
- ООП
- Классы и объекты
- Магические методы
- @property
- @staticmethod
- @classmethod, cls, self
- __dict__
- __slots__
- Утиная типизация
- Iterator
- Comparable
- Hashable
- Sortable
- Callable
- Утиная типизация итерируемых объектов
- Iterable
- Collection
- Sequence
- ABC Sequence
- Таблица требуемых и доступных методов:
- Копирование объектов
- Наследование
- Множественное наследование
- Наследование классов со __slots__
- Метапрограммирование
- @abstractmethod
- Структуры данных
- Список (list)
- Кортеж (tuple)
- Именованный кортеж (named tuple)
- Словарь (dict)
- Решение проблемы вычисления хеша при работе со словарем
- Defaultdict
- Счетчик (counter)
- Множество (set)
- Иммутабельное множество (frozen set)
- Массив (array, bytes, bytearray)
- Односвязный список
- Двусвязный список (Deque)
- Queue
- Бинарное дерево (binary tree)
- Куча (heap)
- Би-дерево (B-tree)
- Красно-черное дерево
- АВЛ-дерево
- Префиксное дерево
- Таблица выбора структуры данных
- Перечисление (Enum, IntEnum)
- Целочисленный диапазон (range)
- Классы данных (dataclass)
- Бинарная запаковка (struct)
ООП
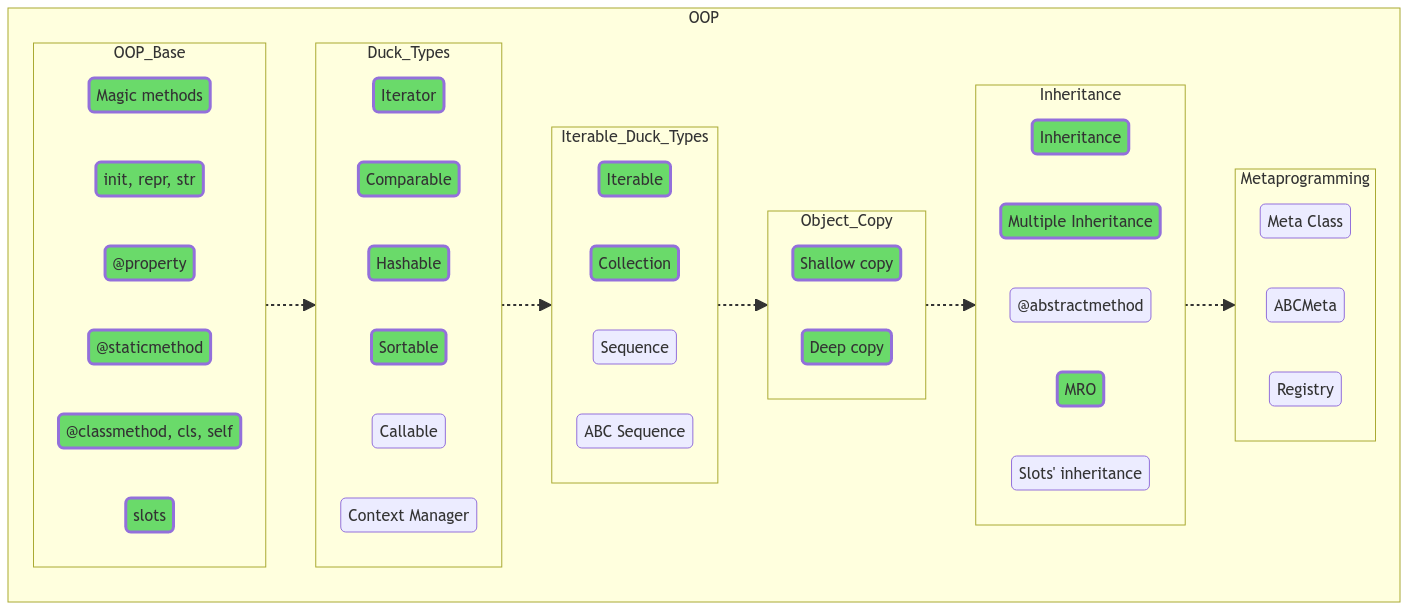
Классы и объекты
Мы попробуем вернуться к теме объектов с чуть более серьезным настроением позже, в главе «Архитектура», но, вообще, в объектно-ориентированном программировании нет ничего особо сложного; просто до него лучше дойти, предварительно немного погрязнув в поддержке обычного процедурного подхода, когда зачастую стоит выбор — попробовать подлечить этот кусок кода или уже усыпить и переписать всё по новой? Когда-то давно, когда я писал относительно несложные программы на ассемблере для микроконтроллеров, то читая Страуструпа, слегка недоумевал — зачем всё это? Чтобы осознать потребность в обуви, надо походить босиком.
Магические методы
Специальные (называемые также magic или dunder) методы класса — перегрузка, позволяющая классам определять собственное поведение по отношению к операторам языка.
Магические они потому, что почти никогда не вызываются явно. Их вызывают встроенные функции или синтаксические конструкции. Например, функция len() вызывает метод __len__() переданного объекта. Метод __add__(self, other) вызывается автоматически при сложении оператором +.
Примеры магических методы:
__init__: конструктор класса
__add__: сложение с другим объектом
__eq__: проверка на равенство с другим объектом
__cmp__: сравнение (больше, меньше, равно)
__iter__: при подстановке объекта в цикл
print(dir(int), "\n")
class A: # An empty class
...
a = A()
print(dir(a), "\n")
print(repr(a), "\n")
print(str(a))
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
<__main__.A object at 0x000001A1FFF3AF20>
<__main__.A object at 0x000001A1FFF3AF20>
Особенностью метода __init__ является то, что он не должен ничего возвращать. При попытке возврата данных будет сгенерировано исключение.
__repr__ (representation) возвращает более-менее машино-читаемое представление объекта, полезное для отладки.
Иногда
repr может содержать достаточно информации для восстановления объекта.
