- Векторное представление (text embeddings)
- Word2Vec
- GloVe
- Перед тем, как углубиться в статьи
- Преимущества
- Примеры использования NLP
- Нейронные сети с памятью (Memory Networks)
- Введение
- Архитектура сети
- Недостатки
- Векторная магия
- Голосовые помощники
- Недостатки
- Примеры использования NLTK
- Преимущества
- Рекуррентная нейросетевая языковая модель (RNNLM)
- Готовые модели
- Сравнение LSTM и GRU
- Нейронный машинный перевод (Neural Machine Translation, NMT)
- Введение
- Архитектура сети
- Готовые модели
- Готовые модели
- GloVe (Global Vectors)
- Машинный перевод
- Что можно сказать о будущем NLP?
- Tree-LSTM для анализа эмоциональной окраски высказываний
- Введение
- Архитектура сети
- Преимущества
- Преимущества
- FastText
- Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
- Обзор исследований в области глубокого обучения
- Библиотеки для NLP
- Краткое изложение текста (Text Summarization)
- Вопросно-ответные (QA) системы
- Word2vec
Векторное представление (text embeddings)
В традиционном NLP слова рассматриваются как дискретные символы, которые далее представляются в виде one-hot векторов. Проблема со словами — дискретными символами — отсутствие определения cхожести для one-hot векторов. Поэтому альтернатива — обучиться кодировать схожесть в сами векторы.
Векторное представление
— метод представления строк, как векторов со значениями. Строится плотный вектор (dense vector) для каждого слова так, чтобы встречающиеся в схожих контекстах слова имели схожие вектора. Векторное представление считается стартовой точкой для большинства NLP задач и делает глубокое обучение эффективным на маленьких датасетах. Техники векторных представлений Word2vec
и GloVe
, созданных Google (Mikolov) Stanford (Pennington, Socher, Manning) соответственно, пользуются популярностью и часто используются для задач NLP. Давайте рассмотрим эти техники.
Word2Vec
Word2vec принимает большой корпус (corpus) текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t
в тексте, которая представляет собой центральное слово c
и контекстное слово o
. Далее используется схожесть векторов слов для c
и o
, чтобы рассчитать вероятность o при заданном с
(или наоборот), и продолжается регулировка вектор слов для максимизации этой вероятности.
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a,the,of,then
). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:

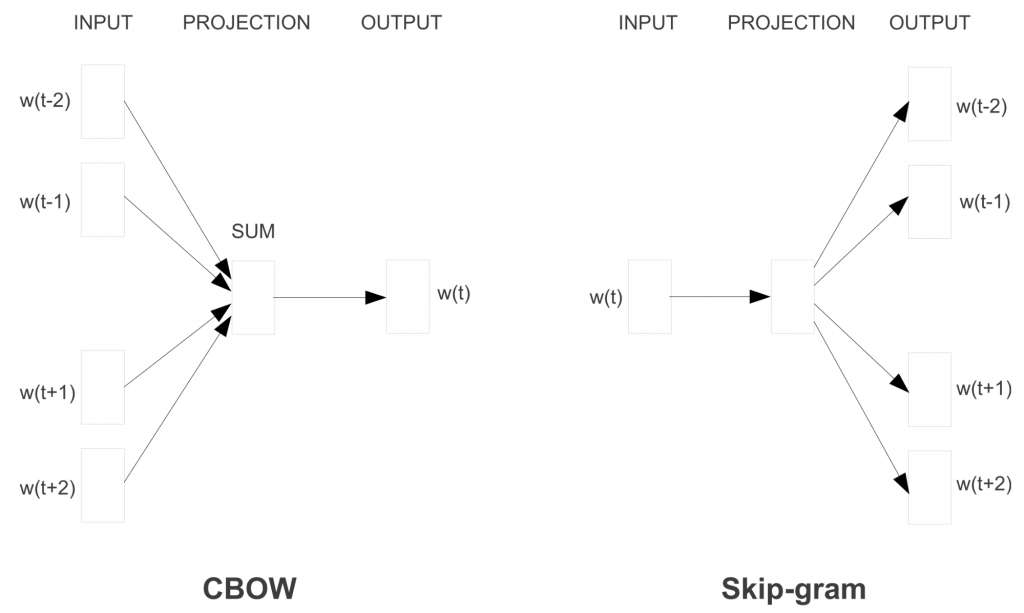
- Skip-Gram
: рассматривается контекстное окно, содержащее k
последовательных слов. Далее пропускается одно слово и обучается нейронная сеть
, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы. - Continuous Bag of Words
: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и ,наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
GloVe
GloVe
стремится решить эту проблему захватом значения одного word embedding со структурой всего обозримого корпуса. Чтобы сделать это, модель ищет глобальные совпадения числа слов и использует достаточно статистики, минимизирует среднеквадратичное отклонение, выдает пространство вектора слова с разумной субструктурой. Такая схема в достаточной степени позволяет отождествлять схожесть слова с векторным расстоянием.
Помимо этих двух моделей, нашли применение много недавно разработанных технологий: FastText
, Poincare Embeddings
, sense2vec
, Skip-Thought
, Adaptive Skip-Gram
.
Перед тем, как углубиться в статьи
Хотел бы сделать небольшое замечание. Если и другие модели глубокого обучения, полезные в NLP. На практике иногда используются рекурсивные и сверточные нейронные сети, хотя они не так распространены, как RNN, которые лежат в основе большинства NLP-систем глубокого обучения.
Теперь, когда мы начали хорошо разбираться в рекуррентных нейронных сетях применительно к NLP, давайте ознакомимся с некоторыми работами в этой области. Так как NLP включает в себя несколько различных областей задач (от машинного перевода до формирования ответов на вопросы), мы могли бы рассмотреть довольно много работ, но я выбрал те три, которые нашел особенно информативными. В 2016 году случился ряд серьезных продвижений в области NLP, но начнем с одной работы 2015 года.
Преимущества
- Простота. Модель быстро обучается и генерирует эмбеддинги, что достаточно для большинства простых приложений.
- Предварительно обученные версии доступны на многих языках.
Примеры использования NLP
Выражаясь простыми словами, NLP представляет собой группу техник автоматической обработки естественного человеческого языка в формате устной речи или текста. Не смотря на то, что эта концепция сама по себе уже невероятно интересна, реальная ценность этой технологии заключается в ее применении на практике.
