предсказания.
Переобучение (переподгонка, пере- в значении «слишком», англ. ) в машинном обучении и статистике — явление, когда построенная модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении (на примерах из тестовой выборки).
Это связано с тем, что при построении модели («в процессе обучения») в обучающей выборке обнаруживаются некоторые случайные закономерности, которые отсутствуют в генеральной совокупности.
Иными словами, модель запоминает огромное количество всех возможных примеров вместо того, чтобы научиться подмечать особенности.
Способы борьбы с переобучением зависят от метода моделирования и способа построения модели. Например, если строится дерево принятия решений, то можно обрезать некоторые его ветки в процессе построения.
- Методы предотвращения переобучения
- Введение
- Что такое переоснащение?
- Что мы подразумеваем под Generalize здесь?
- Что такое недообучение?
- Вау! Большие сроки! Что означают эти термины?
- Обнаружение переобучения и недообучения
- Как предотвратить переоснащение и недооснащение
- Тренируйтесь с большим количеством данных
- Удалить функции
- Регуляризация
- Предотвращение недообучения
- Снижение регуляризации
- Хорошо вписывается в статистическую модель
- Сущность и влияние на результаты
- Основные понятия и определения
- Причины переобучения
- Признаки переобучения
- Как переобучение связано с «слишком большим обучением» модели?
- Способы борьбы с переобучением
- Остались вопросы?
- Как работает Dropout
- Обратный (Inverted) Dropout
- Dropout множества нейронов
- Dropout и другие регуляризаторы
- Обратный Dropout и другие регуляризаторы
- Вступление
- Как справиться с недостаточным оснащением
Методы предотвращения переобучения
Для того, чтобы избежать чрезмерной подгонки, необходимо использовать дополнительные методы, например:
которые могут указать, когда дальнейшее обучение больше не ведёт к улучшению оценок параметров. В основе этих методов лежит явное ограничение на сложность моделей, или проверка способности модели к обобщению путём оценки её эффективности на множестве данных, не использовавшихся для обучения и считающихся приближением к реальным данным, к которым модель будет применяться.
Введение
Предположим, мы на уроке математики, и сегодня мы познакомимся с теоремой Пифагора, иначе известной как вычисление длины гипотенузы прямоугольного треугольника, зная длину двух разных сторон. Я уверен, что это не слишком сложно?
Итак, на уроке математики, что, если вместо того, чтобы просто говорить вам, что такое теорема, я предлагаю вам найти правильное уравнение или правильную формулу самостоятельно, просто используя некоторые данные? Предоставленные вам данные будут иметь длины трех сторон восьми различных прямоугольных треугольников, обозначенных буквами a, b и c, где c — гипотенуза.
Данные приведены ниже:

У вас есть 30 минут, чтобы вычислить правильную формулу, так как мы собираемся пройти тест, где вам будут даны значения a и b, и вы должны предсказать правильные значения для c. В классе тот, кто наберет наибольшее количество баллов, будет свободен от любых домашних заданий в течение 2 полных недель. Разве это не круто?
Ваш ленивый друг в классе, скажем Атхарв, очень взволнован этим. Он не заинтересован в выполнении домашнего задания и поэтому хочет занять первое место в тесте. Итак, Атхарв запомнил все 8 рядов данных, и теперь он может правильно сказать значение c для заданных a и b при условии, что они получены из приведенных выше данных. Он действительно думает, что выиграет. Будет ли он?
Другая ваша подруга, Дхрити, нашла этот тест забавным не потому, что ей не нужно было делать домашнюю работу, а потому, что она действительно хочет доказать всем в классе свою сообразительность. 30 минут она билась и придумывала разные уравнения. Когда 30 минут истекли, все, что у нее было, это a + b = c.
Пришло время все проверить.
Теперь, к несчастью для Атхарва, ни одно из значений в тесте не было получено из предоставленных ему данных, и он был крайне разочарован, так как набрал 0 баллов и теперь должен был делать домашнее задание. Дхрити тоже была очень расстроена, так как ее уравнение не сработало. Но когда она узнала, что уравнение было a2 + b2 = c2, она подумала, что если бы у нее было немного дополнительного времени, то она могла бы составить и это уравнение.