__str__ возвращает человеко-читаемое сообщение. Если __str__ не определён, то str использует repr.
class Person: # A simple class with init, repr and str methods
def __init__(self, name: str):
self.name: str = name
def __repr__(self):
return f"Person '{self.name}'"
def __str__(self):
return f"{self.name}"
def say_hi(self):
print("Hi, my name is", self.name)
p = Person("Charlie")
p.say_hi()
print(repr(p))
print(str(p))
Hi, my name is Charlie
Person 'Charlie'
Charlie
@property
import math
class Circle:
def __init__(self, radius, max_radius):
self._radius = radius
self.max_radius = max_radius
@property
def radius(self):
return self._radius
@radius.setter
def radius(self, value):
if value <= self.max_radius:
self._radius = value
else:
raise ValueError
@property
def area(self):
return 2 * self.radius * math.pi
circle = Circle(10, 100)
circle.radius = 20 # OK
# circle.radius = 101 # Raises ValueError
print(circle.area)
125.66370614359172
@staticmethod
@classmethod, cls, self
class B(object):
def foo(self, x):
print(f"Run foo({self}, {x})")
@classmethod
def class_foo(cls, x):
print(f"Run class_foo({cls}, {x})")
@staticmethod
def static_foo(x):
print(f"Run static_foo({x})")
b = B()
b.foo
b.class_foo
b.static_foo
Run foo(<__main__.B object at 0x000001A1FFF3A980>, 1)
Run class_foo(<class '__main__.B'>, 1)
Run static_foo
__dict__
Каждый класс и каждый объект имеет атрибут __dict__. Это «системный», определённый интерпретатором атрибут, его не нужно создавать вручную. __dict__ — словарь, который хранит пользовательские атрибуты, и в котором ключом является имя атрибута
, значением, соответственно, значение атрибута
.
class Supercriminal:
publisher = 'DC Comics'
Riddler = Supercriminal()
print(Supercriminal.__dict__)
print(Riddler.__dict__)
Riddler.name = 'Edward Nygma'
print(Riddler.__dict__) # Values from object __dict__
print(Riddler.publisher) # Value from class __dict__
{'__module__': '__main__', 'publisher': 'DC Comics', '__dict__': <attribute '__dict__' of 'Supercriminal' objects>, '__weakref__': <attribute '__weakref__' of 'Supercriminal' objects>, '__doc__': None}
{}
{'name': 'Edward Nygma'}
DC Comics
Каждый раз при запросе пользовательского атрибута Python последовательно обыскивает сам объект, класс объекта и классы, от которых унасаледован класс объекта.
__slots__
Если вы припомните разницу между списком и кортежем, а также между множеством и иимутабельным множеством, то заметите, что создатели Python пытаются предоставлять разработчикам выбор между удобством и скоростью (тут Си с ассемблерными вставками слегка напрягается, но потом опадает, как будто хотел что-то сказать, но благоразумно передумал). К списку таких же особенностей языка, заточенных на увеличение производительности и уменьшение занимаемой памяти, относится и __slots__.
Вот официальная документация
по __slots__, а вот дополнительные разъяснения
от одного из разработчиков официальной документации. При выборе «slots или не slots» не забывайте также про существование PEP 412 – Key-Sharing Dictionary
, который внёс некоторый раздрай в некогда однозначное отношение к __slots__.
__dict__, рассмотренный чуть выше – изменяемая структура, и вы можете на лету добавлять и удалять поля из класса, что удобно, но порой медленно. Вы можете разменять удобство на скорость и размер занимаемой памяти, создав __slots__ — жестко заданный список предопределенных атрибутов, резервирующий память, создание которого запрещает дальнейшее создание __dict__ и __weakref__
. Слоты можно использовать, когда у класса может быть очень много полей, например, в ORM, либо когда критична производительность, потому что доступ к списку работает быстрее, чем поиск в словаре.
class Clan:
__slots__ = ["first", "second"]
clan = Clan()
clan.first = "Joker"
clan.second = "Lex Luthor"
# clan.third = "Green Goblin" # Raises AttributeError
# print(clan.__dict__) # Raises AttributeError
Наследование __slots__ имеет определенную специфику и будет рассмотрено ниже.
Чтобы было понятно, о каком приросте производительности и снижении потребления памяти идёт речь, сделаем простое сравнение:
import timeit
import pympler.asizeof # В нашем случае sys.getsizeof - не лучший вариант, берем стороннее решение
class NotSlotted():
pass
class Slotted():
__slots__ = 'foo'
not_slotted = NotSlotted()
slotted = Slotted()
def get_set_delete_fn(obj):
def get_set_delete():
obj.foo = "Never Ending Song of Love"
del obj.foo
return get_set_delete
ns = min(timeit.repeat(get_set_delete_fn(not_slotted)))
s = min((timeit.repeat(get_set_delete_fn(slotted))))
print(ns, s, f'{(ns - s) / s * 100} %')
print(pympler.asizeof.asizeof(not_slotted), 'bytes')
print(pympler.asizeof.asizeof(slotted), 'bytes')
0.10838449979200959 0.08712740009650588 24.39772066187959 %
280 bytes
40 bytes
Я в Python 3.10 в Windows вижу 24 % разницы.
На всякий случай напоминаю еще раз — прогняйте все непонятные примеры кода в IDE, их можно и нужно анализировать, корректировать и видоизменять. Попробуйте, например, самостоятельно посмотреть потребление памяти объектов с __dict__ и __slots__. А заодно на практике испытайте давно напрашивающийся, и наконец появившийся в Python 3.10 симбиоз
между __slots__ и dataclass.
Утиная типизация
Утиная типизация
(duck types) — постулирование реализации интерфейса классом не через явное объявление, а через реализацию методов интерфейса. Так, каждый класс, реализующий методы __next__() и __iter__(), автоматически становится итератором, несмотря на отсутствие явного объявления (что-нибудь вроде iterator
) или, скажем, наследования от класса Iterator.
Iterator
Итератор — класс, реализующий методы __next__() и __iter__().
Метод __next__() должен возвращать следующее значение итератора или выкидывать исключение StopIteration, чтобы сигнализировать о том, что итератор исчерпал доступные значения.
Метод __iter__() должен возвращать «self».
class LimitCounter:
def __init__(self, max_value: int):
self.count = 0
self.max_value = max_value
def __next__(self):
self.count += 1
if self.count <= self.max_value:
return self.count
else:
raise StopIteration
def __iter__(self):
return self
limit_counter = LimitCounter
print(next(limit_counter))
print(next(limit_counter))
# print(next(limit_counter)) # Raises StopIteration
1
2
Comparable
from functools import total_ordering
@total_ordering
class Person:
def __init__(self, firstname: str, lastname: str):
self.firstname: str = firstname
self.lastname: str = lastname
def _is_valid_operand(self, other):
return hasattr(other, "lastname") and hasattr(other, "firstname")
def __eq__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return (self.lastname, self.firstname) == (other.lastname, other.firstname)
def __lt__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return (self.lastname, self.firstname) < (other.lastname, other.firstname)
Finn = Person("Finn", "the Human")
Jake = Person("Jake", "the Dog")
print(Finn != Jake)
True
Hashable
Хешируемые объекты должны реализовывать методы __hash__() и __eq__(). Хеш объекта должен быть неизменен в течении всего жизненного цикла. Хешируемые объекты можно использовать как ключи в словарях и как элементы множеств, так как эти структуры используют хеш-таблицу для внутреннего представления данных.
