
Коллокации — это фразы или выражения, состоящие из нескольких слов, которые с высокой вероятностью могут встречаться одновременно. Например — «социальные сети», «школьные каникулы», «машинное обучение», «Universal Studios Singapore» и т. д.
.
Словосочетания
два или более слова, которые часто встречаются вместе, например – Соединенные Штаты
. Есть много других слов, которые могут идти после United, например, United Kingdom и United Airlines. Как и во многих аспектах обработки естественного языка, контекст очень важен. А для словосочетаний контекст — это все. В случае словосочетаний контекстом будет документ в виде списка слов. Обнаружить словосочетания в этом списке слов означает найти общие фразы, которые часто встречаются в тексте. 
Ссылка на ДАННЫЕ –
Монти Пайтон и сценарий Святого Грааля
Код №1: Загрузка библиотек
# Инструментарий естественного языка: словосочетания и меры ассоциации # URL: # Информацию о лицензии см. в разделе ЛИЦЕНЗИЯ. ТХТ Инструменты для определения словосочетаний --- слова, которые часто появляются подряд --- внутри корпуса. Их также можно использовать для поиска других ассоциаций между См. Manning and Schutze гл. 5 на https://nlp.stanford.edu/fsnlp/promo/colloc.pdf и пакет Text::NSP Perl на http://ngram.sourceforge.net Для поиска словосочетаний необходимо сначала вычислить частоты слов и их появление в контексте других слов. Часто сборник слов тогда потребуется фильтрация, чтобы сохранить только полезные термины контента. Каждый нграмм слов затем можно оценить в соответствии с некоторой мерой ассоциации, чтобы , чтобы определить относительную вероятность того, что каждая нграмма является словосочетанием. Классы ``BigramCollocationFinder`` и ``TrigramCollocationFinder`` предоставляют эти функциональные возможности, в зависимости от предоставления функции, которая оценивается нграмм с учетом соответствующих частот. Ряд стандартных ассоциаций меры представлены в bigram_measures и trigram_measures. # Возможные задачи: # - рассмотрим разницу между f(x,_) и f(x) и будет ли наш # аппроксимация достаточно хороша для фрагментированных данных, и упомяните об этом # — добавить средство поиска коллокаций n-грамм с мерами, которые используют только n-граммы # и количество униграмм (raw_freq, pmi, Student_t) # на эти два неиспользуемых импорта есть ссылки в collocations.doctest Абстрактный базовый класс для поиска словосочетаний, целью которого является собирает частоты кандидатов на словосочетания, фильтрует и ранжирует их. Как минимум, средства поиска коллокаций требуют частоты каждого слово в корпусе и совместная частота кортежей слов. Эти данные следует предоставить через nltk.probability. Объекты FreqDist или Заполните документ заполнителем в соответствии с размером окна """Создает средство поиска словосочетаний по набору документов, , каждый из которых представляет собой список (или повторяемый) токенов. # return cls.from_words(_itertools.chain(*documents)) """Общий фильтр удаляет нграммы из распределения частот , если функция возвращает True при передаче кортежа ngram. """Удаляет кандидатные nграммы, частота которых меньше min_freq.""" имеет значение True. """ Формирует пары (нграмм, оценка) в соответствии с оценкой """Возвращает последовательность пар (нграмм, оценка), упорядоченных от наибольшего до . наименьший балл, определенный с помощью предоставленной функции оценки. """Возвращает первые n граммов при оценке заданной функцией.""" """Возвращает последовательность нграмм, упорядоченную по убыванию значения, чья баллов превышают заданный минимальный балл."""Находит словосочетания биграмм в файлах корпуса WebText.""" # Слишком сильно замедляет загрузку # bigram_measures = BigramAssocMeasures() # trigram_measures = TrigramAssocMeasures()

- Джейми Лу
- Блог
- О
- Часть I: Парсинг веб-страниц
- Часть II: Обработка текста
- Часть III: Словосочетания
- Заключение
- Методы корпусной лингвистики #
- Подготовка данных корпуса #
- Коллокации #
- Применить фильтры #
- POS-сочетания #
- Коллокации, основанные на пропущенных биграммах #
- Подсчет Нграмм #
- Получить n-граммы #
- Дисперсия #
- Дельта П #
- Проверка точности вычислений #
- Согласие #
- Список частот #
- Список условных частот #
- Зачем нужны словосочетания?