NLP может помочь с целым рядом задач, и создается впечатление, что количество сфер его применения растет день ото дня. Вот несколько хороших примеров применения NLP на практике:
NLP позволяет распознавать и прогнозировать заболевания
на основе электронной медицинской документации и устной речи пациента. Сейчас проводятся многочисленные исследования, которые нацелены раскрыть потенциал этой технологии для разных состояний здоровья, которые варьируются от сердечно-сосудистых заболеваний до депрессии и даже шизофрении. Примером наработок в этой области может послужить Amazon Comprehend Medical — сервис, использующий NLP для извлечения данных о заболеваниях
, лекарствах и результатах лечения из историй болезни, отчетов о клинических испытаниях и другой электронной медицинской документации.С помощью NLP коммерческие организации могут определять, что говорят клиенты об их услуге или продукте, идентифицируя и извлекая информацию из таких источников, как социальные сети. Такой анализ тональности
постов может предоставить много полезной информации о выборе клиентов и факторах, влияющих на их решения.Изобретатель из IBM разработал
когнитивного помощника
, работающего как персонализированная поисковая система, которая изучает все о вас, а затем напоминает вам имя, песню или что-либо еще, что вы не можете вспомнить, в тот момент, когда вам это нужно.Такие компании, как Yahoo и Google, фильтруют и классифицируют ваши электронные письма с помощью NLP. Они анализируют текст в электронных письмах, которые проходят через их серверы, благодаря чему они могут отфильтровывать спам
до того, как он попадет в ваш почтовый ящик.Чтобы помочь в выявлении фейковых новостей
, комманада NLP в Массачусетском Технологическом Институте
разработала новую систему для оценки того, является ли источник достоверным или политически предвзятым, помогая определить, можно ли доверять конкретному источнику новостей.Alexa от Amazon и Siri от Apple являются яркими примерами интеллектуальных голосовых интерфейсов
. Они используют NLP, чтобы реагировать на голосовые команды и выполнять на их основе целый ряд задач, например, находить конкретный магазин, сообщать нам прогноз погоды, предлагать лучший маршрут до офиса или включать свет дома.Понимание того, что происходит в мире и что сейчас обсуждают люди, может быть очень ценным для финансовых трейдеров
. N LP используется для отслеживания новостей, отчетов, комментариев о возможных слияниях между компаниями — все это затем может быть скормлено алгоритму для биржевой торговли с целью максимизации прибыли. Как говорится: покупайте слухи, продавайте новости.NLP также используется на этапах поиска и отбора перспективных кадров
, определения навыков потенциальных сотрудников, а также выявления потенциальных клиентов до того, как они проявят активность на рынке труда.Компания LegalMation
разработала платформу для автоматизации рутинных судебных задач
на основе технологии NLP IBM Watson, которая помогает юридическим отделам экономить время, сокращать расходы и сдвигать с этого свой стратегический фокус.
NLP особенно процветает в сфере здравоохранения
. Эта технология помогает улучшить оказание медицинской помощи, диагностику заболеваний и снижает затраты. Особенно этому способствует то, что организации здравоохранения массово переходят на электронные способы учета медицинских документов. Тот факт, что клиническая документация может быть улучшена, означает и то, что пациенты могут быть лучше поняты и получат более качественное медицинское обслуживание. Одной из главных целей является оптимизация их опыта, и несколько серьезных организаций уже работают над этим.

Такие компании, как Winterlight Labs
, значительно продвигают лечении болезни Альцгеймера, отслеживая когнитивные нарушения через устную речь, а также поддерживают клинические испытания и исследования для широкого спектра других заболеваний центральной нервной системы. Следуя аналогичному подходу, Стэнфордский университет разработал Woebot
— бота-терапевта
, предназначенного для помощи людям с тревогой и другими расстройствами.
Тем не менее, вокруг этой темы идут все еще идут серьезные споры
. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могли идентифицировать интернет-пользователей, страдающих раком поджелудочной железы
, еще до того, как им был поставлен диагноз этого заболевания. Но как пользователи отреагируют на такой диагноз? И что произойдет, если ваш тест окажется ложноположительным? (то есть, что у вас может быть диагностировано заболевание, а в реальности у вас его нет). Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен как способный предсказывать вспышки гриппа, но позже исчез из-за его низкой точности и несоответствия прогнозируемым показателям.
NLP может стать ключом к эффективной клинической поддержке в будущем, но перед тем, как это станет реальностью, предстоит решить еще не одну проблему.
Нейронные сети с памятью (Memory Networks)
Введение
Первая работа, которую мы обсудим, оказала большое влияние на развитие области формирования ответов на вопросы. В этой публикации авторства Джейсона Вестона (Jason Weston), Сумита Чопры (Sumit Chopra) и Антуана Бордеса (Antoine Bordes) был впервые описан класс моделей под названием ”сети с памятью”.
Интуитивно-понятная идея состоит в следующем: для того, чтобы точно ответить на вопрос, относящийся к фрагменту текста, необходимо каким-то образом хранить предоставленную нам исходную информацию. Если бы я спросил вас: “Что означает аббревиатура RNN?”, вы смогли бы ответить мне, потому что информация, которую вы усвоили, читая первую часть статьи, сохранилась где-то в вашей памяти. Вам понадобилось бы лишь несколько секунд, чтобы найти эту информацию и озвучить ее. Я понятия не имею, как это получается у мозга, но мысль о том, что необходимо пространство для хранения этой информации, остается неизменной.
Сеть с памятью, описанная в данной работе, уникальна, так как у нее есть ассоциативная память, в которую она может писать и из которой она может читать. Интересно заметить, что подобную память не используют ни CNN, ни Q-Network (для обучения с подкреплением (reinforcement learning), ни традиционные нейронные сети. Это отчасти связано с тем, что задача формирования ответов на вопросы в большой степени полагается на способность моделировать или прослеживать отдаленные зависимости, например, следить за героями истории или запоминать последовательность событий. В CNN или Q-Networks память как бы встроена в веса системы, так как она обучается различным фильтрам или картам соответствий состояний и действий. На первый взгляд, можно было бы использовать RNN или LSTM, но обычно они не способны запоминать входные данные из прошлого (что является критичным для задач формирования ответов на вопросы).
Архитектура сети
Теперь посмотрим, как такая сеть обрабатывает исходный текст. Как и большинство алгоритмов машинного обучения, первый шаг – преобразовать входные данные в представление в пространстве признаков. Под этим может подразумеваться использование векторных представлений слов, морфологическая разметка, синтаксический разбор и т.д., на усмотрение программиста.

Следующий шаг – взять представление в пространстве признаков I(x) и считать в память новую порцию входных данных x.
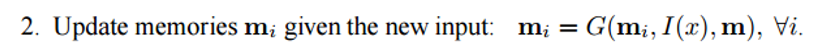
Память m можно рассматривать как подобие массива, составленного из отдельных блоков памяти 
. Каждый такой блок
может быть функцией от всей памяти m, представления в пространстве признаков I(x) и/или самого себя. Функция G может просто хранить все представление I(x) в блоке памяти mi. Функцию G можно изменить так, чтобы она обновляла память о прошлом на основе новых входных данных. Третий и четвертый шаги включают в себя чтение из памяти с учетом вопроса, чтобы найти представление признаков o, и его декодирование, чтобы получить окончательный ответ r.

В качестве функции R может служить RNN, преобразующая представления признаков в человекочитаемые и точные ответы на вопросы.
Теперь давайте присмотримся к шагу 3. Мы хотим, чтобы функция O возвращала представление в пространстве признаков, наилучшим образом соответствующее возможному ответу на заданный вопрос x. Мы сравним этот вопрос с каждым отдельным блоком памяти и оценим, насколько каждый блок подходит под ответ на вопрос.
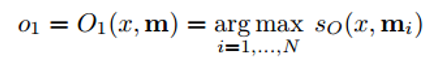
Мы находим аргумент максимизации (argmax) оценочной функции, чтобы найти представление, наиболее соответствующее вопросу (можно также выбрать несколько блоков с самыми высокими оценками, не обязательно ровно один). Оценочная функция вычисляет матричное произведение между различными векторными представлениями вопроса и выбранным блоком (или блоками) памяти (подробности вы найдете в самой работе). Можете представить этот процесс как перемножение двух векторов из двух слов, чтобы определить, равны ли они. Выходное представление о затем передается RNN, LSTM или другой оценочной функции, которая вернет человекочитаемый ответ.