Hashable objects that compare equal must have the same hash value, meaning default hash() that returns 'id(self)'
will not do. That is why Python automatically makes classes unhashable if you only implement eq().
class Hero:
def __init__(self, name: str, level: int):
self.name: str = name
self.level: int = level
def _is_valid_operand(self, other):
return hasattr(other, "name") and hasattr(other, "level")
def __eq__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return (self.name, self.level) == (other.name, other.level)
def __hash__(self):
return hash((self.name, self.level))
Finn = Hero("Finn the Human", 10_000)
Jake = Hero("Jake the Dog", 10_000)
print(hash(Finn))
print(hash(Jake))
-8707075988359731747
-2276052447712954388
Sortable
Для более предсказумого поведения объекта в условиях различного контекста вы можете определить полное множество функций сравнения (__lt()__, __gt()__, __le__() и __ge__()).
Для примера создадим класс студентов, которых можно будет сортировать не по имени, а по среднему баллу.
from functools import total_ordering
from statistics import mean
@total_ordering
class Student:
def __init__(self, name: str, grades: list[int]):
self.name: str = name
self.grades: list[int] = grades
def _is_valid_operand(self, other):
return hasattr(other, "name") and hasattr(other, "grades")
def __eq__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return mean(self.grades) == mean(other.grades)
def __lt__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return mean(self.grades) < mean(other.grades)
# определим str для человеко-читаемой репрезентации объекта
def __str__(self):
return self.name + " " + str(mean(self.grades))
Melissa = Student("Melissa Andrew", [4, 3, 4, 5, 4])
Peter = Student("Peter Shining Jr.", [3, 3, 4, 5, 3])
Joe = Student("Just Joe", [5, 5, 4, 5, 5])
print([str(stud) for stud in sorted([Peter, Melissa, Joe], reverse=True)])
['Just Joe 4.8', 'Melissa Andrew 4', 'Peter Shining Jr. 3.6']
Callable
Для возможности вызова объекта в качестве функции необходимо реализовать метод __call__. Типы, поддерживающие возможность их вызова в качестве функции, могут принимать набор аргументов.
class Counter:
def __init__(self):
self.i = 0
def __call__(self):
self.i += 1
return self.i
counter = Counter()
print(counter())
print(counter())
print(counter())
1
2
3
class Check():
@classmethod
def class_method(cls):
pass
@staticmethod
def static_method():
pass
def instance_method(self):
pass
for attr, val in vars(Check).items():
if not attr.startswith("__"):
print (attr, f"{'is' if callable(val) else 'is NOT'} callable")
class_method is NOT callable
static_method is callable
instance_method is callable
Контекстные менеджеры, описанные в предыдущей главе, тоже, как мы теперь видим, определяются через утиную типизацию при помощи методов __enter__ и __exit__.
Утиная типизация итерируемых объектов
Iterable
Iterable
— объект, который для предоставления возможности поочерёдного прохода по всем своим элементам должен реализовывать метод __iter__(), возвращающий итератор. У каждого объекта с методом __iter__() автоматически начинает работать метод __contains__().
class MyIterable:
def __init__(self, *args):
self.a = list(args)
def __iter__(self):
return iter(self.a)
mi = MyIterable(1, 2, 3, 4)
print([el for el in mi])
print(1 in mi) # __contains__()
[1, 2, 3, 4]
True
Collection
Collection
— объект, предоставляющий возможность поочерёдного прохода по всем своим элементам и обладающий конечным размером.
В дополнение к iter() должен быть реализован метод len(), возвращающий размер коллекции.
class MyCollection:
def __init__(self, *args):
self.a = list(args)
def __iter__(self):
return iter(self.a)
def __len__(self):
return len(self.a)
mc = MyCollection(1, 2, 3, 4)
print([el for el in mc])
print(1 in mc)
print(len(mc))
[1, 2, 3, 4]
True
4
Sequence
Требует методы len() and getitem(). getitem() должен отдавать элемент с требуемым индексом или вызывать исключение IndexError.
Автоматически будут порождены методы iter(), reversed() и contains().
class MySequence:
def __init__(self, a):
self.a = a
def __len__(self):
return len(self.a)
def __getitem__(self, i):
return self.a[i]
ABC Sequence
Коллекция Sequence из Abstract Base Classes for Containers
предоставляет расширенный интерфейс по сравнению с обычной Sequence.
Всё так же требуя __getitem__ и __len__, предоставляет __contains_ , __iter__, __reversed_\
, index и count.
from collections import abc
class MyAbcSequence(abc.Sequence):
def __init__(self, a):
self.a = a
def __len__(self):
return len(self.a)
def __getitem__(self, i):
return self.a[i]
Таблица требуемых и доступных методов:
+------------+------------+------------+------------+--------------+
| | Iterable | Collection | Sequence | ABC Sequence |
+------------+------------+------------+------------+--------------+
| iter() | нужен | нужен | + | + |
| contains() | + | + | + | + |
| len() | | нужен | нужен | нужен |
| getitem() | | | нужен | нужен |
| reversed() | | | + | + |
| index() | | | | + |
| count() | | | | + |
+------------+------------+------------+------------+--------------+
И вообще, потщательнее присмотритесь с collections.abc, там есть множество заготовок, которые помогут вам сэкономить немало времени. Например, если к упомянутым относительно ABC Sequence __getitem__ и __len__ добавить __setitem__, __delitem__ и insert, то в ответ вы получите коллекцию MutableSequence, которая, кроме возможностей Sequence, имеет еще методы append, reverse, extend, pop, remove и __iadd__.
Копирование объектов
В Python оператор присваивания (=) не копирует объекты. Вместо этого он создает связь между существующим объектом и именем целевой переменной. Чтобы создать копии объекта в Python, необходимо использовать модуль copy. Более того, существует два способа создания копий для данного объекта с помощью модуля copy.
Shallow Copy – это побитовая копия объекта. Созданный скопированный объект имеет точную копию значений в исходном объекте. Если одно из значений является ссылкой на другие объекты, копируются только адреса ссылок на них.
