
- Зачем нужно объяснимое машинное обучение
- Библиотека LIME
- Деревья Решений & Случайные Леса
- Библиотека SHAP
- Базовые принципы машинного обучения на примере линейной регрессии
- SHAP на практике
- Waterfall plot
- Summary plot
- Dependence plot
- Диагностика сдвига данных с помощью SHAP loss values
- Supervised-кластеризация данных с помощью SHAP
- Библиотека SkLearn
- Определение машинного обучения с учителем
- Остались вопросы?
- Permutation Importance
- Решаемые задачи
- Стекинг
- Бэггинг
- Байесовская интерпретация линейной регрессии
- Виды нейронных сетей
- Полиномиальная регрессия
- Определение машинного обучения без учителя
- Определение Машинного Обучения
Зачем нужно объяснимое машинное обучение
Модели машинного обучения считаются «черными ящиками».
Это не означает, что мы не можем получить от них точный прогноз, мы не можем понятно объяснить или понять логику их работы.
Четкое математическое определение интерпретируемости в машинном обучении отсутствует. Есть несколько определений:
• Интерпретируемость — это степень, в которой человек может понять причину решения (Миллер (2017)).
• Интерпретируемость — это степень, в которой человек может последовательно предсказывать результат модели. Чем выше интерпретируемость модели машинного обучения, тем легче кому-то понять, почему были приняты определенные решения или прогнозы. Модель лучше интерпретируется, чем другая модель, если ее решения легче понять человеку, чем решения другой модели.
• Интерпретируемость — это способность объяснить ее действие или показать его в понятном человеку виде.
Модель оказывает определенное влияние на последующие принятия решений, например, в системах поддержки принятия врачебных решений (СППВР). Очевидно, что интерпретируемость для СППВР будет гораздо важнее, чем для тех моделей, которые используются для прогнозирования результата классификации вин.
«Проблема заключается в том, что всего одна метрика, такая как точность классификации, является недостаточным описанием большинства реальных задач.» (Доши-Велес и Ким) 2017.
Для понимания и интерпретация работы модели нам потребуются:
- Определить наиболее важные признаки ( feature importance
) в модели. - Для конкретного прогноза модели влияние каждого отдельного признака на конкретный прогноз.
- Влияние каждого признака на большое количество возможных прогнозов.
Рассмотрим несколько методов, которые помогают извлекать вышеперечисленные особенности из модели.
Библиотека LIME
LIME (локально интерпретируемое объяснение, не зависящее от устройства модели) — это библиотека Python, которая пытается найти интерпретируемую модель, предоставляя точные локальные объяснения https://github.com/marcotcr/lime
.
Lime поддерживает объяснения для индивидуальных прогнозов широкого круга классификаторов. Встроена поддержка scikit-learn.
Ниже приведен пример одного такого объяснения проблемы классификации текста.
Вывод LIME представляет собой список объяснений, отражающих вклад каждой функции в прогноз выборки данных. Это обеспечивает локальную интерпретируемость, а также позволяет определить, какие изменения характеристик окажут наибольшее влияние на прогноз.

Деревья Решений & Случайные Леса
Про это я уже рассказывала в предыдущей статья, вы можете найти ее здесь (Деревья Решений и Случайные Леса ближе к концу):
Библиотека SHAP
SHAP (SHapley Additive explanation) — метод помогает разбить на части прогноз, чтобы выявить значение каждого признака. Он основан на Векторе Шепли, принципе, используемом в теории игр для определения, насколько каждый игрок при совместной игре способствует ее успешному исходу ( https://medium.com/civis-analytics/demystifying-black-box-models-with-shap-value-analysis-3e20b536fc80
).
SHAP – значения показывают, насколько данный конкретный признак изменил предсказание по сравнению при базовом значении этого признака. Допустим, мы хотели узнать, каким был бы прогноз, если бы команда забила 3 гола, вместо фиксированного базового количества.
Признаки, продвигающие прогноз выше, показаны красным цветом, а те, что понижают его точность – ниже.

Агрегирование множества SHAP-значений поможет сформировать более детальное представление о модели. Чтобы получить представление о том, какие признаки наиболее важны для модели, мы можем построить SHAP – значения для каждого признака и для каждой выборки. Сводный график показывает, какие признаки являются наиболее важными, а также их диапазон влияния на датасет.
Для каждой точки цвет показывает, является ли этот объект сильно значимым или слабо значимым для этой строки датасета; Горизонтальное расположение показывает, привело ли влияние значения этого признака к более точному прогнозу или нет.
Значения упорядочены сверху вниз, вверху являются наиболее важными признаками, а значения в направлении к низу имеют наименьшее значение.
Первое число в каждой строке показывает, насколько снизилась производительность модели при случайной перетасовке (в данном случае с использованием «точности» в качестве метрики производительности). Существует некоторая случайность в точном изменении производительности от перетасовки столбца. Мы измеряем количество случайности в нашем вычислении важности перестановки, повторяя процесс с несколькими перестановками. Число после ± измеряет изменение производительности от одной перестановки к следующей. Иногда отображаются отрицательные значения импорта перестановок. В этих случаях прогнозы по перетасованным (или шумным) данным оказались более точными, чем реальные данные. Это происходит, когда функция не имела значения (должна была иметь значение, близкое к 0), но случайный шанс привел к тому, что прогнозы по перетасованным данным были более точными. Это чаще встречается с небольшими наборами данных, как в этом примере, потому что есть больше места для удачи/шанса. Некоторые веса отрицательны. Это связано с тем, что в этих случаях прогнозы по перетасованным данным оказались более точными, чем реальные данные.
Базовые принципы машинного обучения на примере линейной регрессии