Обучение сети проходит методом обучения с учителем, когда обучающие данные включают в себя исходный текст, вопрос, подтверждающие предложения и правильный ответ. Вот, как выглядит целевая функция:
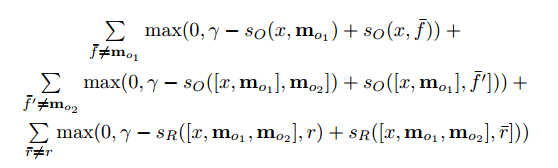
Для тех, кто заинтересовался, привожу еще несколько работ, основанных на подходе сетей с памятью:
- End to End Memory Networks
- Dynamic Memory Networks
- Dynamic Coattention Networks
(реализованы в ноябре 2016 и получили лучший за все времена результат на наборе данных Stanford’s Question Answering)
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Игнорируется совместная встречаемость, то есть модель не учитывает различное значение слова в разных контекстах (поэтому GloVe может быть предпочтительнее).
Все четыре модели имеют много общего, но каждая из них должна использоваться в подходящем контексте. К сожалению, этот момент часто игнорируется, что приводит к получению неоптимальных результатов.
Если вам интересна тема обработки естественного языка, у нас есть ещё пара материалов:
- Обработка естественного языка: с чего начать и что изучать дальше
- NLP – это весело! Обработка естественного языка на Python
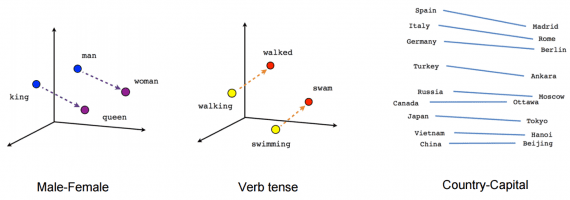
Векторная магия
Модель Word2vec поразила исследователей своей «интерпретируемостью». Обучение на больших корпусах текстов
позволяет определять глубокие отношения между формами слов, например, гендерные. Если из вектора, соответствующего слову Мужчина (Man) вычесть вектор Женщина (Woman), результат будет очень похож на разность векторов Король (King) и Королева (Queen).
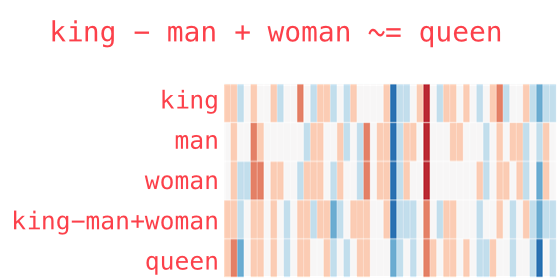
Одно время такое отношения между словами и их векторами казалось почти магией. Ещё несколько забавных примеров векторной арифметики вы можете найти в статье Во что превращается жизнь без любви
. Несмотря на огромный вклад, который модель внесла в NLP, сейчас она почти не используется – на смену пришли достойные наследники.
Голосовые помощники
Разработанная в Гонконге нейронная машина для ответов
(далее NRM — Neural Responding Machine) — генератор ответов для коротких текстовых бесед. N RM использует общий кодер-декодер фреймворк. Сначала формализуется создание ответа, как процесс расшифровки на основе скрытого представления входного текста, пока кодирование и декодирование реализуется с помощью рекуррентных нейросетей. N RM обучен на больших данных с односложными диалогами, собранными из микро-блогов. Эмпирическим путем установлено, что NRM способен генерировать правильные грамматические и уместные в данном контексте ответы на 75%
поданных на вход текстов, опережая в результативности современные модели с теми же настройками.
Последняя модель — Google’s Neural Conversational Model
предлагает простой подход к моделированию диалогов, используя sequence-to-sequence фреймворк. Модель поддерживает беседу благодаря предсказанию следующего предложения, используя предыдущие предложения из диалога. Сильная сторона этой модели — способность к сквозному обучению, из-за чего требуется намного меньше рукотворных правил.
Модель способна создавать простые диалоги на основе обширного диалогового тренировочного сета, способна извлекать знания из узкоспециализированных датасетов, а также больших и зашумленных общих датасетов субтитров к фильмам. В узкоспециализированной области справочной службы для ИТ-решений модель находит решения технической проблемы с помощью диалога. На зашумленных датасетах транскриптов фильмов модель способна делать простые рассуждения на основе здравого смысла.
Недостатки
- Хотя матрица совместной встречаемости предоставляет глобальную информацию, GloVe остаётся обученной на уровне слов и даёт немного данных о предложении и контексте, в котором слово используется.
- Плохо обрабатывает неизвестные и редкие слова.
Примеры использования NLTK
- Разбиение на предложения:
text = "Предложение. Предложение, которое содержит запятую. Восклицательный знак! Вопрос?"
sents = nltk.sent_tokenize(text)
print(sents)
output:
['Предложение.', 'Предложение, которое содержит запятую.', 'Восклицательный знак!', 'Вопрос?']
- Токенизация:
from nltk.tokenize import RegexpTokenizer
sent = "В этом предложении есть много слов, мы их разделим."
tokenizer = RegexpTokenizer(r'\w+')
print(tokenizer.tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', 'мы', 'их', 'разделим']
from nltk import word_tokenize
sent = "В этом предложении есть много слов, мы их разделим."
print(word_tokenize(sent))
output:
['В', 'этом', 'предложении', 'есть', 'много', 'слов', ',', 'мы', 'их', 'разделим', '.']
- Стоп слова:
from nltk.corpus import stopwords
stop_words=set(stopwords.words('english'))
print(stop_words)
output:
{'should', 'wouldn', 'do', 'over', 'her', 'what', 'aren', 'once', 'same', 'this', 'needn', 'other', 'been', 'with', 'all' .
- Стемминг и лемматизация:
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem("crying"))
output:
cri
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem("crying"))
output:
cry
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer("english")
print(snowball_stemmer.stem("crying"))
output:
cri
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize("came", pos="v"))
output:
come
Преимущества
- Относительно простая архитектура: feed-forward, 1 вход, 1 скрытый слой, один выход (хотя n-граммы добавляют сложность в генерацию эмбеддингов).
- Благодаря n-граммам неплохо работает на редких и устаревших словах.
Рекуррентная нейросетевая языковая модель (RNNLM)
Возникшая в 2001 г. идея привела к рождению одной из первых embedding-моделей.
В языковом моделировании отдельные слова и группы слов сопоставляются векторам – некоторым численным представлениям с сохранением семантической связи. Сжатое векторное представление слова называют эмбеддингом.
Модель принимает на вход векторные представления n
предыдущих слов и может «понимать» семантику предложения. Обучение модели базируется на алгоритме непрерывного мешка слов
. Контекстные (соседние) слова подаются на вход нейронной сети, которая предсказывает центральное слово.
Мешок слов – это модель представления текста в виде вектора (набора слов). Каждому слову в тексте сопоставляется число его вхождений.
Сжатые векторы объединяются, передаются в скрытый слой, где срабатывает softmax функция активации
, определяющая, какие сигналы пройдут дальше (если эта тема вызывает трудности, прочитайте наше Наглядное введение в нейросети
).