- Питон3
- Пример использования словосочетаний¶
- Коллокации ¶
- Обзор ¶
- Искатели ¶
- Фильтрация кандидатов ¶
- Использование значений таблицы сопряженности ¶
- Ранжирование и корреляция ¶
- Ключевые слова ¶
- Нлтк. словосочетания. BigramCollocationFinder¶
- Основная идея
- Питон3
- Питон3
- Решение для автоматического извлечения ключевых слов из документов. Реализовано на Python с помощью NLTK и Scikit-learn.
Джейми Лу
Аналитика и проектирование данных
Блог
О
- Коллокации
- Биграм
- Триграмма
21 июля 2019 г.
Основываясь на моем предыдущем посте об обработке текста в Python, в котором описывался анализ отдельных слов из текстового резюме. В этом посте объясняется, как идентифицировать фразы из 2 и 3 слов .
с веб-страницы, в частности, фильтруя большой корпус текста на биграммы и триграммы с помощью пакета словосочетаний. Для анализа я выбрал текст со страницы википедии о песне «Надежда»
от The Chainsmokers, один из самых популярных саундтреков на Spotify, с которым я недавно столкнулся.
Часть I: Парсинг веб-страниц
Сначала укажите URL-адрес веб-страницы для выполнения обработки текста.
urllib.request
Модуль поможет нам сканировать веб-страницу, получая несколько элементов, таких как теги HTML, CSS, JavaScript и веб-контент.
Мы будем использовать Красивый суп
это библиотека Python для извлечения данных из файлов HTML и XML. BeautifulSoup предоставляет простой способ поиска текстового содержимого (т. е. не HTML) из HTML:
Однако найденный текст, скорее всего, будет содержать несколько элементов, которые мы не хотим включать в наше упражнение по предварительной обработке текста. Составьте список ненужных предметов и сохраните его как blacklist
.
Часть II: Обработка текста
Сначала загрузите библиотеку Python Natural Language Toolkit (NLTK):
Это позволит загрузчику NLTK выбрать, какие пакеты необходимо установить. Я скачал All Collections
для этого упражнения.
Далее нам нужно преобразовать весь выходной текст в нижний регистр, поскольку «Надежда» и «Надежда» будут читаться как два разных слова.
# convert output text to lowercase
Теперь у нас есть список текста в нижнем регистре, полученный с веб-страницы, давайте преобразуем выходной_нижний в токены слов.
Далее, чтобы нормализовать токенизированные слова
, нам нужно удалить знаки препинания и пустые строки ''
от word_tokens
:
# remove empty strings
Часть III: Словосочетания
Коллокации — это выражения, состоящие из двух или более слов, которые соответствуют некоторому общепринятому способу высказывания вещей. Коллокации включают такие существительные, как романтическая любовь .
и оружие массового поражения
, фразовые глаголы типа , чтобы составить
и другие стандартные фразы, такие как богатые и влиятельные.
Коллокации важны для ряда приложений: генерация естественного языка (чтобы убедиться, что результат звучит естественно и ошибки, такие как идеализированная любовь
или принять решение
избегаются), компьютерная лексикография (для автоматического определения важных словосочетаний, которые будут перечислены в словарной статье), синтаксический анализ (чтобы можно было отдать предпочтение синтаксическому анализу с естественными словосочетаниями) и корпусные лингвистические исследования.