Теперь, когда у нас есть некоторая предыстория, мы все готовы понять недообучение и переоснащение, но перед этим нам нужно прояснить некоторую терминологию.
Шум. Любые ненужные или нерелевантные данные, которые могут снизить производительность нашей модели, называются шумом.
Сигнал. Истинный базовый шаблон данных, который помогает модели машинного обучения учиться на данных, называется сигналом.
Смещение. Чтобы упростить изучение взаимосвязи между входными и выходными данными, модель имеет тенденцию делать определенные предположения, известные как смещение.
Дисперсия. По определению это своего рода ошибка, возникающая из-за чувствительности любой модели к небольшим колебаниям в наборе обучающих данных. Дисперсия — это просто мера, до которой ваша модель реагирует (с точки зрения показателей производительности) на изменения в наборе обучающих данных.
Соответствие — насколько хорошо вы приближаетесь к целевой функции.
Что такое переоснащение?
Возвращаясь к нашему уроку математики, то, что сделал Атхарв, называется переоснащением. Он запоминал все, что ему давали в наборе данных, но не мог хорошо справляться с какими-либо новыми данными, которые ему давали. Его результаты слишком сильно зависели от предоставленных ему тренировочных данных.
Та же концепция применима и к нашим моделям машинного обучения. Когда модель слишком хорошо усваивает обучающие данные, она в значительной степени усваивает базовый шаблон и шум в обучающих данных. Это негативно влияет на производительность модели на любых новых или невидимых данных. Это означает, что модель изучила случайные колебания или любой шум в обучающих данных как понятия. В чем проблема с этим? Проблема в том, что если есть какие-то невидимые данные, мы не можем применить эти концепции, и модель становится неспособной обобщать.
Давайте сравним обычную модель и переобученную модель с помощью графика.

Что мы подразумеваем под Generalize здесь?
Обобщение — это, по сути, мера, которая помогает узнать, насколько хорошо обучена конкретная модель или насколько хорошо она усвоила шаблоны, и как она работает или применяется к невидимым данным. Цель любой модели — хорошо работать с новыми данными из проблемной области при условии, что входные и выходные функции остаются неизменными.
Возвращаясь к переоснащению, давайте возьмем другой пример. Допустим, вы приехали в город «Х», и, поскольку вы там новичок, уличные торговцы берут с вас цену выше реальной, а таксисты берут чрезмерно высокую плату за проезд. И что ты тогда делаешь? Вы решаете, что жители этого города нечестны. Это общечеловеческая черта «обобщения».
Может быть, другой таксист берет с вас правильную, а не более высокую плату за проезд, вы все равно не верите этому водителю, и предполагаете, что он нечестен на основании вашего прошлого опыта. Это еще один пример «переоснащения» (или чрезмерного обобщения). Всякий раз, когда модель переоснащается, мы говорим, что модель имеет «высокую дисперсию». Если мы возьмем в качестве примера стрельбу по мишеням или стрельбу из лука, то высокая дисперсия по этой аналогии будет эквивалентна неустойчивому прицеливанию.
Исходя из этого, мы можем сказать, что если какая-либо модель хорошо работает с невидимым набором данных, то она хорошо подходит или лучше всего подходит. Но если он плохо работает на тестовом наборе данных, но достаточно хорошо работает на обучающем наборе данных, то это переобучение.
Что такое недообучение?
Помните Дхрити? Что она сделала? Ее подход определенно был хорош. Она старалась изо всех сил, но не могла найти правильную формулу. Ее работа не нашла хороших результатов в данных, предоставленных учителем, и, конечно же, не нашла хороших результатов в тесте. Это то, что мы называем недообучением в машинном обучении. Если бы ей дали больше случаев, она бы отследила аналогичные результаты на тестовом наборе. Это то, что мы называем «высокой предвзятостью».
Возвращаясь к нашему примеру со стрельбой из лука, вот как высокая/низкая дисперсия и смещение влияют на производительность модели:

Таким образом, мы можем резюмировать, что модель недостаточного соответствия не может достаточно хорошо обобщать новые данные и не может даже моделировать базовые обучающие данные, и лучше всего подходит, когда смещение, а также дисперсия низки.