Deep Copy – рекурсивно копирует все значения от исходного объекта к целевому, т. е. дублирует даже объекты, на которые ссылается исходный объект.
from copy import copy, deepcopy
class A:
def __init__(self, val: list):
self.val = val
def change_val(self, val: list):
self.val = val
a = A(list("one"))
# Просто копирование ссылки на объект
b = a # Assignment
# Создание нового объекта и копирование ссылок на объекты, найденные в изначальном объекте
c = copy(a) # Shallow copy
# Создание нового объекта с последующим рекурсивным копированием содержащихся внутри объектов
d = deepcopy(a) # Deep Copy
b.change_val(list("two"))
c.change_val(list("three"))
d.change_val(list("four"))
print(a.val, b.val, c.val, d.val)
print(id(a), id(b), id(c), id(d))
print(id(a.val[1]), id(c.val[1]))
['t', 'w', 'o'] ['t', 'w', 'o'] ['t', 'h', 'r', 'e', 'e'] ['f', 'o', 'u', 'r']
1795295519472 1795295519472 1793149281968 1793149273808
1795217224688 1795217321264
Наследование
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
class Employee(Person):
def __init__(self, name, age, staff_num, email):
super().__init__(name, age)
self.staff_num = staff_num
self.email = email
Множественное наследование
При множественном наследовании порядок разрешения методов (method resolution order, MRO) позволяет Питону выяснить, из какого класса-предка нужно вызывать метод, если он не обнаружен непосредственно в классе-потомке.
class PrivateStaffData:
def __init__(self, private_email):
self.private_email = private_email
class PublicStaffData:
def __init__(self, work_email):
self.work_email = work_email
class StaffData(PrivateStaffData, PublicStaffData):
def __init__(self, private_email, work_email):
super().__init__()
print(StaffData.mro())
[<class '__main__.StaffData'>, <class '__main__.PrivateStaffData'>, <class '__main__.PublicStaffData'>, <class 'object'>]
MRO строит иерархию наследования таким образом, чтобы более специфичные методы класса-потомка перекрывали менее специфичные методы класса-предка. M RO строит упорядоченный список классов, в которых будет производиться поиск метода слева направо (линеаризация класса).
Для решения проблемы ромбовидной структуры (которая неявно присутствует даже в простейшем случае, так как все классы наследуются от object) линеаризация должна быть монотонной. Монотонность — свойство, которое требует соблюдения в линеаризации класса-потомка того же порядка следования классов-прародителей, что и в линеаризации класса-родителя. Линеаризация по сути является топологической сортировкой
. В ранних версиях Python использовался алгоритм DLR, сейчас в ходу C3-линеаризация
.
Если после удовлетворения свойства монотонности остаётся больше одного варианта линеаризации, то применяется порядок локального старшинства (local precedence ordering), т. е. порядок соблюдения для классов-родителей в линеаризации класса-потомка того же порядка, что и при его объявлении. Например, если класс объявлен как D(A, B, C), то в линеаризации D класс A должен стоять раньше B, а класс B — раньше C.
Если разрешение всех конфликтов при линеаризации невозможно, то остается три пути:
1 — переменой мест классов-предков в объявлении класса-потомка (но это помогает далеко не всегда);
2 — пересмотр иерархии наследования;
3 — определение своей собственной линеаризации через метаклассы при помощи метода mro(cls). Но при данном подходе надо быть готовым к тому, что будет использован менее специфичный метод класса-родителя вместо более специфичного метода класса-потомка.
При задании своей собственной линеаризации Python отключает встроенные проверки.
Наследование классов со __slots__
При одиночном наследовании __slots__ нормально наследуется, но это не предотвращает создание __dict__:
class SlotsClass:
__slots__ = 'foo', 'bar'
class ChildSlotsClass(SlotsClass):
...
obj = ChildSlotsClass()
print(obj.__slots__)
obj.something_new = "underwater stones"
print(obj.__dict__)
('foo', 'bar')
{'something_new': 'underwater stones'}
Для ограничения дочернего класса слотами нужно в нём снова присвоить значение атрибуту __slots__, родительские поля дублировать не нужно.
class SlotsClass:
__slots__ = 'foo', 'bar'
class ChildSlotsClass(SlotsClass):
__slots__ = 'baz'
obj = ChildSlotsClass()
# obj.something_new = "underwater stones" # Raises AttributeError: 'ChildSlotsClass' object has no attribute 'something_new'
Множественное же наследование классов с непустыми
__slots__ невозможно.
Метапрограммирование
Что такое класс? Это, в принципе, просто кусок кода, описывающий, как создать объект. Но в Python класс — это нечто большее, классы также являются объектами; как только используется ключевое слово class, Python исполняет команду и создаёт объект:
class A:
...
В памяти будет создан объект с именем A.
Классы, как и другие объекты, можно создавать на ходу:
def custom_class(name):
if name == "foo":
class Foo:
...
return Foo # Возвращает именно класс, а не экземпляр
else:
class Bar:
...
return Bar
MyClass = custom_class("foo")
print(MyClass) # Функция возвращает класс, а не экземпляр
print(my_class := MyClass()) # Можно создать экземпляр класса
<class '__main__.custom_class.<locals>.Foo'>
<__main__.custom_class.<locals>.Foo object at 0x000001F0ECF97610>
Но это не очень удобно, так как нам до сих пор приходится писать весь код класса.
Основная цель метаклассов — автоматически изменять класс в момент создания, генерируя классы в соответствии с текущим контекстом.
Сами по себе метаклассы достаточно просты и работают примерно следующим образом:
перехватывают создание класса,
изменяют класс,
возвращают модифицированный класс.
Но обычно логику работы метаклассов насыщают вещами вроде интроспекции
или манипуляцией наследованием, поэтому конечный код выглядит достаточно громоздко.
Здесь неплохо было бы добавить еще пару страниц про ньюансы создания и работы метаклассов, но позвольте переадресовать вас на вот эту прекрасную статью
.
При помощи метаклассов хорошо решаются задачи, например, генерации классов для ORM. Скажем, для
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
keanu = Person(name="Keanu Reeves", age=58)
print(keanu.age)
распечатает число, взятое из БД, потому что models. Model определяет __metaclass__, который сотворит некоторую магию и превратит класс Person, который мы только что определили достаточно простым выражением, в сложную привязку к базе данных.