Теперь давайте добавим пакет словосочетаний из библиотеки nltk. Пакет словосочетаний предоставляет средства поиска словосочетаний, которые по умолчанию рассматривают все ngrams в тексте как возможные словосочетания:
Всех нграмм в тексте зачастую слишком много, чтобы их можно было использовать при поиске словосочетаний. Обычно полезно удалить некоторые стоп-слова или знаки препинания и установить минимальную частоту использования возможных словосочетаний.
#get english stopwords
#function to filter for ADJ/NN bigrams
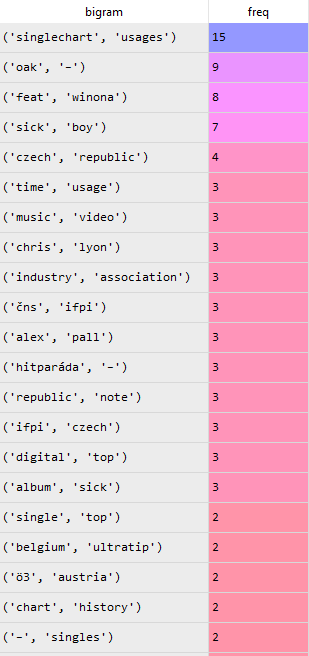
Выходные данные кадра filtered_bi
будет выглядеть так:
Теперь попробуем отфильтровать триграммы:
#function to filter for trigrams
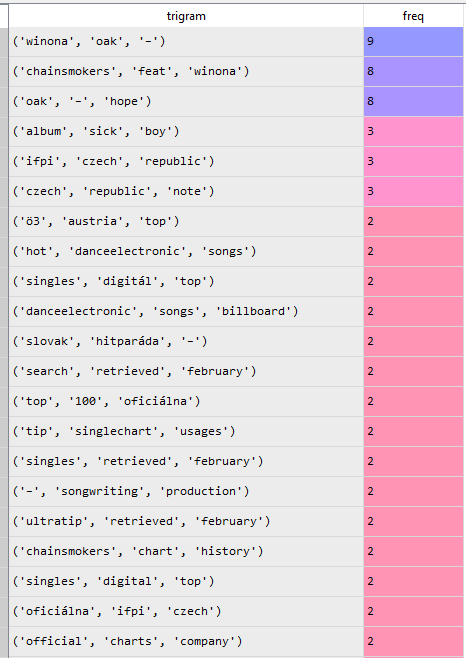
Выходные данные кадра filtered_tri
будет выглядеть так:
Заключение
Из результатов отфильтрованных биграмм и триграмм мы можем примерно сделать несколько выводов:
- Песня «Hope» — результат сотрудничества The Chainsmokers и Вайноны Оук.
- Это популярная танцевальная электронная песня, которая попала в чарты рекламных щитов.
- А для поклонников The Chainsmokers вы, вероятно, легко определите, что песня «Hope» — один из синглов со второго студийного альбома The Chainsmokers под названием
Sick Boy.
.
Интересно, не правда ли?
Методы корпусной лингвистики #
С
, мы легко можем реализовать немало корпусно-лингвистических методовАнализ соответствия (простой поиск слов)
Анализ данных с помощью R
Анализ соответствия (паттерны, конструкции?)
Образцы в строках предложений
Шаблоны в строках словесных тегов предложений
Подготовка данных корпуса #
Коллокации #
: Получите
который мы можем использовать для поиска n-грамм
: Получите
для определения словосочетаний (также доступно в
)Использовать
методы выбора/фильтрации словосочетаний
## Словосочетания на основе текста
## биграммные словосочетания, основанные на различных мерах ассоциации
[('10 000 долларов в год', 'Рождённый во Франции'),
(«79,89 долларов», «ничего»),
(«$8,50», «вкладка»),
(«низкий», «негра»),
(«0,5 мВ/м», «50 процентов»),
('0,78', 'мэкв'),
(«1100», «ограничения»),
(«1 257 700», «несельскохозяйственные»),
(«11 дюймов», «запас высоты»),
(«11 выстрелов», «Безударный»)]
Применить фильтры #
Мы можем создать анонимную функцию в качестве помощника для удаления ненужных токенов слов перед вычислением словосочетания.