ПРИМЕЧАНИЕ. Ниже приведено более наглядное представление недообучения и переоснащения, которое включает в себя некоторый код и графики. Даже если вам не очень нравится раздел кода, не волнуйтесь, графики дадут вам четкое представление о теме. Вы уже поняли, что такое переоснащение и недообучение!
Чтобы лучше понять это, давайте рассмотрим пример. Мы собираемся сгенерировать две переменные, скажем, P и Q. P будет иметь несколько случайных чисел/выборок, а Q будет частью функции косинуса.
На основе данных давайте создадим график, простой график между P и Q. Мы не будем обсуждать значения переменных или то, как мы их получили. Мы собираемся сосредоточиться на том, как степень полиномов влияет на соответствие нашей модели.
Вау! Большие сроки! Что означают эти термины?
Распространенной практикой в машинном обучении является создание новых функций путем возведения существующих функций в степень. Например, если бы у нас была одна входная функция Z, то «полиномиальная функция» была бы добавлением нового столбца, который является новой функцией. В этом столбце у нас есть значения Z2, как в квадратах значений в столбце Z. Почему мы это делаем? Это может помочь в повышении производительности нашей модели.
Количество признаков, добавляемых в модель, можно контролировать с помощью «степени» полинома.
plt.plot(p, q, color = ‘c’, label=»Actual»)
plt.scatter(p, q, edgecolor=’r’, s=20, label=»Samples»)
plt.xlabel(«p»)
plt.ylabel(«q»)
plt.legend(loc=»best»)
plt.show()
Результатом этого кода, который дает нам базовую связь между p и q, является следующий график:

Теперь пришло время поместить эти значения в нашу модель. Мы собираемся использовать «линейную регрессию». Любопытный? Погугли это!
plt.plot(p, q, color = ‘c’, label=»Actual»)
plt.scatter(p, q, edgecolor=’r’, s=20, label=»Samples»)
plt.plot(p1, q_pred, label=»Model») # q_pred here is the prediction set of q values
plt.xlabel(«p»)
plt.ylabel(«q»)
plt.legend(loc=»best»)
plt.show()

Мы видим, что наша прямая линия (модель) не может уловить закономерности в данных. Это яркий пример недообучения.
Теперь, чтобы лучше понять, как степени полинома влияют на нашу модель, посмотрите на этот график:

Из приведенного выше графика, сравнивающего степени, мы можем заметить, что полинома со степенью 1 недостаточно для предсказания, он имеет большое смещение и, следовательно, является «недостаточным». Граф степени 4 подходит лучше всего; он почти идеально аппроксимирует исходное истинное соотношение между зависимыми и независимыми функциями для тестовых данных. Для степеней выше наилучшего соответствия очевидно, что модель является «переоснащением», и мы можем видеть это на примере степени 15. Эта модель переобучения изучила шум в данных и имеет высокую дисперсию.
Вот блок-схема, которая суммирует все, что обсуждалось выше.

Теперь мы знаем, что такое переоснащение и недооснащение, но как нам его обнаружить?
Обнаружение переобучения и недообучения
Можете ли вы обнаружить эти условия перед проверкой данных? Нет, это почти невозможно. Мы должны проверить это.
Одним из распространенных и эффективных методов является разделение набора данных на две части (это можно сделать разными способами — обратитесь к train_test_split в sklearn), а именно на обучающую и тестовую части. Если наша модель хорошо справляется с набором обучающих данных и достигает точности, скажем, 90%, но только с точностью около 50–55% на наборе тестовых данных, то модель, вероятно, переоснащается.
Однако, если все наоборот, как в случае недообучения, модель не гарантирует лучших результатов в тесте по сравнению с поездом. Он плохо работает как на обучающих, так и на тестовых наборах.
Если он хорошо работает с обоими наборами данных, то он, безусловно, подходит или лучше всего подходит.
Как предотвратить переоснащение и недооснащение
Перекрестная проверка — очень мощная профилактическая мера против переобучения с умной идеей. Создайте несколько мини-разбиений для проверки поезда в исходных данных поезда и используйте их для настройки модели.
У нас есть стандартный способ сделать это, называемый «к-кратной перекрестной проверкой». Что мы делаем здесь, так это разделяем набор данных на k подмножеств, которые мы называем «складки».