@abstractmethod
Абстрактный класс в Python — аналог интерфейса в других языках (например, в C#) — класс, содержащий только сигнатуры методов, без реализации. Реализация методов переложена на классы-потомки. Задача абстрактного класса соответствует задаче интерфейса — обязать
классы-потомки реализовывать все
методы, заложенные в классе-родителе.
import abc
class AbstractClass(metaclass=abc.ABCMeta):
@abc.abstractmethod
def return_anything(self):
return
class ConcreteClass(AbstractClass):
def return_anything(self):
return 42
c = ConcreteClass()
print(c.return_anything())
42
Если не специфицировать return_anything() в ConcreteClass, при попытке вызвать c.return_anything() будет выброшено исключение TypeError: Can’t instantiate abstract class ConcreteClass with abstract method return_anything.
Структуры данных
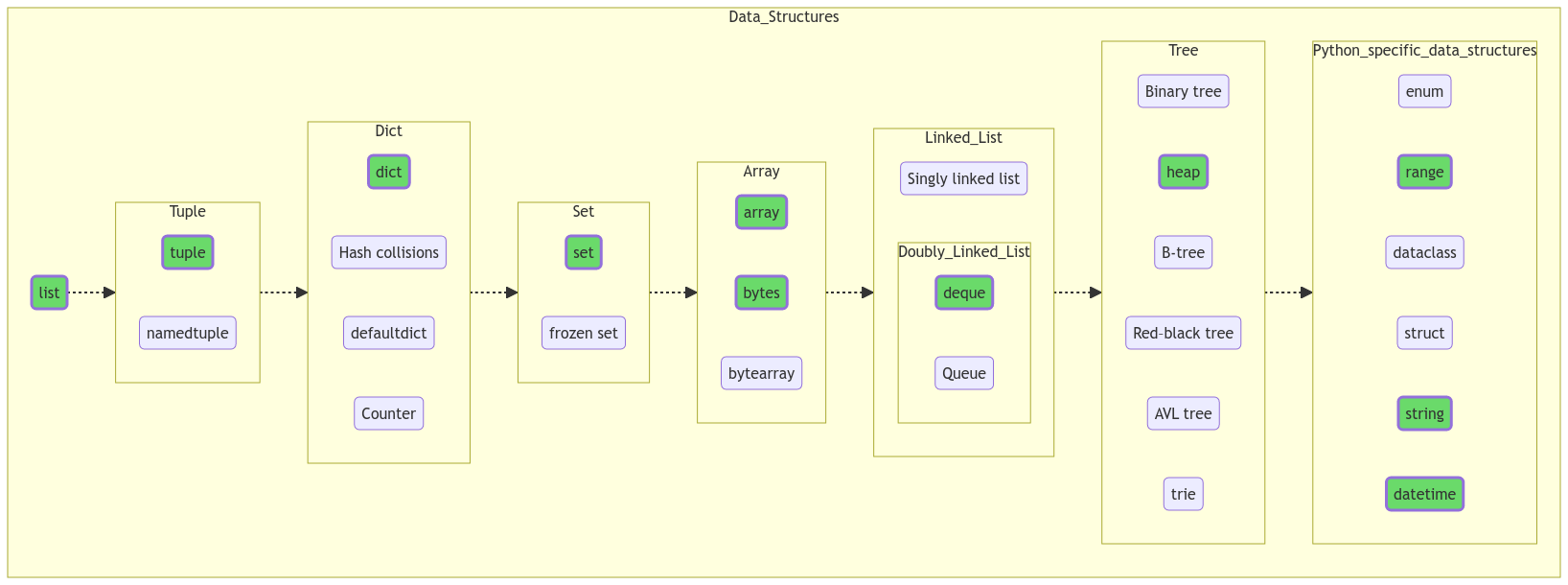
Как известно, программирование = структуры данных + алгоритмы (у Никлауса Вирта даже книжка такая есть). Начнем с данных, а потом плавненько перейдем к методам их обработки.
Список (list)
Список — самая универсальная и популярная структура данных в Python. Если вы пока точно не определились, какая структура понадобится в вашем проекте, просто возьмите список, с него достаточно просто мигрировать на что-нибудь более специализированное.
Список представляет собой упорядоченную изменяемую коллекцию объектов произвольных типов. Внутреннее строение списка — массив (точнее, vector) указателей, т. е. список является динамическим массивом.
a = [] # Создаем пустой список
a: list[int] = [10, 20]
b: list[int] = [30, 40]
a.append # Добавляем значение в конец списка
b.insert(2, 60) # Вставляем значение по определенному индексу
print(a, b)
a += b
print(f"Add: {a}")
a.reverse()
b = list(reversed(a)) # reversed() возвращает итератор, а не список
print(f"Reverse: {a}, {b}")
b = sorted(a) # Возвращает новый отсортированный список
a.sort() # Модифицирует исходный список и не возвращает ничего
print(f"Sort: {a}, {b}")
s: str = "A whole string"
list_of_chars: list = list(s)
print(list_of_chars)
list_of_words: list = s.split()
print(list_of_words)
i: int = list_of_chars.index("w") # Возвращает индекс первого вхождения искомого элемента или вызывает исключение ValueError
print(i)
list_of_chars.remove("w") # Удаляет первое вхождение искомого элемента или вызывает исключение ValueError
e = list_of_chars.pop # Удаляет и возвращает значение, расположенное по индексу. pop() (без аргумента) удалит и вернет последний элемент списка
print(list_of_chars, e)
a.clear() # Очистка списка
[10, 20, 50] [30, 40, 60]
Add: [10, 20, 50, 30, 40, 60]
Reverse: [60, 40, 30, 50, 20, 10], [10, 20, 50, 30, 40, 60]
Sort: [10, 20, 30, 40, 50, 60], [10, 20, 30, 40, 50, 60]
['A', ' ', 'w', 'h', 'o', 'l', 'e', ' ', 's', 't', 'r', 'i', 'n', 'g']
['A', 'whole', 'string']
2
['A', ' ', 'h', 'o', 'l', 'e', ' ', 's', 't', 'i', 'n', 'g'] r
Кортеж (tuple)
Кортеж — тоже список, только неизменяемый (immutable) и хэшируемый (hashable). Кортеж, содержащий те же данные, что и список, занимает меньше места:
a = [2, 3, "Boson", "Higgs", 1.56e-22]
b = (2, 3, "Boson", "Higgs", 1.56e-22)
print(f"List: {a.__sizeof__()} bytes")
print(f"Tuple: {b.__sizeof__()} bytes")
List: 104 bytes
Tuple: 64 bytes
Именованный кортеж (named tuple)
В соответствии с названием, имеет именованные поля. Удобно!
from collections import namedtuple
rectangle = namedtuple('rectangle', 'length width')
r = rectangle(length = 1, width = 2)
print(r)
print(r.length)
print(r.width)
print(r._fields)
rectangle(length=1, width=2)
1
2
('length', 'width')
Словарь (dict)
Словарь — вторая по частоте использования структура данных в Python. dict — реализация хеш-таблицы, поэтому в качестве ключа нельзя брать нехешируемый объект, например, список (тут-то нам и может пригодиться кортеж). Ключом словаря может быть любой неизменяемый объект: число, строка, datetime и даже функция. Такие объекты имеют метод __hash__()
, который однозначно сопоставляет объект с некоторым числом. По этому числу словарь ищет значение для ключа.