Например, удалим:
токены слов, длина символов которых < 3
жетоны слов, относящиеся к стоп-словам
словесные токены, содержащие хотя бы один неалфавитный символ
## Применить фильтры на основе частоты для биграммных словосочетаний ## Применить функцию фильтрации слов # фильтр по лексемам слов # фильтр по биграммным минимальным частотам
[('Гонконг'),
(«Вьет», «Нам»),
(«Патет», «Лао»),
(«Симмс», «Пурдью»),
('Внутренний доход'),
('Пуэрто-Рико'),
(«Саксонец», «Берег»),
(«углерод», «тетрахлорид»),
(«незамужние», «матери»),
('Вооруженные силы')]
POS-сочетания #
## Создание коллокаций только на основе тегов
[('ADP', 'DET'),
(«ДЕТ», «СУЩЕСТВИТЕЛЬНОЕ»),
(«ПРОН», «ГЛАГОЛ»),
(«ADJ», «СУЩЕСТВИТЕЛЬНОЕ»),
('СУЩЕСТВИТЕЛЬНОЕ', '.'),
(«СУЩЕСТВИТЕЛЬНОЕ», «ДЕТ»),
(«ДЕТ», «АДЖ»),
(«СУЩЕСТВИТЕЛЬНОЕ», «АДП»),
(«ПРТ», «ГЛАГОЛ»),
(«ADP», «.»)]
Коллокации, основанные на пропущенных биграммах #
## Создание словосочетаний с промежуточными словами (n-граммы с пробелами)
[('Соединенные Штаты'),
('Нью-Йорк'),
('процент'),
('Род-Айленд'),
('много лет назад'),
('Лос-Анджелес'),
('Белый дом'),
('Корпус мира'),
('Мировая война'),
('Сан-Франциско')]
Подсчет Нграмм #
[(('Соединенные Штаты', 'Штаты'), 0,0003375841376792124),
(('Нью', 'Йорк'), 0,00025491047130879306),
(('за', 'цент'), 0,00012573286760501277),
(('лет', 'назад'), 0,0001171210273580941),
(('The', 'первый'), 8.267366637041936e-05),
(('Род', 'Остров'), 7.750656222226816e-05),
(('мог', 'видеть'), 7.492301014819255e-05),
(('прошлый', 'год'), 5.856051367904705e-05),
(('первый', 'время'), 5.769932965435518e-05),
(('Белый', 'Дом'), 5.5976961604971446e-05)]
('Гонконг')
(«Вьет», «Нам»)
(«Патет», «Лао»)
(«Симмс», «Пурдью»)
('Внутренний доход')
('Пуэрто-Рико')
(«Саксонец», «Берег»)
(«углерод», «тетрахлорид»)
(«незамужние», «матери»)
Получить n-граммы #
— это распаковка вложенного списка и использование каждого элемента в качестве входных данных для вызова функции.
Поэтому мы можем использовать
чтобы отменить вложенный список. (Похоже на
в Р.
[(1, 2), (2, 3), (3, 4)]
[(1, 2, 3), (2, 3, 4), (3, 4, 5)]
Дисперсия #
Рассредоточение языковой единицы также важно.
Должен быть показатель, показывающий, насколько равномерно распределена языковая единица.
Как получить документальную частоту биграмм???