Затем мы итеративно обучаем нашу модель на k — 1 раз. Почему? Мы сохраняем последний в качестве набора данных проверки. Последняя складка называется «удерживающая складка».

Используя перекрестную проверку, вы можете настроить свои гиперпараметры только с исходным набором обучающих данных. Таким образом, вы можете сохранить проверочный набор как полностью невидимый набор данных.
K-кратная перекрестная проверка может не полностью устранить переоснащение, поэтому мы можем время от времени менять складки или использовать несколько k-кратных перекрестных проверок вместе.
Тренируйтесь с большим количеством данных
Сигнал будет лучше обнаружен алгоритмом, если мы обучим модель большим количеством данных. Хотя это работает не каждый раз, например, если мы просто добавим больше зашумленных данных, то этот прием не поможет.
Удалить функции
В алгоритмах, не имеющих встроенного выбора признаков, их обобщение можно улучшить вручную, удалив некоторые нерелевантные или неважные признаки. Почему удаление функций полезно? Иногда может случиться так, что модель не сможет обобщить просто потому, что модель пропустила закономерности, которые должны были быть обнаружены, а данные были слишком сложными для того же.
Регуляризация
Как мы обсуждали ранее, такое переоснащение может быть следствием слишком сложной модели. Можем ли мы силой сделать это проще? Да! Регуляризация — это термин, обозначающий ряд методов, которые можно использовать для упрощения вашей модели. Методы, используемые для регуляризации любой модели, будут зависеть от самой модели. Например, опцией может быть обрезка дерева решений, в нейронных сетях можно использовать отсев или, к функции стоимости в регрессии, можно добавить параметр штрафа. Запутанные термины, да? Гуглите их!
Предотвращение недообучения
Вероятной причиной недообучения может быть тот факт, что модель недостаточно сложна, чтобы понять основные закономерности в данных. Переключение, скажем, на нелинейную модель из линейной модели или, скажем, на добавление дополнительных скрытых слоев к вашей существующей нейронной сети может быть способом усложнить модель и, в свою очередь, может помочь в устранении недообучения.
Снижение регуляризации
Что ж, недообучение несколько близко к противоположности переоснащению. Итак, как мы читали ранее, регуляризация может помочь решить проблему переоснащения, а ее уменьшение может решить проблему недостаточного приспособления! Некоторые из алгоритмов, которые вы используете по умолчанию, включают некоторые параметры регуляризации, предназначенные для подавления переобучения. Иногда это также может мешать изучению алгоритма. Уменьшение их значений по большей части имеет значение. Вы, должно быть, думаете, что если недообучение почти противоположно переоснащению, то, может быть, добавление дополнительных функций или данных поможет решить проблему? НЕТ! Если в наборе данных отсутствуют решающие и важные признаки, которые могли бы помочь вашей модели в обнаружении закономерностей, вы можете умножить набор обучающих данных на 2, 5 или даже 10, но это не поможет улучшить ваш алгоритм. Распространено мнение, что добавление большего количества данных решит проблему, но, как говорилось ранее, это может просто поставить проект под угрозу.
Хорошо вписывается в статистическую модель
Прочитав все о переоснащении, недообучении и профилактических мерах, я уверен, что у вас есть приблизительное представление о «хорошей подгонке».
Хорошая посадка — это идеальная область между моделями с завышенной и нижней посадкой, чего, как правило, немного трудно достичь на практике. Чтобы достичь этого, мы оцениваем производительность алгоритма с течением времени, поскольку он продолжает изучать обучающие данные.
Со временем, по мере обучения алгоритма, ошибка модели в обучающих данных уменьшается, как и ошибка в тестовых данных. Если мы тренируемся очень долго, производительность набора обучающих данных может продолжать увеличиваться на том основании, что модель переобучается и изучает шум и закономерности в наборе обучающих данных. В то же время ошибка для тестового набора снова начинает расти по мере того, как способность модели к обобщению уменьшается.
Идеальная точка — перед тем, как ошибка на тестовом наборе начнет увеличиваться, когда модель хорошо поработала как на обучающем, так и на невидимом наборе.