Списки, словари и множества (которые мы рассмотрим чуть ниже) изменяемы и не имеют метода хеширования, при попытке подставить их в словарь возникнет ошибка.
d = {} # Создаем пустой словарь
d: dict[str, str] = {"Italy": "Pizza", "US": "Hot-Dog", "China": "Dim Sum"} # Непосредственное создание словаря
k = ["Italy", "US", "China"]
v = ["Pizza", "Hot-Dog", "Dim Sum"]
d = dict(zip(k, v)) # Создание словаря из двух коллекций при помощи zip
k = d.keys() # Коллекция ключей. Отражает изменения в основном словаре
v = d.values() # Коллекция значений. Тоже отражает изменения в основном словаре
k_v = d.items() # Кортежи ключ-значение, которые тоже отражают изменения в основном словаре
print(d)
print(k)
print(v)
print(k_v)
print(f"Mapping: {k.mapping['Italy']}")
d.update({"China": "Dumplings"}) # Добавление значение. При совпадении ключа старое значение будет перезаписано
print(f"Replace item: {d}")
c = d["China"] # Читаем значение
print(f"Read item: {c}")
try:
v = d.pop("Spain") # Удаляет значение или вызывает исключение KeyError
except KeyError:
print("Dictionary key doesn't exist")
# Примеры dict comprehension (более подробно comprehension будет рассмотрено ниже)
b = {k: v for k, v in d.items() if "a" in k} # Вернет новый словарь, отфильтрованный по значению ключа
print(b)
c = {k: v for k, v in d.items() if len(v) >= 7} # Вернет новый словарь, отфильтрованный по длине значений
print(c)
d.clear() # Очистка словаря
{'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dim Sum'}
dict_keys(['Italy', 'US', 'China'])
dict_values(['Pizza', 'Hot-Dog', 'Dim Sum'])
dict_items([('Italy', 'Pizza'), ('US', 'Hot-Dog'), ('China', 'Dim Sum')])
Mapping: Pizza
Replace item: {'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dumplings'}
Read item: Dumplings
Dictionary key doesn't exist
{'Italy': 'Pizza', 'China': 'Dumplings'}
{'US': 'Hot-Dog', 'China': 'Dumplings'}
Решение проблемы вычисления хеша при работе со словарем
Любая хеш-таблица, в том числе и питоновский словарь, должна уметь решать проблему вычисления хеша. Для этого используются техники open addressing
или chaining
. Python использует
open addressing.
Новый словарь инициализируется с 8 пустыми слотами.
Интерпретатор сначала пытается добавить новую запись по адресу, зависящему от хеша ключа.
addr = hash(key) & mask,
mask = PyDictMINSIZE - 1
Если этот адрес занят, то интерпретатор проверяет (при помощи ==) хеш и ключ. Если оба совпадают, то, значит, запись уже существует. Тогда начинается зондирование свободных слотов, которое идет в псевдослучайном порядке (порядок зависит от значения ключа). Новая запись будет добавлена по первому свободному адресу.
Чтение из словаря происходит аналогично, интерпретатор начинает поиск с позиции addr и идет по тому же псевдослучайному пути, пока не прочитает нужную запись.
Defaultdict
Если попытаться прочитать из обычного словаря значение ключа, которого там нет, то будет выброшено исключение KeyError (исключения будут рассмотрены ниже). Defaultdict позволяет не писать обработчик исключений, а просто воспринимает чтение несуществующего ключа как команду записать в этот ключ и вернуть значение по умолчанию; например, defaultdict(int) вернет 0.
from collections import defaultdict
dd = defaultdict(int)
print(dd[10]) # Печать int, будет выведен ноль, значение по умолчанию
dd = {} # "Обычный" пустой словарь
# print(dd[10]) # вызовет исключение KeyError
0
Счетчик (counter)
Счетчик подсчитывает передаваемые ему объекты. Иногда очень удобно просто бухнуть в счетчик какой-нибудь список и сразу получить структуру данных с подсчитанными элементами.
from collections import Counter
shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"]
c = Counter(shirts_colors)
print(c)
c["blue"] += 1
print(f"After shopping: {c}")
Counter({'white': 3, 'black': 2, 'red': 1, 'blue': 1})
After shopping: Counter({'white': 3, 'blue': 2, 'black': 2, 'red': 1})
Объяснение работы Counter() при помощи defaultdict():
from collections import defaultdict
shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"]
d = defaultdict(int)
for shirt in shirts_colors:
d[shirt] += 1
print(d)
defaultdict(<class 'int'>, {'red': 1, 'white': 3, 'blue': 1, 'black': 2})
Множество (set)
Третья по распространенности питоновская структура данных. Когда-то, когда Python был молод, множества представляли собой несколько редуцированные словари, но со временем их судьбы (и реализации) стали расходиться. Однако, множество всё-таки является хеш-таблицей с соответствующим быстродействием на разных типах операций.
big_cities: set["str"] = {"New-York", "Los Angeles", "Ottawa"}
american_cities: set["str"] = {"Chicago", "New-York", "Los Angeles"}
big_cities |= {"Sydney"} # Добавить значение (или add())
american_cities |= {"Salt Lake City", "Seattle"} # Сложить множества (или update())
print(big_cities, american_cities)
union_cities: set["str"] = big_cities | american_cities # Или union()
intersected_cities: set["str"] = big_cities & american_cities # Или intersection()
dif_cities: set["str"] = big_cities - american_cities # Или difference()
symdif_cities: set["str"] = big_cities ^ american_cities # Или symmetric_difference()
issub: bool = big_cities <= union_cities # Или issubset()
issuper: bool = american_cities >= dif_cities # Или issuperset()
print(union_cities)
print(intersected_cities)
print(dif_cities)
print(symdif_cities)
print(issub, issuper)
big_cities.add("London")
big_cities.remove("Ottawa") # Удаляет значение, если оно имеется или выбрасывает KeyError
big_cities.discard("Los Angeles") # Удаляет значение без выбрасывания KeyError
big_cities.pop() # Возвращает и удаляет случайное значение (порядок в set неопределен) или выбрасывает KeyError
big_cities.clear() # Очищает множество
{'New-York', 'Los Angeles', 'Sydney', 'Ottawa'} {'New-York', 'Seattle', 'Chicago', 'Los Angeles', 'Salt Lake City'}
{'Ottawa', 'Salt Lake City', 'Chicago', 'New-York', 'Seattle', 'Sydney', 'Los Angeles'}
{'New-York', 'Los Angeles'}
{'Ottawa', 'Sydney'}
{'Seattle', 'Ottawa', 'Chicago', 'Salt Lake City', 'Sydney'}
True False
Иммутабельное множество (frozen set)
Frozen set — то же множество, только иммутабельное и хешируемое. Напоминает разницу между списком и кортежем, не правда ли?