Здравствуйте, коллеги! Это блог открытой русскоговорящей дата саентологической ложи
. Нас уже легион, точнее 2500+ человек в слаке. За полтора года мы нагенерили 800к+ сообщений (ради этого слак выделил нам корпоративный аккаунт). Наши люди есть везде и, может, даже в вашей организации. Если вы интересуетесь машинным обучением, но по каким-то причинам не знаете про Open Data Science
, то возможно вы в курсе мероприятий, которые организовывает сообщество. Самым масштабным из них является DataFest
, который проходил недавно в офисе Mail. Ru Group
, за два дня его посетило 1700 человек. Мы растем, наши ложи открываются в городах России, а также в Нью-Йорке, Дубае и даже во Львове, да, мы не воюем, а иногда даже и употребляем горячительные напитки вместе. И да, мы некоммерческая организация, наша цель — просвещение. Мы делаем все ради искусства. (пс: на фотографии вы можете наблюдать заседание ложи в одном из тайных храмов в Москве).
Мне выпала честь сделать первый пост, и я, пожалуй, отклонюсь от своей привычной нейросетевой тематики
и сделаю пост о базовых понятиях машинного обучения на примере одной из самых простых и самых полезных моделей — линейной регрессии. Я буду использовать язык питон для демонстрации экспериментов и отрисовки графиков, все это вы с легкостью сможете повторить на своем компьютере. Поехали.
SHAP на практике
Для подсчета SHAP values существует python-библиотека shap
, которая может работать со многими ML-моделями (XGBoost, CatBoost, TensorFlow, scikit-learn и др) и имеет документацию с большим количеством примеров. С помощью бибилиотеки SHAP можно строить различные схемы и графики, описывающие важность признаков в модели и их влияние на ответ. Рассмотрим примеры из документации.
Waterfall plot
На рис. 5
показан waterfall
plot, объясняющий предсказание на первом тестовом примере из датасета Boston housing. S HAP values получены с помощью метода Tree SHAP. Схема читается снизу вверх, и признаки упорядочены по возрастанию их SHAP values. Например, SHAP value -0.43 для признака CRIM (имеющего значение 0.006) говорит о том, что значение CRIM=0.006 на данном примере уменьшает величину предсказания модели, по сравнению с отсутствием признака CRIM, при произвольном наличии других признаков (см. » Shapley values в теории игр»).

Summary plot
Рассчитав SHAP value для каждого признака на каждом примере с помощью shap. Explainer
или shap. KernelExplainer
(есть и другие способы, см. документацию), мы можем построить summary plot, то есть summary plot объединяет информацию из waterfall plots для всех примеров.
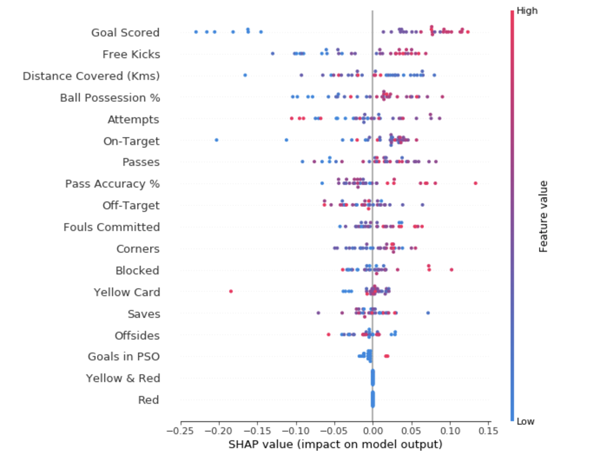
На рис. 6
summary plot построен для модели, обученной на датасете, описывающем влияние различных медицинских анализов на вероятность смерти в течение следущих 12 лет ( Cox et al., 1997
). Рисунок взят из Lundberg et al., 2019
. S HAP values при этом получены с помощью метода Tree SHAP.
Каждая горизонтальная линия соответствует одному признаку, и на этой линии отмечаются точки, соответствующие тестовым примерам: кордината точки на линии соответствует SHAP value, цвет точки — значению признака. Если в каком-то участке линии не хватает места для всех точек, линия начинает расти в ширину. Таким образом, для каждого признака схема представляет собой слившееся множество точек, по одной точке для каждого примера
Слева на рис. 6
показана важность признаков, рассчитанная как средний модуль величины SHAP values для данного признака.

Очевидное влияние на риск смерти имеет возраст, а также пол (женщины среднестатистически живут дольше). Мы видим, что чем больше возраст (красный цвет), тем большее SHAP value (горизонтальная ось) назначается этому признаку. Большое значение SHAP value, в свою очередь, означает, что удаление этого признака (замена значения возраста на неопределенное) существенно уменьшит предсказанную вероятность смерти в течение 12 лет.
Можно также заметить, что большинство SHAP values, соответствующих медицинским анализам (строки 3 и далее), имеют либо оклонулевые, либо положительные значения SHAP values. Это означает, что есть много значений анализов, увеличивающих предполагаемый риск смерти (для данной модели), но нет таких значений, которые бы его сильно уменьшали.
Interestingly, rare mortality effects always stretch to the right, which implies there are many ways to die abnormally early when medical measurements are out-of-range, but not many ways to live abnormally longer. ( Lundberg et al., 2019
)
Одно из преимуществ SHAP summary plot по сравнению с глобальными методами оценки важности признаков (такими, как mean impurity decrease или permutation importance) состоит в том, что на SHAP summary plot можно различить 2 случая: (А) признак имеет слабое влияние, но во многих примерах, (Б) признак имеет большое влияние, но в немногих примерах.
SHAP summary plots avoid conflating the magnitude and prevalence of an effect into a single number, and so reveal rare high magnitude effects. ( Lundberg et al., 2019
)
Dependence plot
На рис. 7 C
мы видим совместное распределение SHAP value для признака Systolic blood pressure
и значения этого признака по тестовому датасету. Фактически это та же самая информация, что показана в summary plot для этого признака. На рис. 7 D
показаны SHAP interaction values (их способ рассчета мы не рассматривали в этом обзоре) для пары признаков: Systolic blood pressure
+ Age
. На рис. 7 B
показана схема (SHAP dependence plot), объединяющая информацию из схем на рис. 7 C и 7D
. Рисунки взяты из Lundberg et al., 2019
.
Как можно видеть, совместное распределение на рис. 7 B
имеет «два хвоста». Для возраста 30-40 (синий цвет) систолическое давление 160+ mmHg повышает предсказанную вероятность смерти в течение 12 лет, тогда как для возраста 60-70+ это же давление является нормальным (соответствующим возрасту) и дополнительно не повышает вероятность смерти в течение 12 лет.
early onset high blood pressure is more concerning to the model than late onset high blood pressure ( Lundberg et al., 2019
)
Следует помнить, что при этом мы изучаем обученную модель, а не только данные. Модель может ошибаться, и тогда выводы о целевой зависимости, сделанные на основе SHAP values, тоже будут неверны.