Так что все это было в переобучении и недообучении, в будущем я буду публиковать больше таких статей.
Сущность и влияние на результаты
Дата публикации: 06 октября 2023
Среднее время чтения:
Основные понятия и определения
В мире, где машинное обучение становится инструментом создания новой реальности, понимание его ключевых концепций будет решающим для каждого специалиста. Давайте углубимся в терминологию.
Правильное понимание и использование этих концепций может стать ключом к созданию эффективных моделей, способных «работать» в реальном мире, а не только на бумаге.
Причины переобучения
Одним из наиболее коварных врагов на пути является переобучение. Но что стоит за этим явлением, и что провоцирует модель к такому поведению?
Переобучение – это не просто «болезнь» модели, это следствие ряда факторов. Распознавая их, мы делаем первый шаг к созданию более устойчивых и надежных систем машинного обучения.
Признаки переобучения
Есть ряд признаков, которые могут подсказать нам о наличии этой проблемы в моделях машинного обучения.
Дисбаланс производительности: Если модель демонстрирует высокую точность на обучающем наборе данных, но существенно «спотыкается» при встрече с тестовыми данными, это явный знак переобучения.
Слишком сложные границы решений: Иногда визуальный анализ границ решений может указывать на переобучение. Если границы выглядят избыточно изогнутыми или «капризными», модель может слишком усердно пытаться адаптироваться к каждой точке данных.
Стагнация или ухудшение производительности на валидационных данных: В начальной стадии обучения производительность модели на валидационных данных, как правило, улучшается. Однако с течением времени этот прогресс может замедлиться или даже начать ухудшаться, в то время как на обучающих данных показатели продолжат расти.
Значительные колебания в производительности при небольших изменениях в обучающем наборе: Если небольшие изменения или вариации в обучающих данных приводят к существенным колебаниям в результатах модели, это может свидетельствовать о её чрезмерной чувствительности.
В заключении, каждый из этих признаков является не только индикатором проблемы, но и путеводной звездой на пути к её решению. Чем глубже мы понимаем эти признаки, тем быстрее можем действовать, корректируя свою стратегию и улучшая качество модели.
Как переобучение связано с «слишком большим обучением» модели?
Загадочное переобучение — это парадокс в мире машинного обучения. Как может быть так, что чем больше модель учится, тем хуже она выполняет свои функции?
На первый взгляд, казалось бы, максимальное обучение модели — это залог успеха. Ведь чем больше данных для обучения, тем лучше модель понимает мир вокруг себя. Однако, как сказал бы классический философ: «Всё хорошо в меру».
При «слишком большом обучении» модель начинает улавливать не только основные закономерности в данных, но и все мельчайшие детали, аномалии и шумы. Это можно сравнить с человеком, который читает книгу, но, вместо того чтобы улавливать основной сюжет, он фиксирует внимание на каждой запятой, каждом пропущенном пробеле, на каждом незначительном исключении в тексте.
Если бы машинное обучение было музыкальным инструментом, «слишком большое обучение» можно было бы сравнить с ситуацией, когда музыкант становится настолько одержим отдельными нотами, что теряет из виду гармонию всей композиции.
Таким образом, когда модель «слишком много учится», она может превратиться в перфекциониста, потерявшего способность к генерализации. В итоге, при столкновении с новыми данными, она не может правильно интерпретировать их, так как зациклена на конкретиках обучающего набора.
Для специалистов в области IT это напоминание о том, что оптимальное обучение — это искусство, требующее баланса между глубоким погружением и способностью видеть большую картину.
Способы борьбы с переобучением
Каждый из этих методов — это инструмент в арсенале специалиста по машинному обучению. Но, как и с любым инструментом, ключ к успеху — в умении их правильно использовать. Не забывайте, что вашей целью является создание устойчивой и адаптивной модели, а не просто борьба с переобучением ради борьбы.
Остались вопросы?