a = frozenset({"New-York", "Los Angeles", "Ottawa"})
Массив (array, bytes, bytearray)
Я перешел на Python с языков, более приближенных к «железу» (C, C#, даже на ассемблере когда-то писал за деньги 🙂 и сначала немного удивлялся, что обычный массив, в котором всё так удобно лежит на своих местах, используется относительно редко. Массив в Python не является структурой данных, выбираемой по умолчанию и используется только в случаях, когда решающую роль начинают играть размер структуры и скорость её обработки. Но, с другой стороны, если вы смотрите в сторону NumPy и Pandas (немного затронуты ниже), то массивы — ваше всё.
Массив хранит переменные определенного типа, поэтому, в отличие от списка, не требует создания нового объекта для каждой новой переменной и выигрывает у списка в размерах и скорости доступа. Можно сказать, что это тонкая обёртка над Си-массивами.
Следует различать array («просто» массив), bytes (иммутабельный массив, содержащий только байты, наследие str из Python 2) и bytearray (мутабельный байтовый массив).
from array import array
a1 = array("l", [1, 2, 3, -4])
a2 = array("b", b"1234567890")
b = bytes(a2)
print(a1)
print(a2[0])
print(b)
print(a1.index(-4)) # Возвращает индекс элементы или выбрасывает ValueError
array('l', [1, 2, 3, -4])
49
b'1234567890'
3
# Создание
b1 = bytes([1, 2, 3, 4]) # Целые числа должны быть в диапазоне от 0 to 255
b2 = "The String".encode('utf-8')
b3 = (-1024).to_bytes(4, byteorder='big', signed=True) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True
b4 = bytes.fromhex('FEADCA') # Для большей читаемости hex-значения могут быть разделены пробелами
b5 = bytes(range(10,30,2))
print(b1, b2, b3, b4, b5)
# Преобразование
c: list = list(b"\xfc\x00\x00\x00\x00\x01")
s: str = b'The String'.decode("utf-8")
b: int = int.from_bytes(b"\xfc\x00", byteorder='big', signed=False) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True
s2: str = b"\xfc\x00\x00\x00\x00\x01".hex(" ")
print(c, s, b, s2)
with open("1.bin", "wb") as file: # Байтовая запись в файл
file.write(b1)
with open("1.bin", "rb") as file: # Чтение из файла
b6 = file.read()
print(b6)
b'\x01\x02\x03\x04' b'The String' b'\xff\xff\xfc\x00' b'\xfe\xad\xca' b'\n\x0c\x0e\x10\x12\x14\x16\x18\x1a\x1c'
[252, 0, 0, 0, 0, 1] The String 64512 fc 00 00 00 00 01
b'\x01\x02\x03\x04'
Односвязный список
Односвязный список
представляет набор связанных узлов, каждый из которых хранит собственные данные и ссылку на следующий узел. В практике применим редко, но его любят использовать интервьюеры на собеседованиях, чтобы кандидат мог блеснуть своими алгоритмическими знаниями. В Python встроенной реализации не имеет, можно или использовать deque (в основе которого лежит двусвязный список), или написать свою реализацию.
Двусвязный список (Deque)
Ссылки в каждом узле двусвязного списка
указывают на предыдущий и на последующий узел в списке. Можно или использовать deque, или написать свою реализацию.
from collections import deque
d = deque([1, 2, 3, 4], maxlen=1000)
d.appendaddr = hash(key) & mask, # Add element to the right side of the deque
d.appendleft(0) # Add element to the left side of the deque by appending elements from iterable
d.extend([6, 7]) # Extend the right side of the deque
d.extendleft([-1, -2]) # Extend the left side of the deque
print(d)
a = d.pop() # Remove and return an element from the right side of the deque. Can raise an IndexError
b = d.popleft() # Remove and return an element from the left side of the deque. Can raise an IndexError
print(a, b)
print(d)
deque([-2, -1, 0, 1, 2, 3, 4, 5, 6, 7], maxlen=1000)
7 -2
deque([-1, 0, 1, 2, 3, 4, 5, 6], maxlen=1000)
Queue
Queue реализует FIFO со множественными поставщиками данных и множественными потребителями. Может быть особенно полезен при многопоточности, позволяя корректно обмениваться информацией между потоками. Также существуют LifoQueue для реализации LIFO и PriorityQueue для реализации очереди с приоритетом.
from queue import Queue
q = Queue(maxsize=1000)
q.put("eat", block=True, timeout=10)
q.put("sleep") # По умолчанию block=True, timeout=None
q.put("code")
q.put_nowait("repeat") # Эквивалент put("repeat", block=False). Если свободный слот не будет предоставлен немедленно, будет вызвано исключение queue.Full
print(q.queue)
a = q.get(block=True, timeout=10) # Удалить и возвратить элемент из FIFO
b = q.get() # По умолчанию block=True, timeout=None
c = q.get_nowait() # Эквивалент get(False)
print(a, b, c, q.queue)
deque(['eat', 'sleep', 'code', 'repeat'])
eat sleep code deque(['repeat'])
Бинарное дерево (binary tree)
Иерархическая структура данных, в которой каждый узел имеет не более двух потомков. Встроенной реализации не имеет, нужно писать свою. Как правило, используются деревья с дополнительными свойствами, рассмотренные ниже.
Куча (heap)
Бинарное дерево, удовлетворяющее свойство кучи: если B является узлом-потомком узла A, то ключ(A) ≥ ключ(B). Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом и поддерживающего две обязательные операции — добавить элемент и извлечь минимум (или максимум, в зависимости от реализации).