Диагностика сдвига данных с помощью SHAP loss values
Cдвиг данных является серьезной проблемой в машинном обучении. Он может быть вызван недостаточным разнообразием обучающих данных, изменениями в методах расчета признаков и ошибками в их обработке после развертывания модели.
Deploying machine learning models in practice is challenging because of the potential for input features to change after deployment. It is hard to detect when such changes occur, so many bugs in machine learning pipelines go undetected, even in core software at top tech companies. ( Lundberg et al., 2019
).
Для диагностики сдвига данных можно использовать Shapley values, считая результатом кооперативной игры не предсказание модели, а функцию потерь. Тогда мы сможем определить, какие признаки вносят положительный или отрицательный вклад в точность модели.
В работе «Explainable AI for Trees» ( Lundberg et al., 2019
) авторы проводят следующий эксперимент. В качестве данных используется датасет, целевым признаком в котором является длительность процедуры анастезии перед операцией. Датасет содержит данные за 4 года (2185 признаков и ок. 147000 пациентов). Данные за первый год используются для обучения, данные за следующие три года — для тестирования (симуляции работы системы по разначению). Отметим, что это не временной ряд: каждый пример независим.
График метрики качества на тестовых данных (в зависимости от даты) показан на рис. 8
. Такие графики используют для мониторинга качества работы системы. Метрика качества на обучающих данных (первый год) намного лучше, что естественно.

На каждом тестовом примере можно рассчитать SHAP loss values, считая игроками наличие признаков, а характеристической функцией набора признаков — точность предсказания на данном примере. Поскольку каждый тестовый пример соответствует определенной дате, то мы можем построить для каждого признака график зависимости Shapley loss values от даты. На Рис. 9
показаны такие графики для трех бинарных признаков (цветом обозначено значение признака).

Первый признак «in room #6»
означает, что процедура проводилась в комнате номер 6. При обучении этот признак понижал ошибку предсказания времени процедуры, но при симуляции работы по назначению с какого-то момента стал резко повышать ошибку, то есть наличие этого признака стало вредным. Причина кроется в том, что в коде обработки признаков была допущена ошибка: перепутаны номера комнат 6 и 13. Данная ошибка была допущена исследователями намеренно, чтобы показать эффективность SHAP loss values в обнаружении подобных проблем. При этом на графике функции потерь этой проблемы не видно, так как она затрагивает лишь небольшой процент данных.
Следующие две проблемы, напротив, были ненамеренными и обнаружены случайно. Признак «general anasthesia»
в определенный момент резко снижал точность предсказания. Как выяснилось, проблема была связана с ошибкой в конфигурации электронного оборудования.
На признаке «atrial fibrillation»
виден дрейф значений SHAP loss values: со временем этот признак становится все менее полезным, и в итоге начинает понижать точность предсказания времени процедуры. Как выяснилось, это вызвано изменениями в длительности процедуры абляции фибрилляции предсердий, которая связана с изменениями в технологиях и персонале.
Supervised-кластеризация данных с помощью SHAP
Из SHAP values можно составить SHAP-вектор для каждого обучающего или тестового примера. Lundberg et al., 2018
заметили, что SHAP-векторы можно использовать для кластеризации данных намного эффективнее, чем вектора исходных признаков.
Задача кластеризации данных достаточно нетривиальна. Как правило, мы не можем выполнить кластеризацию просто на основе евклидова расстояния между векторами признаков, так как признаки различаются по важности, имеют разный масштаб, и некоторые признаки могут дублировать друг друга.
Элементы SHAP-вектора соответствуют отдельным признакам, но при этом каждый элемент SHAP-вектора представлен в одной и той же шкале. При этом величина SHAP value означает важность признака (в контексте задачи предсказания целевого признака). Исходя из этого, можно выполнять supervised-кластеризацию в пространстве SHAP-векторов.
На рис. 10
показана кластеризация с помощью SHAP на датасете, описывающем риск смерти в течение 12 лет на основе медицинских анализов (об этом датасете см. также раздел «Summary plot»). Каждый столбец представляет собой SHAP-вектор для одного пациента, и эти векторы упорядочены (локально) по сходству друг с другом с помощью алгомеративной иерархической кластеризации и (глобально) по значению целевого признака, объединяясь в кластеры людей со сходной симптоматикой.

Другой пример из Lundberg et al., 2018
изображен в трехмерном формате ( рис. 11
). В данном случае показаны примеры из датасета
, в котором целевой переменной является вероятность месячного заработка больше $50К. Примеры здесь тоже кластеризованы с помощью их SHAP-векторов («sorted by explanation similarity»), то есть мы ищем группы примеров, предсказания на которых объясняются схожим образом. Полученным кластерам даны текстовые описания.