Оставьте контактные данные и мы свяжемся с вами в ближайшее время
Время на прочтение

Переобучение (overfitting) — одна из проблем глубоких нейронных сетей (Deep Neural Networks, DNN), состоящая в следующем: модель хорошо объясняет только примеры из обучающей выборки, адаптируясь к обучающим примерам, вместо того чтобы учиться классифицировать примеры, не участвовавшие в обучении (теряя способность к обобщению). За последние годы было предложено множество решений проблемы переобучения, но одно из них превзошло все остальные, благодаря своей простоте и прекрасным практическим результатам; это решение — Dropout (в русскоязычных источниках — “метод прореживания”, “метод исключения” или просто “дропаут”).

Графическое представление метода Dropout, взятое из статьи, в которой он впервые был представлен. Слева — нейронная сеть до того, как к ней применили Dropout, справа — та же сеть после Dropout.
Сеть, изображенная слева, используется при тестировании, после обучения параметрам.
Главная идея Dropout — вместо обучения одной DNN обучить ансамбль нескольких DNN, а затем усреднить полученные результаты.
Сети для обучения получаются с помощью исключения из сети (dropping out) нейронов с вероятностью
, таким образом, вероятность того, что нейрон останется в сети, составляет
. “ Исключение” нейрона означает, что при любых входных данных или параметрах он возвращает 0.
Исключенные нейроны не вносят свой вклад в процесс обучения ни на одном из этапов алгоритма обратного распространения ошибки (backpropagation); поэтому исключение хотя бы одного из нейронов равносильно обучению новой нейронной сети.
В стандартной нейронной сети производная, полученная каждым параметром, сообщает ему, как он должен измениться, чтобы, учитывая деятельность остальных блоков, минимизировать функцию конечных потерь. Поэтому блоки могут меняться, исправляя при этом ошибки других блоков. Это может привести к чрезмерной совместной адаптации (co-adaptation), что, в свою очередь, приводит к переобучению, поскольку эти совместные адаптации невозможно обобщить на данные, не участвовавшие в обучении. Мы выдвигаем гипотезу, что Dropout предотвращает совместную адаптацию для каждого скрытого блока, делая присутствие других скрытых блоков ненадежным. Поэтому скрытый блок не может полагаться на другие блоки в исправлении собственных ошибок.
В двух словах, Dropout хорошо работает на практике, потому что предотвращает взаимоадаптацию нейронов на этапе обучения.
Получив приблизительное представление о методе Dropout, давайте рассмотрим его подробнее.
Как работает Dropout
Как уже говорилось, Dropout выключает нейроны с вероятностью
и, как следствие, оставляет их включенными с вероятностью
Вероятность выключения каждого нейрона одинакова. Это означает следующее:
применение Dropout к данной проекции на этапе обучения можно представить как измененную функцию активации:
-мерный вектор случайных величин
Очевидно, что эта случайная величина идеально соответствует Dropout, примененному к одному нейрону. Действительно, нейрон выключают с вероятностью
, в противном случае — оставляют включенным.
Посмотрим на применение Dropout к i-му нейрону:
Так как на этапе обучения нейрон остается в сети (не подвергается выключению) с вероятностью q, на этапе тестирования нам необходимо эмулировать поведение ансамбля нейронных сетей, использованного при обучении. Для этого авторы предлагают на этапе тестирования умножить функцию активации на коэффициент q. Таким образом,
На этапе обучения:
На этапе тестирования:
Обратный (Inverted) Dropout
Возможно использовать немного другой подход — обратный Dropout. В данном случае мы умножаем функцию активации на коэффициент не во время тестового этапа, а во время обучения.
Коэффициент равен обратной величине вероятности того, что нейрон останется в сети:
,На этапе тестирования:
Во многих фреймворках для глубокого обучения Dropout реализован как раз в этой модификации, так как при этом необходимо лишь однажды описать модель, а потом запускать обучение и тестирование на этой модели, меняя только параметр (коэффициент Dropout).
В случае прямого Dropout мы вынуждены изменять нейронную сеть для проведения тестирования, так как без умножения на q нейрон будет возвращать значения выше, чем те, которые ожидают получить последующие нейроны; именно поэтому реализация обратного Dropout встречается чаще.
Dropout множества нейронов
Легко заметить, что слой
нейронов на отдельном шаге этапа обучения можно рассматривать как ансамбль из
экспериментов Бернулли с вероятностью успеха
Таким образом, на выходе слоя
Так как каждый нейрон представлен в виде случайной величины, распределенной по закону Бернулли, и все эти величины независимы, общее число исключенных нейронов — также случайная величина, но имеющая биномиальное распределение:
успешных событий за
Эту формулу легко объяснить следующим образом:
Теперь мы можем использовать это распределение, чтобы рассчитать вероятность отключения определенного количества нейронов.