В Python min-куча (наименьшее значение всегда лежит в корне) реализована на базе списка при помощи встроенного модуля heapq. Если вам нужна max-куча, с максимальным значением в корне, можете воспользоваться советами со Stackoverflow
.
import heapq
h = [211, 1, 43, 79, 12, 5, -10, 0]
heapq.heapify(h) # Превращаем список в кучу
print(h)
heapq.heappush(h, 2) # Добавляем элемент
print(h)
m = heapq.heappop(h) # Извлекаем минимальный элемент
print(h, m)
[-10, 0, 5, 1, 12, 211, 43, 79]
[-10, 0, 5, 1, 12, 211, 43, 79, 2]
[0, 1, 5, 2, 12, 211, 43, 79] -10
Пробежимся коротенько по остальным структурам данных, которые в Python не имеют встроенной реализации, но, тем не менее, могут весьма пригодиться в реальном проекте.
Би-дерево (B-tree)
Сбалансированное дерево, оптимизированное для доступа к относительно медленным элементам памяти (например, дисковым структурам или индексам баз данных); как ветви, так и листья представляют собой списки (для того, чтобы можно было считать такой список в один проход для дальнейшего быстрого разбора в ОЗУ). Нужно писать свою реализацию. Либо — воспользоваться встроенной в Python поддержкой базы данных sqlite3, эта БД как раз реализована на би-дереве.
Красно-черное дерево
Самобалансирующееся двоичное дерево поиска, позволяющее быстро выполнять основные операции: добавление, удаление и поиск узла. Сбалансированность достигается за счёт введения дополнительного признака узла дерева — «цвета». Этот атрибут может принимать одно из двух возможных значений — «чёрный» или «красный». Листовые узлы КЧ деревьев не содержат данных, поэтому не требуют выделения памяти — достаточно просто записать в узле-предке нулевой указатель на потомка. Нужно писать свою реализацию.
Возможно, вы читали о том, что при собеседовании в FAANG претендентов «заставляют крутить красно-черное дерево на доске». Это «кружение» и есть балансировка, после операции вставки или удаления элемента дерево нужно отбалансировать, с примерным объемом кода вы можете ознакомиться здесь
или здесь
.
АВЛ-дерево
В АВЛ-деревьях операции вставки и удаления работают медленнее, чем в красно-черных деревьях (при том же количестве листьев красно-чёрное дерево может быть выше АВЛ-дерева, но не более чем в 1,388 раза). Поиск же в АВЛ-дереве выполняется быстрее (максимальная разница в скорости поиска составляет 39 %). Нужно писать свою реализацию.
Префиксное дерево
Префиксное дерево
(или trie) — структура данных, позволяющая хранить ассоциативный массив, ключами которого являются строки. Нужно писать свою реализацию.
Таблица выбора структуры данных
В квадратных скобках показан худший случай.
Перечисление (Enum, IntEnum)
Удобные конструкции для определения заранее известных перечислений.
from enum import Enum, auto
import random
class Currency(Enum):
euro = 1
us_dollar = 2
yuan = auto()
local_currency = Currency.us_dollar
print(local_currency)
local_currency = Currency["us_dollar"] # Может вызвать исключение KeyError
print(local_currency)
local_currency = Currency
# Может вызвать исключение ValueError
print(local_currency)
print(local_currency.name)
print(local_currency.value)
list_of_members = list(Currency)
member_names = [e.name for e in Currency]
member_values = [e.value for e in Currency]
random_member = random.choice(list(Currency))
print(list_of_members, "\n",
member_names, "\n",
member_values, "\n",
random_member)
Currency.us_dollar
Currency.us_dollar
Currency.us_dollar
us_dollar
2
[<Currency.euro: 1>, <Currency.us_dollar: 2>, <Currency.yuan: 3>]
['euro', 'us_dollar', 'yuan']
[1, 2, 3]
Currency.euro
Целочисленный диапазон (range)
range() возвращает иммутабельную последовательность чисел, которая часто используется как задатчик диапазона для цикла for.
r1: range = range
# Возвращает последовательность чисел от 0 до 10
r2: range = range(5, 21) # Возвращает последовательность чисел от 5 до 20
r3: range = range(20, 9, -2) # Возвращает последовательность чисел от 20 до 10 с шагом 2
print("To exclusive: ", end="")
for i in r1:
print(f"{i} ", end="")
print("\nFrom inclusive to exclusive: ", end="")
for i in r2:
print(f"{i} ", end="")
print("\nFrom inclusive to exclusive with step: ", end="")
for i in r3:
print(f"{i} ", end="")
print(f"\nFrom = {r3.start}")
print(f"To = {r3.stop}")
To exclusive: 0 1 2 3 4 5 6 7 8 9 10
From inclusive to exclusive: 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
From inclusive to exclusive with step: 20 18 16 14 12 10
From = 20
To = 9
Классы данных (dataclass)
Декоратор, автоматически создающий методы init(), repr() и eq(). Нужен для создания классов, главной задачей которых является хранение данных. Аннотации типов обязательны. Существует более продвинутая альтернатива под названием attrs
.
from dataclasses import dataclass
from decimal import *
from datetime import datetime
@dataclass
class Transaction:
value: Decimal
issuer: str = "Default Bank"
dt: datetime = datetime.now()
t1 = Transaction(value=1000_000, issuer="Deutsche Bank", dt = datetime(2022, 1, 1, 12))
t2 = Transaction(1000)
print(t1)
print(t2)
Transaction(value=1000000, issuer='Deutsche Bank', dt=datetime.datetime(2022, 1, 1, 12, 0))
Transaction(value=1000, issuer='Default Bank', dt=datetime.datetime(2022, 9, 6, 17, 50, 36, 162897))
Dataclass может быть сделан иммутабельным с директивой frozen=True
.
from dataclasses import dataclass
@dataclass(frozen=True)
class User:
name: str
account: int
Бинарная запаковка (struct)
Запаковка (и распаковка, разумеется) данных в байтовые последовательности с предопределенными размерами каждого элемента данных, их порядка в структуре, а также порядка байт для многобайтовых типов данных. Позволяет превращать Python-овский int в, например, short int или long int ( подробности про систему типов языка Си
).
При работе со структурами вам нужно будет знать, что такое little-endian и big-endian, а также не забывать, что размер типа данных в Си бывает разным.
from struct import pack, unpack, iter_unpack
b = pack(">hhll", 1, 2, 3, 4)
print(b)
t = unpack(">hhll", b)
print(t)
i = pack("ii", 1, 2) * 5
print(i)
print(list(iter_unpack('ii', i)))
b'\x00\x01\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04'
(1, 2, 3, 4)
b'\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00'
[(1, 2), (1, 2), (1, 2), (1, 2), (1, 2)]