Библиотека SkLearn
SkLearn — самый распространенный выбор для решения задач классического машинного обучения. Классы в модуле sklearn.feature_selection ( https://scikit-learn.org/stable/modules/feature_selection.html#rfe
) могут использоваться для выбора признаков / уменьшения размерности на выборочных наборах, либо для улучшения показателей точности оценщиков, либо для повышения их производительности на очень многомерных наборах данных.
Так, библиотека sklearn и метод рекурсивного отбора признаков , были использованы в модели прогнозирования возникновения ампутации нижних конечностей у пациентов с сахарным диабетом 2 типа в течение 5 лет. Изначально были использованы 99 возможных признаков объективных и лабораторных данных пациентов с сахарным диабетом 2 типа. С помощью этого метода оценивалось различное количество N признаков и их влияние на точность предсказания. В итоге были выбраны только 20 признаков (триглицериды, прием препаратов: периферические альфа-адреноблокаторы, сульфонилмочевины, ингибиторы альфа-глюкозидазы, ингибиторы абсорбции холестерина, пероральные антикоагулянты, повышение микро или макроальбуминурия в течение последних 2 лет, ГЛЖ по ЭКГ или эхокардиограмме за последние 2 года, табакокурение, наличие ретинопатии), при которых модель достигает наибольшей точности AUC =0.809.
Определение машинного обучения с учителем
Обучение с учителем — это тип машинного обучения, в котором данные, которые вы засовываете в модель «помечаются». Пометка просто означает, что результат наблюдения (то есть ряд данных) известен. Например, если ваша модель пытается предсказать пойдут ли ваши друзья играть в гольф или нет, у вас могут быть такие переменные, как погода, день недели и так далее. Если ваши данные помечены, то ваша переменная будет иметь значение 1, в том случае если ваши друзья пошли играть в гольф, и значение 0, если они не пошли.
Остались вопросы?
Оставьте контактные данные и мы свяжемся с вами в ближайшее время
Permutation Importance
Какие признаки модель считает важными? Какие признаки оказывают наибольшее влияние? Эта концепция называется важностью признаков ( feature importance
), а Permutation Importance
– это метод, широко используемый для вычисления важности признаков. Он помогает нам увидеть, в какой момент модель выдает неожиданные результаты или работает корректно.
Permutation importance отличается:
- Его быстро посчитать;
- Широко применяется и легко понимается;
- Используется вместе с метриками, которые обычно используются.
Допустим, у нас есть датасет. Мы хотим предсказать рост человека в 18 лет, используя данные, которые о нем имеются в 12 лет. Проведя случайное переупорядочивание одного столбца, получим выходные прогнозы менее точными, так как полученные данные больше не соответствуют чему-либо в нашем датасете.
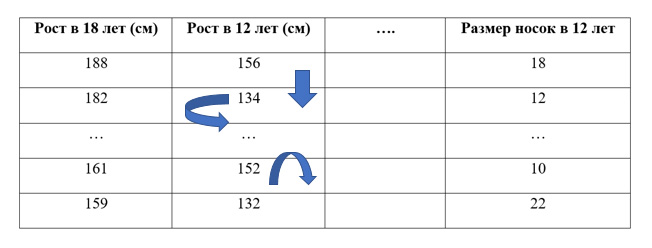
Точность модели особенно страдает, если мы перемешиваем столбец
, на который модель сильно
опиралась для прогнозов
. В этом случае перетасовка «роста в 12 лет»
вызвала бы непредсказуемые прогнозы. Если бы вместо этого, мы перетасовали «размер носок», то предсказания не пострадали бы так сильно.
Процесс выявления важности признаков выглядит следующим образом:
- Получаем обученную модель на «нормальных» данных, вычисляем для нее метрики, в том числе и значение функции потерь.
- Переставляем значения в одном столбце, прогнозируем с использованием полученного набора данных. Используем эти прогнозы и истинные целевые значения, чтобы вычислить, насколько функция потерь ухудшилась от перетасовки. Это ухудшение производительности измеряет важность переменной, которую только что перемешали.
- Возвращаем данные к исходным значениям и повторяем шаг 2 со следующим столбцом в наборе данных, пока вычисляется важность каждого столбца.
Для вычисления permutation importance
есть несколько готовых библиотек, рассмотрим примеры работы с ними.
Решаемые задачи
Алгоритмы машинного обучения подразделяют на «Обучение с учителем» (Supervised Learning, привет переводчику) и «Обучение без учителя» (Unsupervised Learning). Года два назад я был уверен, что речь идет о самообучаемых алгоритмах и о тех, за которыми надо присматривать. На самом деле здесь идет речь о двух группах:
Supervised — для которых нужны заранее размеченные данные в обучающих выборках (подписать картинки, есть там собака или нет, проставить стоимость для каждого дома и т.д.);
Unsupervised — для которых разметка не требуется (Кластеризация, Понижение размерности), о них чуть ниже.
Рассмотрим сами алгоритмы, начнем с Классификации
, выше уже был пример: что находится на фото (кошка, собака и т.д.)? Другие классические примеры: является ли письмо спамом (бинарная классификация, т.к. ответ да/нет), распознавание букв и цифр на изображениях.
Регрессия
: в самом начале статьи была задача «определение стоимости недвижимости» — это вот оно. По каким-то исходным данным мы выводим новые цифры. Предсказание температуры на завтра — аналогично.
Генерация контента
, можно выполнить
с помощью Автокодировщика. Для этого используется специфическая нейронная сеть с «бутылочным горлышком»:

При обучении такую сеть заставляют на выходе генерировать точно такие же данные, что поступили на вход, например, в обучающую выборку включают разные фото травы. После завершения обучения сеть разрывают:

Теперь, подавая на вход пару чисел, на выходе мы можем получить совершенно новые изображения травы (либо белеберду, как повезет). Внутри Автокодировщика можно использовать полносвязные сети, CNN и RNN, а также любые их комбинации, важно только создать бутылочное горлышко.
Более современный способ генерации контента — Генеративно-состязательная сеть (Generative adversarial network, GAN
). В этом случае обучаются две нейросети: первая учится распознавать контент, а вторая его генерировать. В процессе обучения выход второй сети на каждом шаге скармливают первой. После обучения для генерации используется только вторая сеть.
Нейросети можно также использовать для модификации контента: в обучающей выборке на вход подаем исходное изображение, на выход — требуемое. Если обучение прошло успешно, нейросеть будет выполнять аналогичные модификации для других изображений.
Кластеризация
: задача алгоритма — сгруппировать данные, анализируя похожесть их атрибутов, например, разбить базу недвижимости на 3 группы. На старте алгоритма вы задаете только количество групп, что в них войдет — алгоритм решит сам. Этот алгоритм не использует нейросети: как я писал в самом начале, Machine Learning — это группа алгоритмов.
Понижение размерности
: задача алгоритма — из большого количества атрибутов сделать чуть меньшее их количество. В принципе, примерно то же самое делает Автокодировщик на уровне своего бутылочного горлышка, но есть и популярный алгоритм без нейросетей: Метод главных компонент (Principal component analysis, PCA). Алгоритмы в том числе активно используются при обработке текстов.
Стекинг
Работа этого типа ансамблей довольно проста. На вход всех слабых прогнозаторов подаётся обучающий набор, каждый прогноз идёт к финальной модели, которая называется смеситель, мета-ученик или мета-модель, после чего та вырабатывает финальный прогноз.