Используя метод Dropout, мы фиксируем коэффициент Dropout
Например, если слой, к которому мы применили Dropout, состоит из
Как видим, вероятность отключения ровно
Следующий скрипт на Python 3 поможет представить, сколько нейронов будет выключено для разных значений
и зафиксированного количества

Биномиальное распределение достигает максимума в районе
Как видим из изображения выше, для любого
среднее количество выключенных нейронов пропорционально
Более того, можно заметить, что распределение значений почти симметрично относительно
и вероятность выключения
нейронов возрастает по мере того, как увеличивается расстояние от
Коэффициент масштабирования введен авторами для компенсации значений активации, так как на этапе обучения используется лишь доля от
нейронов, в то время как на этапе тестирования все 100% нейронов остаются включенными, и, следовательно, полученные значения необходимо уменьшить с помощью специального коэффициента.
Dropout и другие регуляризаторы
Dropout часто используется с L2-нормализацией и другими методами ограничения параметров (например, Max Norm). Методы нормализации помогают поддерживать невысокие значения параметров модели.
Вкратце, L2-нормализация представляет собой дополнительный элемент функции потерь, где
— гиперпараметр, называемый “сила регуляризации” (regularization strength),
— модель, а
— функция ошибки между реальным значением
Нетрудно понять, что этот дополнительный элемент сокращает величину, на которую изменяется параметр во время обратного распространения ошибки методом градиентного спуска. Если
— коэффициент скорости обучения, то параметр
Dropout сам по себе не может предотвратить рост значений параметров на этапе обновления. Более того, обратный Dropout ведет к тому, чтобы шаги обновления стали даже больше, как показано ниже.
Обратный Dropout и другие регуляризаторы
Так как Dropout не предотвращает роста параметров и их переполнения, нам может помочь L2-регуляризация (или любой другой метод регуляризации, ограничивающий значения параметров).
Если мы представим коэффициент Dropout в явном виде, уравнение выше превратится в следующее:
Нетрудно заметить, что в случае обратного Dropout скорость обучения масштабируется с помощью коэффициента
. Так как
, отношение между
Поэтому отныне мы будем называть
ускоряющим множителем (boosting factor), так как он увеличивает скорость обучения.
будем называть эффективной скоростью обучения (effective learning rate).
Эффективная скорость обучения выше, чем скорость обучения, выбранная нами: таким образом метода нормализации, ограничивающие значения параметров, могут упростить процесс выбора скорости обучения.
О, а приходите к нам работать? 🙂
wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io

В этой статье я расскажу о различных методах, которые можно использовать для устранения переобучения и неполного подбора. Я кратко расскажу о недостаточном и переобучении, а затем расскажу о методах их устранения.
Вступление
В одной из своих предыдущих статей я говорил о компромиссе смещения и дисперсии. Мы говорили о связи смещения и дисперсии со сложностью модели и о том, как выглядит недостаточное и переобучение. Я рекомендую вам прочитать эту статью, если вы не понимаете эти термины:
Для краткого обзора давайте посмотрим на следующий рисунок.