# список частот ngram каждого файла в корпусе
## Функция для получения униграммной дисперсии
# Словарь нельзя разрезать/подмножество # Получить элементы() и преобразовать в список для подмножества
[('The', 500),
(«Фултон», 3),
(«Каунти», 45),
(«Гранд», 17),
(«Жюри», 4),
(«сказал», 314),
(«Пятница», 34),
(«ан», 498),
(«расследование», 34),
('из', 500),
(«Атланта», 2),
(«недавний», 114),
(«первичный», 59),
(«выборы», 28),
(«произведено», 66),
('``', 462),
(«нет», 455),
(«доказательства», 119),
(«''», 463),
(«это», 500)]
[('The_Fulton', 1),
(«Фултон_Каунти», 6),
(«Каунти_Гранд», 1),
(«Большое_Жюри», 2),
(«Жюри_сказал», 1),
(«сказал_Пятница», 4),
(«Пятница_ан», 1),
(«ан_расследование», 7),
('расследование_оф', 15),
("Из_Атланты", 1),
(«Последние_Атланты», 1),
('recent_primary', 1),
('primary_election', 2),
('election_produced', 1),
('произведено_``', 1),
('``_нет', 6),
('no_evidence', 14),
("evidence_''", 3),
(«''_это», 16),
('that_any', 31)]
[('The_Fulton', 1),
(«Фултон_Каунти», 1),
(«Каунти_Гранд», 1),
(«Большое_Жюри», 2),
(«Жюри_сказал», 1),
(«сказал_Пятница», 3),
(«Пятница_ан», 1),
(«ан_расследование», 7),
(«расследование_оф», 14),
("Из_Атланты", 1),
(«Последние_Атланты», 1),
('recent_primary', 1),
('primary_election', 2),
('election_produced', 1),
('произведено_``', 1),
('``_нет', 6),
('no_evidence', 12),
("evidence_''", 3),
(«''_это», 16),
('that_any', 30)]
Мы можем реализовать метрику дисперсии Delta P, предложенную Грайсом (2008)
.
Дельта П #
Это показатель направленной ассоциации.
## Наследовать BigramAssocMeasures """Оценивает нграммы по их частоте""" """Вычисляет биграммы с использованием DP вперед Это может быть показано относительно таблицы непредвиденных обстоятельств:: w1 ~w1 = n_ix ВСЕГО = n_xx """Вычисляет биграммы, используя DP в обратном направлении Это может быть показано относительно таблицы непредвиденных обстоятельств:: w1 ~w1 = n_ix ВСЕГО = n_xx
[(('10 000 долларов в год', 'Рожденный во Франции'), 1.0),
(('$79,89', 'ничего'), 1,0),
(('$8,50', 'вкладка'), 1,0),
(("низкий", "негры"), 1.0),
(('0,5-мв./м', '50-процент'), 1,0),
(('0,78', 'мэкв'), 1,0),
(('1100', 'ограничения'), 1,0),
(('1 257 700', 'несельскохозяйственное'), 1,0),
(('11 дюймов', 'высота'), 1,0),
(('11-зарядный', 'безударный'), 1.0)]
[(('10 000 долларов в год', 'Рожденный во Франции'), 1.0),
(('$79,89', 'ничего'), 1,0),
(('$8,50', 'вкладка'), 1,0),
(("низкий", "негры"), 1.0),
(('0,5-мв./м', '50-процент'), 1,0),
(('0,78', 'мэкв'), 1,0),
(('1100', 'ограничения'), 1,0),
(('1 257 700', 'несельскохозяйственное'), 1,0),
(('11 дюймов', 'высота'), 1,0),
(('11-зарядный', 'безударный'), 1.0)]
Проверка точности вычислений #
Проверьте правильность расчета DP.
[(('из', 'the'), 9625.0),
((',', 'и'), 6288.0),
(('.', 'The'), 6081.0),
(('в', 'the'), 5546.0),
((',', 'the'), 3754.0),
(('.', '``'), 3515.0),
(('к', 'the'), 3426.0),
(("''", '.'), 3332.0),
((';', ';'), 2784.0),
(('.', 'Он'), 2660.0)]
w1 _w1 w2 w1w2 ____ w2f _w2 ____ ____ w1f corpus_size
36080 62713 9625,0 1161192
'Delta P вперед для `of the`:' 'Delta P назад для `of the`:'
Дельта П Форвард для `из`: 0,2195836568422283
Дельта P назад для `из`: 0,12939364991590951
[0,2195836568422283]
[0,12939364991590951]
Как реализовать дельта П триграмм?