При обучении мета-модели используется приём удерживаемого набора. Сначала набор разделяется на 2 части. Слабые ученики обучаются на первой половине обучающего набора, затем на второй. Затем создаётся новый обучающий набор на основе прогнозов, сделанных на прогнозах первой и второй части набора. Таким образом, на каждый образец из входного набора приходится столько прогнозов, сколько слабых учеников в ансамбле (в примере на картинке три). Мета-модель учится прогнозировать значения на основе нового набора.
Код на Python
from sklearn.ensemble import StackingClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
data, target = load_breast_cancer(return_X_y=True)
estimators = [('lr', LogisticRegression()), ('dt', DecisionTreeClassifier())]
modelClf = StackingClassifier(estimators=estimators, final_estimator=SVC())
X_train, X_valid, y_train, y_valid = train_test_split(data, target, test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
print(modelClf.score(X_valid, y_valid))
Ссылка на документацию: Классификатор
/ Регрессор
.
Бэггинг
Основная идея бэггинга заключается в том, чтобы обучить несколько одинаковых моделей на разных образцах. Распределение выборки неизвестно, поэтому модели получатся разными.
Для начала генерируется несколько бутстрэп-выборок. Бутстрэп — это случайный выбор данных из датасета и представление их в модель, затем данные возвращаются в датасет и процесс повторяется. После модели делают свои прогнозы на основе бутстрэп-выборок. В случае регрессии прогнозы просто усредняются. В случае же классификации применяется голосование.

Если класс предсказывает большинство слабых моделей, то он получает больше голосов и данный класс является результатом предсказывания ансамбля. Это пример жёсткого голосования. При мягком голосовании рассматриваются вероятности предсказывания каждого класса, затем вероятности усредняются и результатом является класс с большой вероятностью.
Код на Python
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
data, target = load_breast_cancer(return_X_y=True)
modelClf = BaggingClassifier(base_estimator=LogisticRegression(), n_estimators=50, random_state=12)
X_train, X_valid, y_train, y_valid = train_test_split(data, target, test_size=0.3, random_state=12)
modelClf.fit(X_train, y_train)
print(modelClf.score(X_valid, y_valid))
Ссылка на документацию: Классификатор
/ Регрессор
.
Байесовская интерпретация линейной регрессии
Две вышеописанные регуляризации, да и сама лининейная регрессия с квадратичной функцией ошибки, могут показаться какими-то грязными эмпирическими трюками. Но, оказывается, если взглянуть на эту модель с другой точки зрения, с точки зрения байесовой статистики, то все становится по местам. Грязные эмпирические трюки станут априорными предположениями. В основе байесовой статистики находится формула Байеса:

В статистике обычно ищут точечную оценку максимума правдоподобия (ML = maximum likelihood):

В то время как в байесовом подходе интересуются апостериорным распределением:

Часто получается так, что интеграл, полученный в результате байесового вывода, крайне нетривиален (в случае линейной регрессии это, к счастью, не так), и тогда нужна точечная оценка. Тогда мы интересуемся максимумом апостериорного распределения (MAP = maximum a posteriori):

Давайте сравним ML и MAP гипотезы для линейной регрессии, это даст нам четкое понимание смысла регуляризаций. Будем считать, что все объекты из обучающей выборки были взяты из общей популяции независимо и равномерно распределенно. Это позволит нам записать совместную вероятность данных (правдоподобие) в виде:

А также будем считать, что целевая переменная подчиняется следующему закону:


Т.е. верное значение целевой переменной складывается из значения детерминированной линейной функции и некоторой непрогнозируемой случайной ошибки, с нулевым матожиданием и некоторой дисперсией. Тогда, мы можем записать правдоподобие данных как:

удобнее будет прологарифмировать это выражение:

И внезапно мы увидим, что оценка, полученная методом максимального правдоподобия, – это то же самое, что и оценка, полученная методом наименьших квадратов. Сгенерируем новый набор данных большего размера, найдем ML решение и визуализируем его.
data = generate_wave_set(1000, 100)
X = np.vstack((np.ones(data['x_train'].shape[0]), data['x_train'])).T
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
# create cartesian product of parameters
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
# calculate MSE on dataset for each pairs of parameters
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML solution')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()

По оси абсцисс и ординат отложены различные значения всех двух параметров модели (решаем именно линейную регрессию, а не полиномиальную), цвет фона пропорционален значению правдоподобия в соответствующей точке значений параметров. M L решение находится на самом пике, где правдоподобие максимально.
Найдем MAP оценку параметров линейной регрессии, для этого придется задать какое-нибудь априорное распределение на параметры модели. Пусть для начала это будет опять нормальное распределение: 
.

x = np.linspace(-5, 5, 1000)
for scale in np.linspace(0.5, 1.4, 7):
plt.plot(x, norm.pdf(x, scale=scale), label='scale=%0.2f' % scale)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Normal distribution with different scale parameter')
plt.show()

Тогда апостериорное распределение примет вид:

Если расписать логарифм этого выражения, то вы легко увидите, что добавление нормального априорного распределения — это то же самое, что и добавление 
нормы к функции стоимости. Попробуйте сделать это сами. Также станет ясно, что варьируя регуляризационный параметр, мы изменяем дисперсию априорного распределения: 
.
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
# solve L2 problems for different values of
w_l2 = {}
lmbd_space = np.linspace(0.5, 1500, 500)
for lmbd in lmbd_space:
w_l2[lmbd] = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + lmbd*np.eye(X.shape[1])), X.T), data['y_train'])
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
# plot prior distribution of parameters
for i in range(1, 6):
plt.gcf().gca().add_artist(plt.Circle((0, 0), i*0.3, color='black', linestyle='--', alpha=0.1))
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
# plot MAP solutions
flag = True
for _, w_l2_solution in w_l2.items():
plt.plot(w_l2_solution[0], w_l2_solution[1], color='c', marker='.', mew=1, alpha=0.5,
label='MAP L2 solution' if flag else None)
flag = False
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML and MAP L2 for different values of lambda')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()