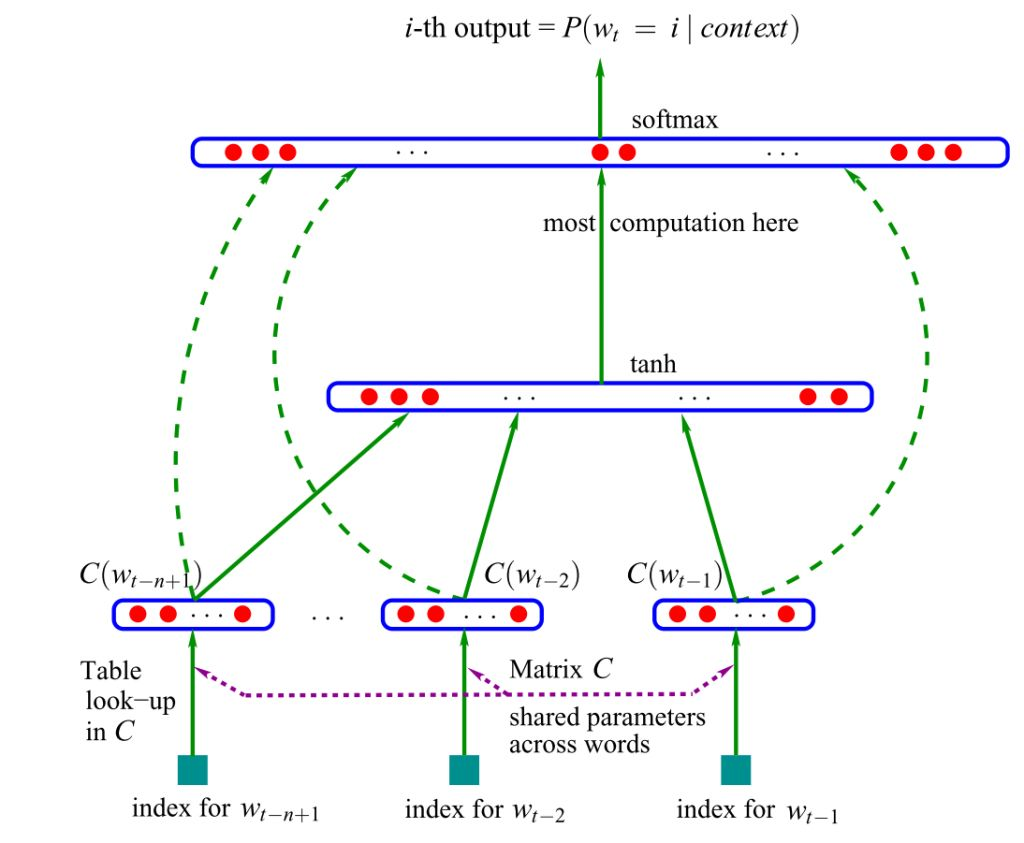
Оригинальная версия основывалась на нейросетях прямого распространения
– сигнал шёл строго от входного слоя к выходному. Позднее была предложена альтернатива в виде рекуррентных нейронных сетей
(RNN) – именно на «ванильной» RNN, а не на управляемых рекуррентных блоках
(GRUs) или на долгой краткосрочной памяти
(LSTM).
Рекуррентные нейронные сети (RNN)
Нейронные сети с направленными связями между элементами. Выход нейрона может снова подаваться на вход. Такая структура позволяет иметь подобие «памяти» и обрабатывать последовательности данных, например, тексты естественного языка.
Готовые модели
У Google есть предварительно обученные open-source модели для большинства языков ( английская версия
). Модель использует три скрытых слоя нейронной сети прямого распространения, обучена на корпусе English Google News 200B и генерирует 128-мерный эмбеддинг.
Сравнение LSTM и GRU
Сначала рассмотрим общие черты. Оба эти метода разработаны для того, чтобы сохранять отдаленные зависимости в последовательностях слов. Под отдаленными зависимостями имеются в виду такие ситуации, когда два слова или фразы могут встретиться на разных временных шагах, но отношения между ними важны для достижения конечной цели. L STM и GRU отслеживают эти отношения с помощью фильтров, которые могут сохранять или сбрасывать информацию из обрабатываемой последовательности.
Различие между двумя методами состоит в количестве фильтров (GRU – 2, LSTM – 3). Это влияет на количество нелинейностей, которое приходит от входных данных и в конечном итоге влияет на процесс вычислений. Кроме того, в GRU отсутствует ячейка памяти 
, как в LSTM.
Нейронный машинный перевод (Neural Machine Translation, NMT)
Введение
Последняя работа, которую мы сегодня рассмотрим, описывает подход к решению задачи машинного перевода. Авторы этой работы – специалисты Google по машинному обучению Джефф Дин (Jeff Dean), Грег Коррадо (Greg Corrado), Ориал Виньялс (Orial Vinyals) и другие – представляют систему машинного обучения, которая лежит в основе широко известного сервиса Google Translate. С введением этой системы количество ошибок перевода сократилось в среднем на 60% по сравнению с прежней системой, используемой Google.
Традиционные подходы к автоматическому переводу включают в себя нахождение пофразовых соответствий. Этот подход требовал хорошего знания лингвистики и в конце концов оказался недостаточно стабильным и неспособным к генерализации. Одна из проблем традиционного подхода состояла в том, что исходное предложение переводилось по кусочкам. Оказалось, что переводить все предложение за раз (как это делает NMT) более эффективно, так как в этом случае вовлекается более широкий контекст и порядок слов становится более естественным.
Архитектура сети
Авторы этой статьи описывают глубокую сеть LSTM, которая может быть от обучена с помощью восьми слоем энкодеров и декодеров. Мы можем разделить систему на три компонента: энкодер RNN, декодер RNN и модуль “внимания” (attention module). Энкодер работает над задачей преобразования входного предложения в векторное представление, декодер возвращает выходное представление, затем модуль внимания сообщает декодеру, на чем следует заострить внимание во время операции декодирования (здесь вступает идея использования всего контекста предложения).

Далее статья уделяет внимание проблемам, связанным с развертыванием и масштабированием данного сервиса. В ней обсуждаются такие темы, как вычислительные ресурсы, время задержки и массовое развертывание сервиса.
Готовые модели
Эмбеддинги GloVe легко доступны на веб-сайте Стэнфордского университета
.
Готовые модели
В сети доступна подготовленная модель для 157 языков
(в том числе русского).
GloVe (Global Vectors)
GloVe
тесно ассоциируется с Word2Vec: алгоритмы появились примерно в одно и то же время и опираются на интерпретируемость векторов слов. Модель GloVe пытается решить проблему эффективного использования статистики совпадений. GloVe минимизирует разницу между произведением векторов слов и логарифмом вероятности их совместного появления с помощью стохастического градиентного спуска
. Полученные представления отражают важные линейные подструктуры векторного пространства слов: получается связать вместе разные спутники одной планеты или почтовый код города с его названием.
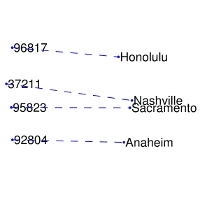
В Word2Vec частота совместной встречаемости слов не имеет большого значения, она лишь помогает генерировать дополнительные обучающие выборки. GloVe учитывает совместную встречаемость, а не полагается только на контекстную статистику. Векторы слов группируются вместе на основе их глобальной схожести.
Машинный перевод
Машинный перевод
(Machine translation) — преобразование текста на одном естественном языке в эквивалентный по содержанию текст на другом языке. Делает это программа или машина без участия человека. В машинном переводе использутся статистика использования слов по соседству. Системы машинного перевода находят широкое коммерческое применение, так как переводы с языков мира — индустрия с объемом $40 миллиардов в год
. Некоторые известные примеры:
- Google Translate переводит 100 миллиардов слов в день.