# наследовать Триграмму Коллекция мер ассоциации триграмм. Каждая мера ассоциации предоставляется как функция с четырьмя аргументами:: (n_iix, n_ixi, n_xii), (n_ixx, n_xix, n_xxi), Аргументы представляют собой маргинальные значения таблицы сопряженности, считая возникновение определенных событий в корпусе. Буква я в Суффикс указывает на появление рассматриваемого слова, а x указывает на появление какого-либо слова. Так, например: n_iii учитывается (w1, w2, w3), т.е. оцениваемая триграмма n_ixx считается (w1, *, *) n_xxx считается (*, *, *), т.е. любая триграмма Оценивает триграммы с использованием дельты P вперед, т.е. условной вероятности w3 с учетом w1,w2 минус условная вероятность w3, при отсутствии w1,w2 Оценивает триграммы с использованием дельты P в обратном направлении, т.е. условную проверку w1 с учетом w2,w3 минус условная вероятность w1, при отсутствии w2,w3
[("Лекарство", "химическое вещество", "название"),
(«Браун», «&», «Шарп»),
(«Б.», «&», «О.»),
('доход на душу населения'),
(«Джон», «А.», «Нотте»),
(«средний», «на душу населения»),
(«Генерал», «Моторс», «Сток»),
(«базовый», «заработная плата», «ставка»),
(«Мир», «Война», «2»),
('Газета "Нью-Йорк Таймс')]
[('the', 'Ло', 'Шу'),
(«средний», «на душу населения»),
(«из», «Экономический», «Дела»),
(«the», «минимальный», «полиномиальный»),
(«Б.», «&», «О.»),
(«The», «Экспорт-Импорт», «Банк»),
('Торговая палата'),
(«Нотте», «,», «младший»),
('.', «Наркотики», «химия»),
(«т.», «Юнайтед», «Штаты»)]
[('Пуэрто-Рико', ','),
('Лос-Анджелес', ','),
(«доминант», «стресс», «воля»),
('пару недель'),
(«А.», «Нотте», «,»)),
(«Соединенные Штаты», «Штаты», «есть»),
(«Браун», «&», «Шарп»),
(«Отдел», «Отдел», «Экономический»),
('мальчики и девочки'),
(«Генерал», «Моторс», «Сток»)]
Согласие #
## Простые симфонии
Показаны 5 из 569 совпадений:
завтра вечером передаст американскому народу по общенациональному телевидению
налоги на социальное обеспечение для 70 миллионов американских рабочих будут повышены, чтобы оплатить
o ушел с поста вице-президента American Screw Co. в 1955 году сказал: «Оба р.
мы были избраны подавляющим большинством американского народа президентом Соединенных Штатов.
Пример: В прошлом месяце в Гане американский миссионер по прибытии обнаружил
## Соответствия регулярных выражений # для совпадения в мишенях: # print(match.strip())
«Городскому отделу закупок, - заявило жюри, - из-за городской кадровой политики не хватает опытных канцелярских кадров».
Список частот #
## частоты слов
[('the', 62713),
(',', 58334),
('.', 49346),
('из', 36080),
('и', 27915),
(«кому», 25732),
(«а», 21881),
(«в», 19536),
(«это», 10237),
('есть', 10011)]
## существительные частота
Сортировка кадра данных:
433 строки × 2 столбца
Мы также можем передать кадр данных в R для исследования данных.