Теперь на график добавились круги, исходящие от центра — это плотность априорного распределения (круги, а не эллипсы из-за того, что матрица ковариации данного нормального распределения диагональна, а на диагонали находится одно и то же число). Точками обозначены различные решения MAP задачи. При увеличении параметра регуляризации (что эквивалентно уменьшению дисперсии), мы заставляем решение отдаляться от ML оценки и приближаться к центру априорного распределения. При большом значении параметра регуляризации, все параметры будут близки к нулю.
Естественно мы можем наложить и другое априорное распределение на параметры модели, например распределение Лапласа, тогда получим то же самое, что и при 
регуляризации.

from scipy.stats import laplace
x = np.linspace(-5, 5, 1000)
for scale in np.linspace(0.5, 1.4, 7):
plt.plot(x, laplace.pdf(x, scale=scale), label='scale=%0.2f' % scale)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Laplace distribution with different scale parameter')
plt.show()

Тогда апостериорное распределение примет вид:

w_l1 = {}
lmbd_space = np.linspace(0.001, 2, 200)
for lmbd in tqdm(lmbd_space):
w_l1[lmbd] = fit_lr_l1(X, data['y_train'], lmbd, n_iter=10000, lr=0.001)[0]
w0_support = np.linspace(-3, 3, 1000)
w1_support = np.linspace(-3, 3, 1000)
wx_space = list(it.product(w0_support, w1_support))
w0, w1 = zip(*wx_space)
y = ((data['y_train'][:, np.newaxis] - np.dot(X, np.array(wx_space).T))**2).mean(axis=0)
plt.hexbin(w0, w1, C=y**(0.2), cmap=cm.jet_r, bins=None)
plt.axvline(0, color='black', linestyle='-', label='origin')
plt.axhline(0, color='black', linestyle='-')
# function to plot rhomb
def plot_rhomb(cx=0, cy=0, r=0.5):
plt.gcf().gca().add_artist(plt.Rectangle((cx, cy - np.sqrt(2*r**2)), 2*r, 2*r, angle=45,
color='black', linestyle='--', alpha=0.1))
# plot Laplace distribution density
for i in range(1, 6):
plot_rhomb(r=0.2*i)
plt.axvline(w[0], color='w', linestyle='--', label='ML solution')
plt.axhline(w[1], color='w', linestyle='--')
# plot MAP solutions
flag = True
for _, w_l1_solution in w_l1.items():
plt.plot(w_l1_solution[0], w_l1_solution[1], color='c', marker='.', mew=1, alpha=0.5,
label='MAP L1 solution' if flag else None)
flag = False
plt.axes().set_aspect('equal', 'datalim')
plt.title('ML and MAP L1 for different values of lambda')
plt.xlabel('w_0')
plt.ylabel('w_1')
plt.legend(loc='upper left', prop={'size': 20})
plt.show()

Глобальная динамика не изменилась: увеличиваем параметр регуляризации — решение приближается к центру априорного распределения. Также мы можем наблюдать, что такая регуляризация способствует нахождению разреженных решений: вы можете видеть два участка, на которых сначала один параметр равен нулю, затем второй параметр (в конце оба равны нулю).
И на самом деле два описанных регуляризатора — это частные случаи наложения обобщенного нормального распределения
в качестве априорного распределения на параметры линейной регрессии:

from scipy.stats import gennorm
x = np.linspace(-5, 5, 1000)
for beta in np.linspace(0, 3, 11):
plt.plot(x, gennorm.pdf(x, beta=beta), label='beta=%0.2f' % beta)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Generalized normal distribution with different beta parameter')
plt.show()
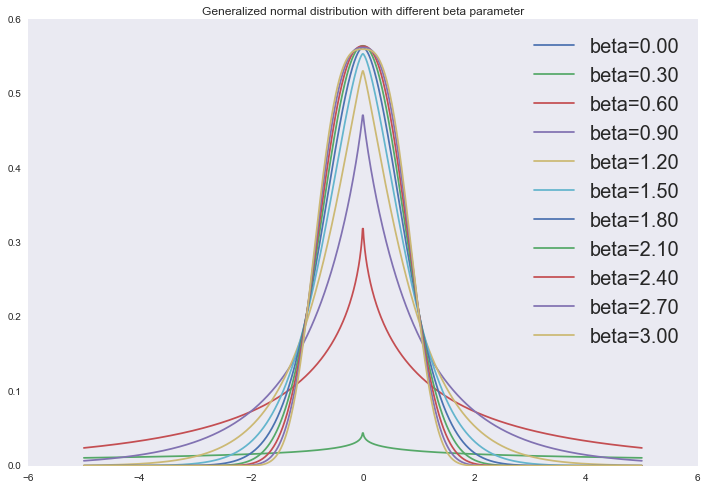
Или же мы можем смотреть на эти регуляризаторы с точки зрения ограничения 
нормы, как в предыдущей части:

f, ax = plt.subplots(3, 4)
ax = reduce(lambda a, b: a + b, ax.tolist())
a_list = np.linspace(0, 2*np.pi, 361)
r_list = np.linspace(0, 1.1, 100)
for ix, p in enumerate(np.linspace(0.25, 3, 12)):
points = []
for a in a_list:
r_inner = []
for r in r_list:
if np.linalg.norm([r*np.cos(a), r*np.sin(a)], p) > 1:
break
r_inner.append(r)
r = max(r_inner)
points.append([r*np.cos(a), r*np.sin(a)])
points = np.array(points)
ax[ix].plot(points[:, 0], points[:, 1])
ax[ix].set_aspect('equal', 'datalim')
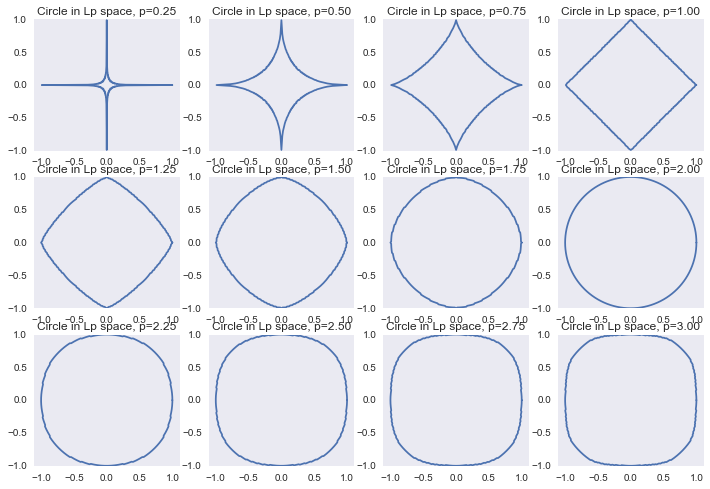
ax[ix].set_title('Circle in Lp space, p=%0.2f' % p)
Виды нейронных сетей
Выше уже был показан вариант Полносвязной
нейронной сети (Fully connected neural network), но они бывают еще и такими:

Здесь мы видим множество выходных значений. Такая сеть используется, например, в задачах классификации: на вход подаем пиксели картинки, на выходе получаем 20 чисел: y 1
— вероятность, что на фото есть собака, y 2
— кошка, и т.д. Одна нейронная сеть может распознавать тысячи объектов, но и сама она при этом становится объемнее (больше перцептронов, больше связей и весов). Также немного позже мы увидим, что сети с большим количеством выходов используются для генерации контента: на вход подаем несколько чисел, а на выходе получаем миллион значений — пиксели для картинки.
Кстати о картинках: в Полносвязную сеть пиксели изображения подаются построчно:

Это не очень-то логично, гораздо лучше близлежащие пиксели отправлять в нейросеть также рядышком:

Так и появились Сверточные нейронные сети
(Convolutional neural network), или просто CNN. Это все еще набор перцептронов с функциями активации внутри, но набор связей между ними специфический, уже не все со всеми. Обучаются они все тем же методом Backpropagation.

Выделенную на рисунке цветом область называют «Фильтр». Обычно это квадрат со стороной 3-5 пикселей. Фильтр накладывают на изображение: значения x умножаем на веса и суммируем их, т.е. пропускаем значения через перцептрон. Результат сохраняем в новый двумерный массив. Далее снова накладываем этот же фильтр на изображение, но уже сдвинув его вправо на один пиксель (иногда используют большее смещение), и так пробегаем по всему изображению. Все это повторяем с другими фильтрами (еще несколько перцептронов с другими значениями весов), сохраняя результаты в отдельные массивы. Отфильтрованные изображения прогоняем еще через несколько фильтров, подвергаем дополнительным обработкам, и результат можно, например, подать на полносвязную сеть.

Эти сети работают неплохо: даже если повернуть изображение на 180 градусов, сеть все равно найдет на ней собаку. Но именно этот эффект создает проблемы в задачах распознавания текстов. Изменение порядка слов в предложении может повлиять на его смысл, но полносвязная сеть и CNN не почувствуют разницы. Вот мы и подошли к третьему важному виду сетей — Рекуррентные нейронные сети
(Recurrent neural networks ) или RNN.
В литературе их часто называют нейросетями с памятью, но так можно сказать с очень большой натяжкой. Также в учебниках вы часто увидите попытку объяснить работу RNN через графы, но можно не забивать себе этим голову. Работают они очень просто:

Если вы пытаетесь предсказать температуру на завтра, то такая нейросеть будет оперировать не только текущими показаниями (облачность, сила и направление ветра), но и предыдущим значением температуры, что очень логично.
Для Состояния есть несколько усложнений, которые повышают качество работы RNN. Если мы хотим учитывать не только последнее выходное значение, но и несколько предыдущих, то формула вычисления Состояния немного меняется (исходный код, не математическая формула):
![S[1]=S[1]+w[51]*y](https://habrastorage.org/getpro/habr/upload_files/3c0/f80/331/3c0f803315cf1f8508a0cdfb83207841.svg)
Таким образом мы не полностью перезаписываем значение, а добавляем некоторое изменение, в зависимости от выходного значения.
Гораздо более продвинутая сеть — LSTM
(Long Short-Term Memory, Длительная краткосрочная память). Не будем пытаться понять ее название, перейдем сразу к сути: это все еще RNN, но с более сложным управлением Состояния. Перцептрон LSTM может внезапно обнулить свое Состояние (Забыть состояние), может отработать как обычная RNN (Запомнить состояние), и может какое-нибудь из Состояний внезапно не подать для вычислений (Выбрать состояние). Данное поведение управляется дополнительными весами. Обучение RNN и ее подвидов (LSTM) выполняется старым добрым Backpropagation.
Полиномиальная регрессия
В линейной регрессии мы ограничивали пространство гипотез только линейными функциями от признаков. Давайте теперь расширим пространство гипотез до всех полиномов степени 
. Тогда в нашем случае, когда количество признаков равно одному 
, пространство гипотез будет выглядеть следующим образом:

Если заранее предрассчитать все степени признаков, то задача опять сводится к описанному выше алгоритму — методу наименьших квадратов. Попробуем отрисовать графики нескольких полиномов разных степеней.
# список степеней p полиномов, который мы протестируем
degree_list = [1, 2, 3, 5, 7, 10, 13]
cmap = plt.get_cmap('jet')
colors = [cmap(i) for i in np.linspace(0, 1, len(degree_list))]
margin = 0.3
plt.plot(data['support'], data['values'], 'b--', alpha=0.5, label='manifold')
plt.scatter(data['x_train'], data['y_train'], 40, 'g', 'o', alpha=0.8, label='data')
w_list = []
err = []
for ix, degree in enumerate(degree_list):
# список с предрасчитанными степенями признака
dlist = [np.ones(data['x_train'].shape[0])] + \
map(lambda n: data['x_train']**n, range(1, degree + 1))
X = np.array(dlist).T
w = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), data['y_train'])
w_list.append((degree, w))
y_hat = np.dot(w, X.T)
err.append(np.mean((data['y_train'] - y_hat)**2))
plt.plot(data['x_train'], y_hat, color=colors[ix], label='poly degree: %i' % degree)
plt.xlim(data['x_train'].min() - margin, data['x_train'].max() + margin)
plt.ylim(data['y_train'].min() - margin, data['y_train'].max() + margin)
plt.legend(loc='upper right', prop={'size': 20})
plt.title('Fitted polynomial regressions')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
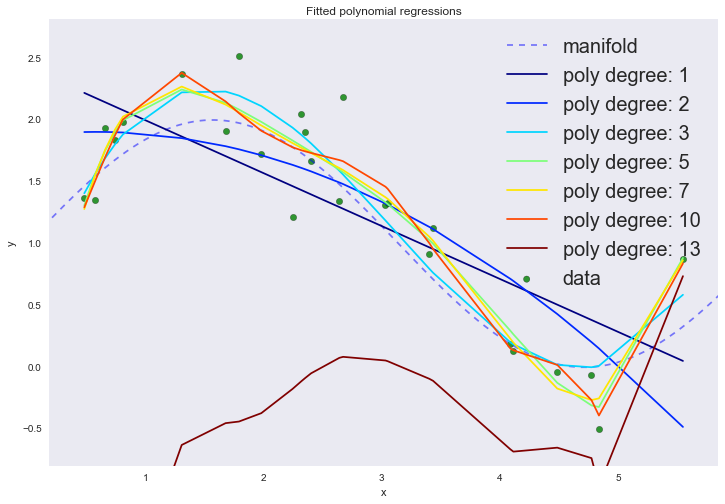
На графике мы можем наблюдать сразу два феномена. Пока не обращайте внимание на 13-ую степень полинома. При увеличении степени полинома, средняя ошибка продолжает уменьшаться, хотя мы вроде были уверены, что именно кубический полином должен лучше всего описывать наши данные.
Это явный признак переобучения, который можно заметить по визуализации даже не используя тестовый набор данных: при увеличении степени полинома выше третьей модель начинает интерполировать
данные, вместо экстраполяции
. Другими словами, график функции проходит точно через точки из тренировочного набора данных, причем чем выше степень полинома, тем через большее количество точек он проходит. Степень полинома отражает сложность
модели. Таким образом, сложные модели, у которых степеней свободы достаточно много, могут попросту запомнить весь тренировочный набор, полностью теряя обобщающую способность. Это и есть проявление негативной стороны принципа минимизации эмпирического риска.
Вернемся к полиному 13-ой степени, с ним явно что-то не так. По идее, мы ожидаем, что полином 13-ой степени будет описывать тренировочный набор данных еще лучше, но результат показывает, что это не так. Из курса линейной алгебры мы помним, что обратная матрица существует только для несингулярных матриц, т.е. тех, у которых нет линейной зависимости колонок или строк. В методе наименьших квадратов нам необходимо инвертировать следующую матрицу: 
. Для тестирования на линейную зависимость или мультиколлинеарность
можно использовать число обусловленности матрицы
. Один из способов оценки этого числа для матриц — это отношение модуля максимального собственного числа матрицы к модулю минимального собственного числа. Большое число обусловленности матрицы, или же наличие одного или нескольких собственных чисел близких к нулю свидетельствует о наличии мультиколлинеарности (или нечеткой мультиколлиниарности, когда 
). Такие матрицы называются слабо обусловленными, а задача — некорректно поставленной. При инвертировании такой матрицы, решения имеют большую дисперсию. Это проявляется в том, что при небольшом изменении начальной матрицы, инвертированные будут сильно отличаться друг от друга. На практике это всплывет тогда, когда к 1000 семплов, вы добавите всего один, а решение МНК будет совсем другим. Посмотрим на собственные числа полученной матрицы, нас там ждет сюрприз:
np.linalg.eigvals(np.cov(X[:, 1:].T))
Out[10]:
array([
9.29965299e+17+0.j , 4.04567033e+13+0.j ,
5.44657111e+09+0.j , 3.54104756e+06+0.j ,
8.36745166e+03+0.j , 6.82745279e+01+0.j ,
8.88434986e-01+0.j , 2.42827315e-02+0.00830052j,
2.42827315e-02-0.00830052j, 1.17621840e-03+0.j ,
1.72254789e-04+0.j , -5.68384880e-06+0.j ,
2.39611454e-07+0.j ])

Все так, numpy вернул два комплекснозначных собственных значения, что идет вразрез с теорией. Для симметричных и положительно определенных матриц (каковой и является матрица 
) все собственные значения должны быть действительные. Возможно, это произошло из-за того, что при работе с большими числами матрица стала слегка несимметричной, но это не точно
¯\_(ツ)_/¯. Если вы вдруг найдете причину такого поведения нумпая, пожалуйста, напишите в комменте.
UPDATE
(один из членов ложи по имени Андрей Оськин, с ником в слаке skoffer, без аккаунта на хабре, подсказывает):
Есть только одно замечание — не надо пользоваться формулой `(X^T X^{-1}) X^T` для вычисления коэффициентов линейной регрессии. Проблема с расходящимися значениями хорошо известна и на практике используют `QR` или `SVD`.
Ну, то есть вот такой кусок кода даст вполне приличный результат:
degree = 13 dlist = [np.ones(data['x_train'].shape[0])] + \ list(map(lambda n: data['x_train']**n, range(1, degree + 1))) X = np.array(dlist).T q, r = np.linalg.qr(X) y_hat = np.dot(np.dot(q, q.T), data['y_train']) plt.plot(data['x_train'], y_hat, label='poly degree: %i' % degree)
Определение машинного обучения без учителя
Как вы наверно могли угадать, когда речь идет о помеченных данных, обучение без учителя является противоположностью обучения с учителем. В обучении без учителя, вы не можете знать пошли ваши друзья играть в гольф или нет – только компьютер может найти закономерности с помощью модели, чтобы угадать, что уже произошло или предсказать, что произойдет.
Определение Машинного Обучения
Illustration of Machine Learning
Машинное обучение – это когда вы загружаете большое количество данных в компьютерную программу и выбираете модель, которая «подгонит» эти данные так, чтобы компьютер (без вашей помощи) мог придумывать прогнозы. Компьютер строит модели, используя алгоритмы, которые варьируются от простых уравнений (например, уравнение прямой) до очень сложных систем логики/математики, которые позволяют компьютеру сделать самые лучшие прогнозы.
Название – машинное обучение — очень удачное, потому что как только вы выбираете модель, которую будете использовать и настраивать (другими словами, улучшать с помощью корректировок), машина будет пользоваться моделью для изучения закономерностей в ваших данных. Затем вы можете добавить новые условия (наблюдения) и она предскажет результат!