- eBay
использует технологии машинного перевода, чтобы сделать возможным трансграничную торговлю и соединить покупателей и продавцов из разных стран. - Microsoft
применяют перевод на основе искусственного интеллекта к конечным пользователям и разработчикам на Android, iOS и Amazon Fire независимо от доступа в Интернет. - Systran
стал первым поставщиком софта для запуска механизма нейронного машинного перевода на 30 языков в 2016 году.
Излишне говорить, что этот подход пропускает сотни важных деталей, требует большого количества спроектированных вручную признаков, состоит из различных и независимых задач машинного обучения.
Нейросетевой машинный перевод
(Neural Machine Translation) — подход к моделированию перевода с помощью рекуррентной нейронной сети
(Recurrent Neural Network, RNN). R NN — нейросеть c зависимостью от предыдущих состояний, в которая имеет связи между проходами. Нейроны получают информацию из предыдущих слоев, а также из самих себя на предыдущем шаге. Это означает, что порядок, в котором подается на вход данные и тренируется сеть, важен: результат подачи “Дональд” — “Трамп” не совпадает с результатом подачи “Трамп” — “Дональд”.
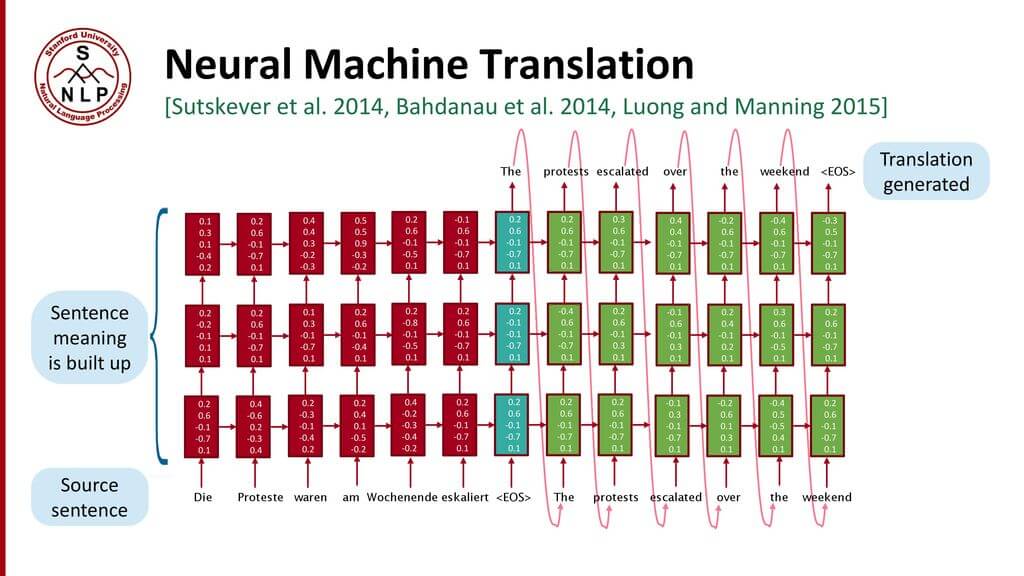
Стандартная модель нейро-машинного перевода является сквозной нейросетью, где исходное предложение кодируется RNN, называемой кодировщик
(encoder), а целевое слово предсказывается с помощью другой RNN, называемой декодер
(decoder). Кодировщик «читает» исходное предложение со скоростью один символ в единицу времени, далее объединяет исходное предложение в последнем скрытом слое. Декодер использует обратное распространение
ошибки для изучение этого объединения и возвращает переведённую вариант. Удивительно, что находившийся на периферии исследовательской активности в 2014 году нейро-машинный перевод стал стандартом машинного перевода в 2016 году. Ниже представлены достижения перевода на основе нейронной сети:
- Сквозное обучение
: параметры в NMT (Neural Machine Translation) одновременно оптимизируются для минимизации функции потерь на выходе нейросети. - Распределенные представления
: NMT лучше использует схожести в словах и фразах. - Лучшее исследование контекста
: NMT работает больше контекста — исходный и частично целевой текст, чтобы переводить точнее. - Более беглое генерирование текста
: перевод текста на основе глубокого обучения намного превосходит по качеству метод параллельного корпуса.
Главная проблема RNN — проблема исчезновения градиента, когда информация теряется с течением времени. Интуитивно кажется, что это не является серьезной проблемой, так как это только веса, а не состояния нейронов. Но с течением времени веса становятся местами, где хранится информация из прошлого. Если вес примет значение 0 или 100000, предыдущее состояние не будет слишком информативно. Как следствие, RNN будут испытывать сложности в запоминании слов, стоящих дальше в последовательности, а предсказания будут делаться на основе крайних слов, что создает проблемы.
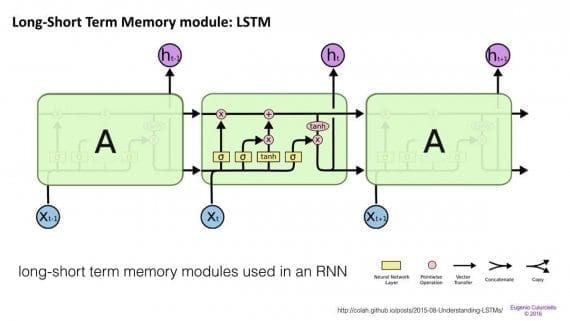
Сети краткосрочной-долгосрочной памяти
(Long/short term memory, далее LSTM) пытаются бороться с проблемой градиента исчезновения вводя гейты (gates) и вводя ячейку памяти. Каждый нейрон представляет из себя ячейку памяти с тремя гейтами: на вход, на выход и забывания (forget). Эти затворы выполняют функцию телохранителей для информации, разрешая или запрещая её поток.
- Входной гейт определяет, какое количество информации из предыдущего слоя будет храниться в этой ячейке;
- Выходной гейт выполняет работу на другом конце и определяет, какая часть следующего слоя узнает о состоянии текущей ячейки.
- Гейт забывания контролирует меру сохранения значения в памяти: если при изучении книги начинается новая глава, иногда для нейросети становится необходимым забыть некоторые слова из предыдущей главы.
Было показано, что LSTM способны обучаться на сложных последовательностях и, например, писать в стиле Шекспира или сочинять примитивную музыку. Заметим, что каждый из гейтов соединен с ячейкой на предыдущем нейроне с определенным весом, что требуют больше ресурсов для работы. L STM распространены и используются в машинном переводе. Помимо этого, это стандартная модель для большинства задач маркировки (labeling) последовательности, которые состоят из большого количества данных.
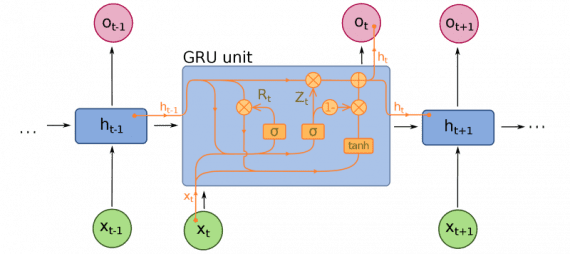
Закрытые рекуррентные блоки
(Gated recurrent units, далее GRU) отличаются от LSTM, хотя тоже являются расширением для нейросетевого машинного обучения. В GRU на один гейт меньше, и работа строится по-другому: вместо входного, выходного и забывания, есть гейт обновления
(update gate). Он определяе
т, сколько информации необходимо сохранить c последнего состояния и сколько информации пропускать с предыдущих слоев.