-i Brown_fd_nouns_df библиотека (дплир) Brown_fd_nouns_df %>% фильтр(частота > 100) %>% организовать(деска(частота), слово) %>% голова
Р[записать в консоль]:
Прикрепляемый пакет: «dplyr»
R[записать в консоль]: Следующие объекты замаскированы из «package:stats»:
фильтр, задержка
R[запись в консоль]: Следующие объекты замаскированы из «package:base»:
пересечение, setdiff, setequal, объединение
частота слова
243 раз 1597
174 человека 1203
5114 из 995
248 лет 949
779 путь 899
486 человек 845
1011 г. 844
63 состояние 787
1099 мир 787
1227 мужчин 763
1438 жизнь 715
303 день 687
175 год 656
875 штатов 586
278 работа 583
299 дом 582
158 госпожа 534
865 часть 496
9 место 496
340 школа 489
32 номер 470
1801 курс 465
1173 война 463
101 факт 447
590 вода 444
1343 рука 423
896 правительство 418
229 система 416
121 ночь 411
1217 глава 407
1869 глаза 401
756 бизнес 393
12 город 393
72 программа 388
525 группа 386
371 день 384
819 номер 383
656 президент 382
1001 сторона 375
39 конец 369
1246 пункт 369
1254 шт. 368
212 Джон 362
1061 использовать 361
701 дело 360
354 заказать 359
459 детей 355
356 церковь 348
1108 мощность 340
595 развитие 333
Список условных частот #
## Частотное распределение слов по POS
FreqDist({'СУЩЕСТВИТЕЛЬНОЕ': 5, 'ГЛАГОЛ': 1})
## POS по частотному распределению слов
[('есть', 732),
(«был», 717),
(«быть», 526),
(«сказал», 402),
(«будет», 388),
(«есть», 328),
(«имеет», 300),
(«имел», 279),
(«иметь», 265),
(«были», 252)]
## Частотное распределение слов по жанрам
FreqDist({'belles_lettres': 6, "художественная литература": 4, "знания": 3, "религия": 3, "романтика": 3, "ученые": 2, "обзоры": 2, "приключения": 1 , 'юмор': 1, 'научная_фантастика': 1})
# с частотой
[('belles_lettres', 6), ('художественная литература', 4), ('предания', 3), ('религия', 3), ('романтика', 3), ('ученый', 2), ( 'обзоры', 2), ('приключения', 1), ('юмор', 1), ('научная_фантастика', 1)]
## Жанр по частотному распределению слов
## Жанр по частотному распределению слов
the of и to a в том, что это было для
приключение 3370 1322 1622 1309 1354 847 494 98 914 331
редакция 3508 1976 1302 1554 1095 1001 578 744 308 509
фантастика 3423 1419 1696 1489 1281 916 530 144 1082 392
[('время', 1555), ('человек', 1148), ('Аф', 994), ('леты', 942), ('путь', 883), ('господин', 844), («люди», 809), («мужчины», 736), («мир», 684), («жизнь», 676)]
время человек Af лет путь г-н люди мужчины мир жизнь
приключение 127 165 0 32 65 22 24 81 15 29
редакционная 72 56 0 63 43 110 75 38 66 35
фантастика 99 111 0 44 62 39 39 72 24 44
Чем словосочетания отличаются от обычных биграмм или триграмм?
Набор из двух слов, которые встречаются вместе как биграммы, и набор из трех слов, которые встречаются вместе как триграммы, могут не дать нам значимых фраз. Например, предложение «Он применил машинное обучение» содержит биграммы: «Он применил», «применил машину», «машинное обучение». «Он применил» и «применил машину» ничего не значат, а «машинное обучение» — это осмысленная биграмма. Просто рассматривать одновременно встречающиеся слова может быть не очень хорошей идеей, поскольку такие фразы, как «of the», могут часто встречаться вместе, но на самом деле не имеют смысла. Таким образом, потребность в словосочетаниях из библиотеки НЛТК
. Это дает нам только значимые биграммы и триграммы.
Питон3