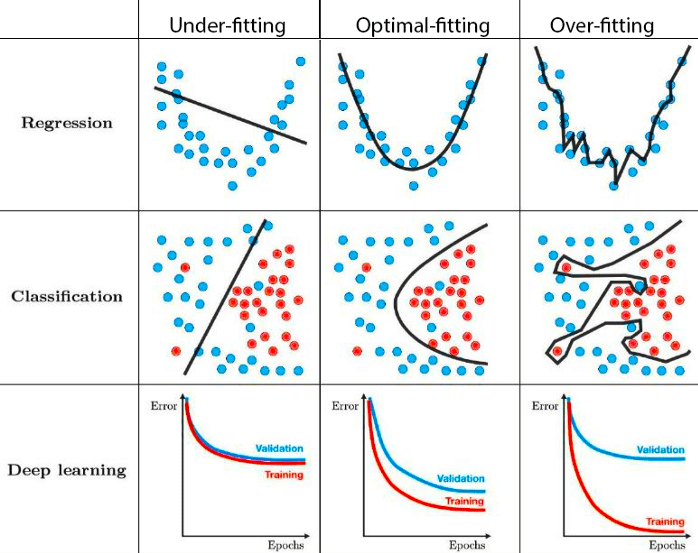
Недооценка возникает, когда модель имеет очень высокий уровень смещения и не может уловить сложные закономерности в данных. Это приводит к большему количеству ошибок обучения и проверки, поскольку модель недостаточно сложна для классификации базовых данных. В приведенном выше примере мы видим, что данные имеют отношение второго порядка, но модель является линейной, поэтому она не сможет
Переобучение является противоположным в том смысле, что модель слишком сложна (или модель более высокого уровня) и улавливает даже шум в данных. Следовательно, в этом случае будет наблюдаться очень низкое значение ошибки теста. Однако, когда его не удастся обобщить как на наборы проверки, так и на наборы тестов.
Мы хотим найти оптимальную подгоночную ситуацию, когда модель имеет меньший разрыв между значениями ошибки обучения и проверки. Следует лучше обобщить, чем в двух других случаях.
Как справиться с недостаточным оснащением
В отличие от переобучения, существует несколько методов переобучения, которые можно попробовать использовать. Давайте посмотрим на них по очереди.
1. Получите больше данных для обучения. Хотя получить больше данных не всегда возможно, получение более репрезентативных данных чрезвычайно полезно. Наличие более крупного разнообразного набора данных обычно способствует повышению производительности модели. Вы можете получить лучшую модель, которая может лучше обобщать. Это означает, что производительность модели на невидимых данных (истинный набор тестов) будет лучше.
2. Расширение. Если вы не можете получить больше данных, вы можете попробовать расширение, чтобы добавить вариации в свои данные. Увеличение означает искусственное изменение существующих данных с помощью преобразований, которые напоминают вариации, которые вы можете ожидать в реальных данных. Для данных изображений https://imgaug.readthedocs.io/en/latest/ — это очень обширная библиотека, которая дает вам массу методов увеличения. Он позволяет быстро и эффективно составлять мощные последовательности аугментаций. Я бы порекомендовал следующие две статьи для дальнейшего чтения. У Ольги Черницкой есть подробная статья об увеличении изображений, которую вам стоит прочитать. Валентина Альто прекрасно объясняет, как происходит увеличение изображения в Керасе в этой статье.
4. Регуляризация L1, L2: регуляризация — это дополнительный член, который добавляется к функции потерь, чтобы наложить штраф на большие веса параметров сети для уменьшения переобучения. L1 и L2 регуляризация — два широко используемых метода. Хотя они наказывают большие веса, они оба достигают регуляризации по-разному. Регуляризация L1: регуляризация L1 добавляет масштабированную версию нормы L1 параметров веса к функции потерь. Уравнение регуляризации L1:
Регуляризация L2: мы добавляем квадрат L2 нормы весов к функции затрат / потерь / целевой функции. Уравнение регуляризации L2 выглядит следующим образом:
где η — скорость обучения
Мы видим, что старые веса масштабируются на (1-ηλ) или исчезают с каждым обновлением градиента. Таким образом, регуляризация L2 приводит к меньшим весам. Из-за этого это также иногда называют потерей веса. Для подробного объяснения я настоятельно рекомендую вам прочитать эту статью из ускоренного курса машинного обучения Google: Регуляризация для простоты: L₂ Регуляризация

Отсев гарантирует, что ни один нейрон в конечном итоге не будет слишком полагаться на другие нейроны и вместо этого узнает что-то значимое. Выпадение может применяться после сверточных, объединяющих или полносвязных слоев.

где r — выход уровня, v — вход уровня, W — весовые параметры, M — матрица маски для отсечения случайных связей, которые выводятся из распределения Бернулли с вероятностью p. Каждый элемент маски M рисуется независимо для каждого примера во время обучения. В результате этих случайных разрывов соединений мы получаем динамическую разреженность в весах нашей сети, что приводит к уменьшению чрезмерной подгонки.