Функции сброса гейта (reset gate) похожи на затвор забывания у LSTM, но расположение отличается. G RU всегда передают свое полное состояние, не имеют выходной затвор. Часто эти затвор функционирует как и LSTM, однако, большим отличием заключается в следующем: в GRU затвор работают быстрее и легче в управлении (но также менее интерпретируемые). На практике они стремятся нейтрализовать друг друга, так как нужна большая нейросеть для восстановления выразительности (expressiveness), которая сводит на нет приросты в результате. Но в случаях, где не требуется экстра выразительности, GRU показывают лучше результат, чем LSTM.
Помимо этих трех главных архитектур, за последние несколько лет появилось много улучшений в нейросетевом машинном переводе. Ниже представлены некоторые примечательные разработки:
Что можно сказать о будущем NLP?
В настоящий момент NLP покоряет обнаружение нюансов в смысловых значениях языка, будь то отсутствие контекста, орфографические ошибки или диалектные различия.
В марте 2016 года Microsoft запустила Tay
, чат-бота на основе искусственного интеллекта, в качестве эксперимента выпущенного на просторы Твиттера. Идея заключалась в том, что чем больше пользователей будет общаться с Tay’ем, тем умнее он будет становиться. Что ж, в результате через 16 часов Tay’а пришлось удалить из-за его расистских и оскорбительных комментариев:


Microsoft извлекла ценные уроки из собственного опыта и через несколько месяцев выпустила Zo
, своего англоязычного чат-бота второго поколения, который должен был избежать ошибок предшественника. Zo использует комбинацию инновационных подходов для распознавания и генерации беседы. Другие компании занимаются разработкой ботов, которые могут запоминать детали, характерные для конкретного отдельного разговора.
Хотя будущее NLP выглядит чрезвычайно сложным и полным вызовов, эта дисциплина развивается очень быстрыми темпами (вероятно, как никогда раньше), и мы, вероятно, достигнем в ближайшие годы такого уровня развития, при котором еще более сложные приложения будут казаться вполне себе обычным делом.
В заключение приглашаю всех на
бесплатный урок
курса NLP от OTUS по теме:
«Парсинг данных: собираем датасет своими руками»
.
Tree-LSTM для анализа эмоциональной окраски высказываний
Введение
Следующая работа рассказывает о прогрессе в области анализа эмоциональной окраски – задачи определения, имеет высказывание положительную или отрицательную коннотацию (значение). Формально эмоциональную окраску можно определить как “взгляд на ситуацию или событие или отношение к ним”. На тот момент наиболее распространенным инструментом для задач распознавания эмоциональной окраски были LSTM. Работа авторства Кай Шенг Тай (Kai Sheng Tai), Ричарда Сочера (Richard Socher) и Кристофера Маннинга (Christopher Manning) вводит принципиально новый способ объединения нескольких LSTM-нейронов в нелинейную структуру.
Идея нелинейного расположения компонентов основана на мнении, что естественные языки демонстрируют свойство превращать последовательности слов в фразы. Эти фразы, в зависимости от порядка слов, могут иметь значение, отличное от исходного значения входящих в них компонентов. Чтобы отразить это свойство, сеть из нескольких LSTM-нейронов следует представить в виде дерева, где на каждый нейрон влияют его дочерние узлы.
Архитектура сети
Одно из отличий Tree-LSTM от обычного LSTM состоит в том, что во последнем скрытое состояние – функция от текущих входных данных и и скрытого состояния на предыдущем шаге. В Tree-LSTM скрытое состояние – функция от текущих входных данных и скрытых состояний его дочерних нейронов.
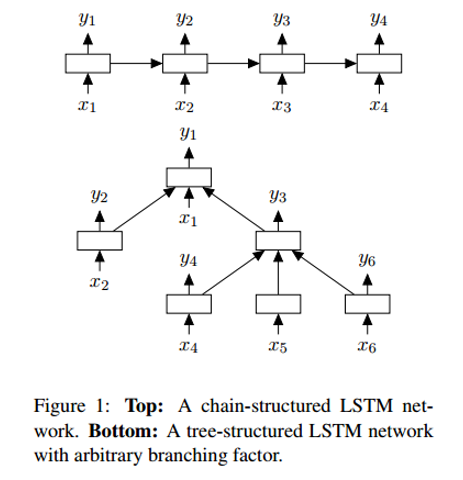
Вместе с новой структурой – деревом – вводятся также некоторые изменения в математике сети, например, у дочерних нейронов теперь есть фильтры забывания. С подробностями можно познакомится в самой работе. А я хотел бы уделить внимание объяснению, почему такие сети работают лучше линейных LSTM.
В Tree-LSTM каждый нейрон может вмещать в себя скрытые состояния всех его дочерних узлов. Это интересный момент, так как нейрон может оценивать каждый свой дочерний узел по-разному. Во время обучения сеть может осознать, что определенное слово (например, слово “не” или “очень”) чрезвычайно важно для определения эмоциональной окраски всего предложения. Возможность выше оценить соответствующий узел обеспечивает большую гибкость сети и может улучшить ее производительность.
Преимущества
- Простая архитектура без нейронной сети.
- Модель быстрая, и этого может быть достаточно для простых приложений.
- GloVe улучшает Word2Vec. Она добавляет частоту встречаемости слов и опережает Word2Vec на большинстве бенчмарков.
- Осмысленные эмбеддинги.
Преимущества
- Простая архитектура: feed-forward, 1 вход, 1 скрытый слой, 1 выход.
- Модель быстро обучается и генерирует эмбеддинги (даже ваши собственные).
- Эмбеддинги наделены смыслом, спорные моменты поддаются расшифровке.
- Методология может быть распространена на множество других областей/проблем (например, Lda2vec
).
FastText
К основной модели Word2Vec добавлена модель символьных n-грамм. Каждое слово представляется композицией нескольких последовательностей символов определённой длины. Например, слово they
в зависимости от гиперпараметров может состоять из «th», «he», «ey», «the», «hey». По сути, вектор слова – это сумма всех его n-грамм.
Результаты работы классификатора хорошо подходят для слов с небольшой частотой встречаемости, так как они разделяются на n-граммы. В отличие от Word2Vec и Glove, модель способна генерировать эмбеддинги для неизвестных слов.
Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
Теперь посмотрим, как с нашими векторами будет работать рекуррентная нейронная сеть. R NN – палочка-выручалочка для большинства современных задач обработки естественного языка. Главное преимущество RNN в том, что они могут эффективно использовать данные с предыдущих шагов. Вот так выглядит маленький кусочек RNN:
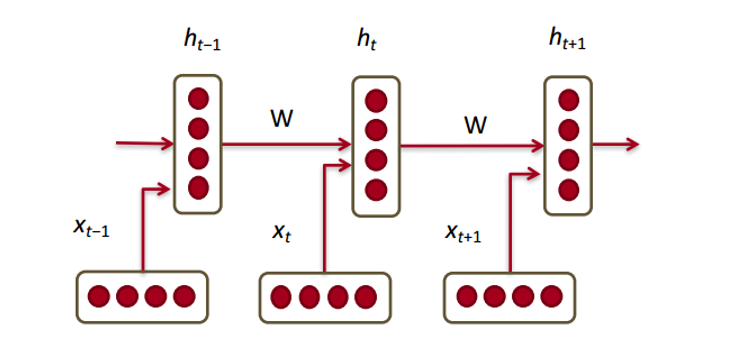
Внизу изображены векторы слов ( 
). У каждого вектора на каждом шаге есть скрытый вектор состояния (hidden state vector) ( 
). Будем называть эту пару модулем (module).
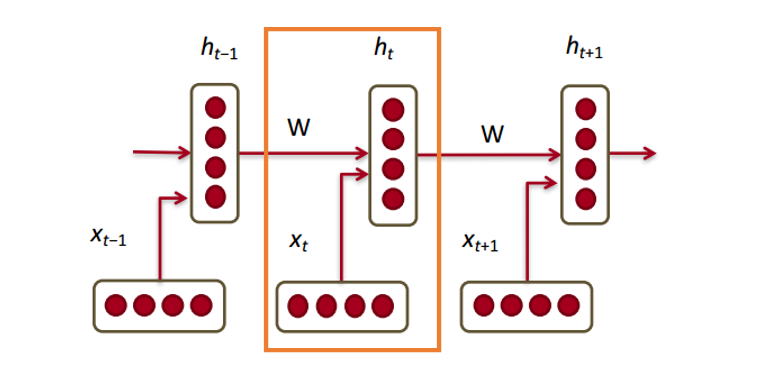
Скрытое состояние в каждом модуле RNN – это функция
от вектора слова и вектора скрытого состояния с прошлого шага.

Если мы приглядимся к верхним индексам, то увидим, что здесь есть матрица весов 
, которую мы умножаем на входное значение, и есть рекуррентная матрица весов 
, которая умножается на вектор скрытого состояния с предыдущего шага. Имейте в виду, что эти рекуррентные матрицы весов на каждом шаге одинаковы. Это ключевой момент RNN
. Если тщательно обдумать, то этот подход значительно отличается от, скажем, традиционных двухслойных нейронных сетей. В этом случае у нас обычно выбирается отдельная матрица W для каждого слоя: 
и 
. Здесь же рекуррентная матрица весов одна и та же для всей сети.
Для получения выходных значений каждого модуля (Yhat) служит еще одна матрица весов – 
, умноженная на h.
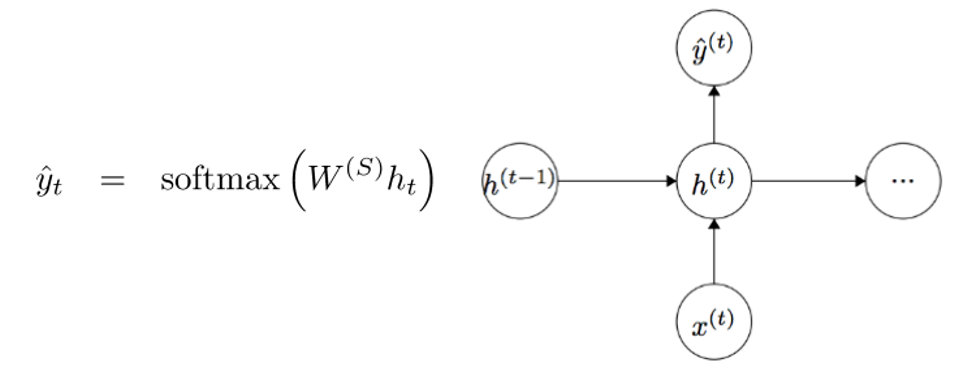
Теперь давайте посмотрим со стороны и поймем, в чем состоят преимущества RNN. Наиболее явное отличие RNN от традиционной нейронной сети в том, что RNN принимает на вход последовательность
входных данных (в нашем случае слов). Этим они отличаются, например, от типичных CNN, на вход которым подается целое изображение. Для RNN же входными данными может служить как короткое предложение, так и сочинение из пяти абзацев. Кроме того, порядок
, в котором подаются данные, может влиять на то, как в процессе обучения меняются матрицы весов и векторы скрытых состояний. К концу обучения в векторах скрытых состояний должна накопиться информация из прошлых шагов.
Обзор исследований в области глубокого обучения
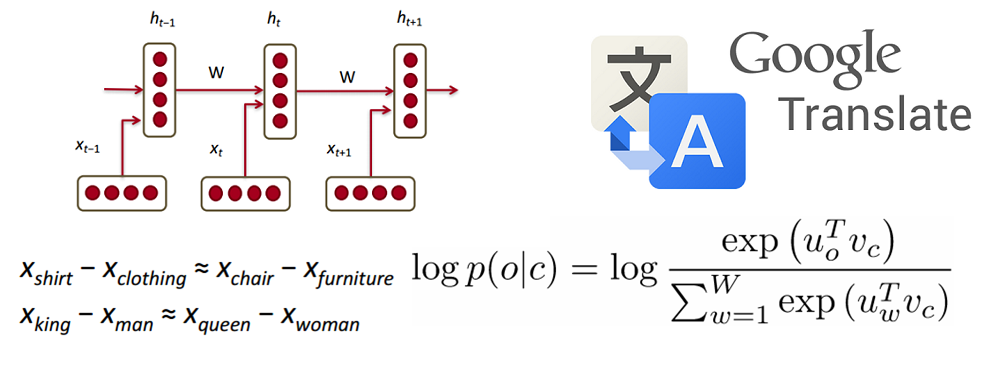
Это третья статья из серии “Обзор исследований в области глубокого обучения” (Deep Learning Research Review) студента Калифорнийского университета в Лос-Анджелесе Адита Дешпанда (Adit Deshpande). Каждые две недели Адит публикует обзор и толкование исследований в определенной области глубинного обучения. В этот раз он сосредоточил свое внимание на применении глубокого обучения для обработки текстов на естественном языке.
Библиотеки для NLP
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
- Наиболее известная и многофункциональная библиотека для NLP;
- Большое количество сторонних расширений;
- Быстрая токенизация предложений;
- Поддерживается множество языков.
- Медленная;
- Сложная в изучении и использовании;
- Работает со строками;
- Не использует нейронные сети;
- Нет встроенных векторов слов.
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
- Самая быстрая библиотека для NLP;
- Простая в изучении и использовании;
- Работает с объектами, а не строками;
- Есть встроенные вектора слов;
- Использует нейронные сети для тренировки моделей.
- Менее гибкая по сравнению с NLTK;
- Токенизация предложений медленнее, чем в NLTK;
- Поддерживает маленькое количество языков.
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
- Большое количество алгоритмов для построения моделей;
- Содержит функции для работы с Bag-of-Words моделью;
- Хорошая документация.
- Плохой препроцессинг, что вынуждает использовать ее в связке с другой библиотекой (например, NLTK);
- Не использует нейронные сети для препроцессинга текста.
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
- Работает с большими датасетами;
- Поддерживает глубокое обучение;
- word2vec, tf-idf vectorization, document2vec.
- Заточена под модели без учителя;
- Не содержит достаточного функционала, необходимого для NLP, что вынуждает использовать ее вместе с другими библиотеками.
Краткое изложение текста (Text Summarization)
Человеку сложно вручную выделить краткое содержание в большом объеме текста. Поэтому в NLP возникает проблема создания точного и лаконичного резюме для исходного документа. Извлечение краткого содержания (Text Summarization)
— важный инструмент для помощи в интерпретации текстовой информации. Push-уведомления и дайджесты статей привлекают большое внимание, а количество задач по созданию разумных и точных резюме для больших фрагментов текста растет день ото дня.
Автоматическое извлечение краткого содержания из текста работает следующим образом. Сначала считается частота появления слова во полном текстовом документе, затем 100 наиболее частых слов сохраняются и сортируются. После этого каждое предложение оценивается по количеству часто употребимых слов, причем вес больше у более часто встречающегося слова. Наконец, первые Х предложений сортируются с учетом положения в оригинальном тексте.
С сохранением простоты и обобщающей способности алгоритм автоматического извлечения краткого содержания способен работать в сложных ситуациях. Например, многие реализации терпят неудачи на текстах с иностранными языками или уникальными словарными ассоциациями, которые не содержатся в стандартных массивах текстов.
Выделяют два фундаментальных подхода к сокращению текста: извлекательный
и абстрактный
. Первый извлекает слова и фразы из оригинального текста для создания резюме. Последний изучает внутреннее языковое представление, чтобы создать человекоподобное изложение, перефразируя оригинальный текст.
Методы в извлекательном сокращении работают на основе выбора подмножества. Это достигается за счет извлечения фраз или предложений из статьи для формирования резюме. LexRank
и TextRank
— хорошо известные представители этого подхода, которые используют вариации алгоритм сортировки страниц Google PageRank.
LexRank — алгоритм обучения без учителя на основе графов, который использует модифицированный косинус обратной частоты встречи слова, как мера похожести двух предложений. Похожесть используется как вес грани графа между двумя предложениями. LexRank также внедряет шаг умной постобработки, которая убеждается, что главные предложения не слишком похожи друг на друга.
TextRank похож на алгоритм LexRank, но имеет некоторые улучшений. К ним относятся:
- использование лемматизация вместо стемминга
- применение частеречной разметки и распознавания имени объекта
- извлечению ключевых фраз и предложений, на основе этих слов
- вместе с кратким содержанием статьи TextRank извлекает важные ключевые фразы.
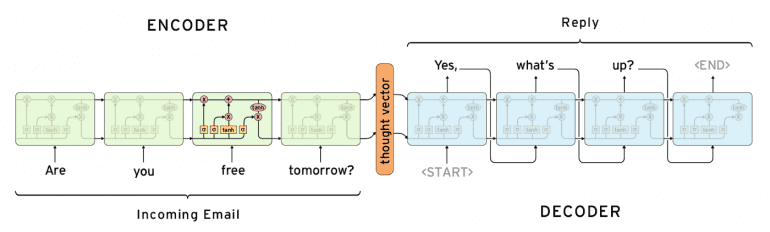
Модели для абстрактного резюмирования
используют глубокое обучение, которое позволило сделать прорывы в таких задачах. Ниже представлены примечательные результаты больших компаний в области NLP:
Вопросно-ответные (QA) системы
Идея вопросно-ответных (Question-answering, далее — QA) систем
заключается в извлечении информации непосредственно из документа, разговора, онлайн поиска или любого другого места, удовлетворяющего потребности пользователя. Вместо того, чтобы заставлять пользователя читать полный текст, QA системы предпочитают давать короткие и лаконичные ответы. Сегодня QA системы легко комбинируются с чат-ботами, выходят за пределы поиска текстовых документов и извлекают информацию из набора картинок.
Большинство NLP задач могут быть рассмотрены как вопросно-ответные задачи. Парадигма проста: отправляется запрос, на который машина предоставляет ответ. Через чтение текста или набора инструкций разумная система должна находить ответ на большой круг вопросов. Естественно, требуется создать модель для ответов на общие вопросы.

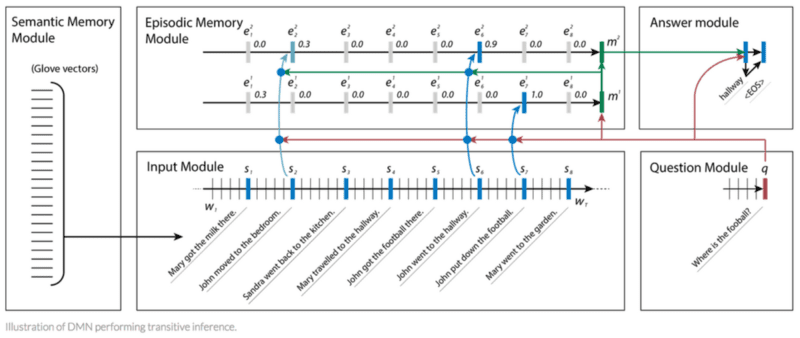
Специально для QA задач создана и оптимизирована мощная архитектура глубокого обучения — Сеть Динамической Памяти (Dynamic Memory Network, далее — DNM)
. Обученная на тренировочном наборе из входных данных и вопросов, DNM формирует эпизодические воспоминания и использует их для генерации подходящих ответов. Эта архитектура состоит из следующих компонент:
- Модуль семантической памяти
, аналогичный базе знаний, состоит из предварительно подготовленных GloVe векторов, которые используются для создания последовательностей векторных представлений слов из входящих предложений. Эти вектора будут использоваться, как входные данные модели. - Входной модуль
перерабатывает связанные с вопросом входящие вектора в наборов векторов, называемый фактами. Этот модуль реализован с помощью Управляемого рекуррентного блока (Gated Recurrent Unit, далее — GRU), который позволяет сети узнать релевантность рассматриваемого предложения. - Вопросный модуль
обрабатывает вопрос слово за словом и выдает вектор, используя тот же GRU, что и в входном модуле, с такими же весами. - Модуль эпизодической памяти
сохраняет извлеченные на входе векторы фактов и вопросов, закодированные как вложения. Это похоже на происходящий в гиппокампе мозга процесс по извлечению временных состояний в ответ на звук или вид. - Ответный модуль
генерирует подходящий ответ. На последнем шаге эпизодическая память содержит необходимую для ответа информацию. Этот модуль использует другой GRU, обученный с классификацией кросс-энтропийной ошибки верной последовательности, которая конвертируется обратно на естественный язык.
DNM хорошо справляется с QA задачами и превосходит в результатах другие архитектуры для семантического анализа и частеречной разметки (part-of-speech tagging). С момента выпуска начальной версии DMN претерпела ряд улучшений для дальнейшего совершенствования точности в QA задачах:
Word2vec
В 2013 году Томас Миколов (Tomas Mikolov) из Google предложил более эффективную модель обучения векторных представлений слов – Word2vec
. Метод основывался на предположении, что слова, которые часто находятся в одинаковых контекстах, имеют схожие значения. Изменения были просты – устранение скрытого слоя и аппроксимация (упрощение) цели – но стали поворотной точкой в развитии языковых моделей NLP.
Вместо алгоритма непрерывного мешка слов модель Word2Vec использует Skip-gram
(словосочетание с пропуском). Цель этой модели прямо противоположная предыдущей модели – предсказать окружающие слова на основе центрального.
Формируется «контекстное окно» – последовательность из k слов в тексте. Одно из этих слов пропускается, и нейросеть пытается его предсказать. Таким образом, слова, которые часто встречаются в похожем контексте, будут иметь похожие векторы.
Чтобы сделать обучение эффективнее, используется негативное семплирование
(Negative Sampling): модели предоставляются слова, которые не являются контекстными соседями.
Многие слова в текстах не встречаются вместе, поэтому модель выполняет много лишних вычислений. Подсчёт softmax — вычислительно дорогая операция. Подход Negative Sampling позволяет максимизировать вероятность встречи нужного слова в контексте, который является для него типичным, и минимизировать – в редком/нетипичном контексте.
