
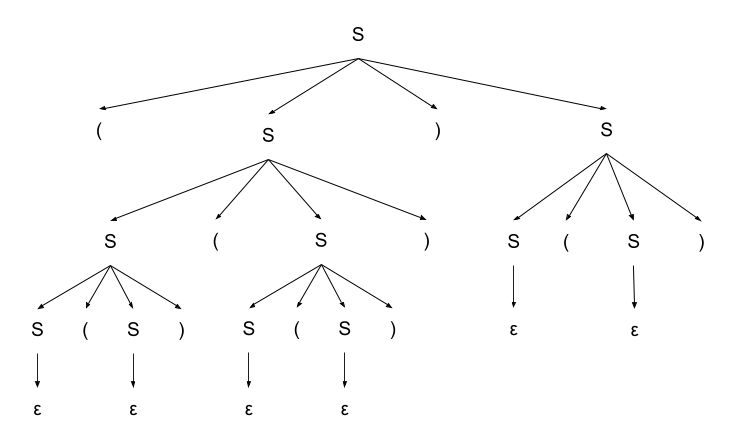
Построим дерево разбора скобочной последовательности из примера.
Однако, есть КС-языки, для которых не существует однозначных КС-грамматик. Такие языки и грамматики их порождающие называют существенно неоднозначными
.
- Wikipedia — Context-free grammar
- Википедия — Контекстно-свободная грамматика
- Хопкрофт Д., Мотвани Р., Ульман Д.
— Введение в теорию автоматов, языков и вычислений
, 2-е изд. : Пер. с англ. — Москва, Издательский дом «Вильямс», 2002. — 528 с. : ISBN 5-8459-0261-4 (рус.)
Графическим
способом отображения процесса разбора
цепочек является дерево разбора (или
дерево вывода).
Определение
дерево разбора грамматики

называется дерево, которое соответствует
некоторой цепочке вывода и удовлетворяет
следующим условиям:
каждая
вершина дерева обозначается символом
грамматики

;корнем
дерева является вершина, обозначенная
начальным символом грамматики S
;листьями
дерева (концевыми вершинами) являются
вершины, обозначенные терминальными
символами грамматики или символом
пустой строки ;если
некоторый узел дерева обозначен символом
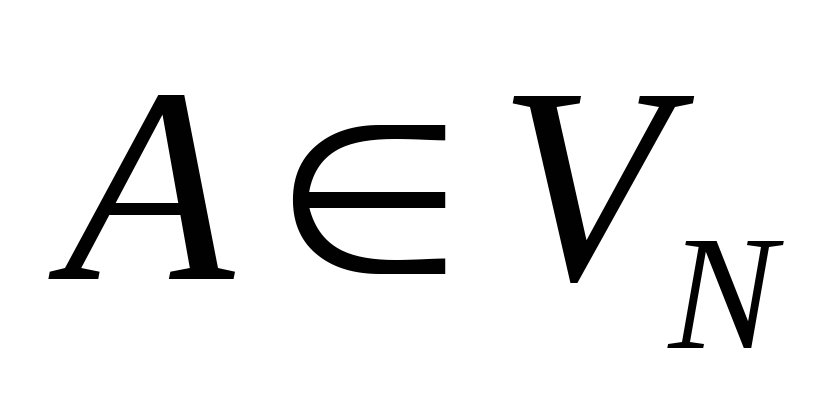
,
а связанные с ним узлы – символами
,
то в грамматике

существует правило
Дерево разбора
можно построить двумя способами: сверху
вниз и снизу вверх.
Графическим
способом отображения процесса разбора
цепочек является дерево разбора (или
дерево вывода).
Определение
дерево разбора грамматики

называется дерево, которое соответствует
некоторой цепочке вывода и удовлетворяет
следующим условиям:
каждая
вершина дерева обозначается символом
грамматики

;корнем
дерева является вершина, обозначенная
начальным символом грамматики S
;листьями
дерева (концевыми вершинами) являются
вершины, обозначенные терминальными
символами грамматики или символом
пустой строки ;если
некоторый узел дерева обозначен символом

,
а связанные с ним узлы – символами
,
то в грамматике

существует правило
Дерево разбора
можно построить двумя способами: сверху
вниз и снизу вверх.
Дерево разбора –
это дерево, показывающее сущность
порождения. Внутрение узлы отмечены
переменными, листья – терминалами или
ε. Для каждого внутренего узла должна
существовать продукция , голова которой
является отметкой узла, а отметки
сыновей узла, прочитанные слева направо,
образуют её тело.
Терминальная
цепочка принадлежит языку граматики
т. И т.т, когда она является кроной, по
крайней мере одного дерева разбора.
таким образом существование левых и
правых порождений и деревьев разбора
является равносильным условием того,
что все они определяют в точности цепочки
языка КС- граматики. Для некоторых
граматик можно найти терминальную
цепочку с несколькими деревьями разбора,
или (что равносильно) с несколькими
левыми или правыми порождениями. Такая
граматика называется неоднозначной.

0
p
0
1
P
1
E
* E
E
+ E
I
I
a
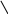
I
0
I
0
Особый интерес
представляют деревья со следущими св-ми
крона которых
является терминальной цепьюкрона деревьев
отмечены стартовым символом
- 2 Восходящее дерево разбора
- Связь ксг с конечными автоматами. Нормальная форма Хомского.
- 2 Восходящее дерево разбора
- 1 Нисходящее дерево разбора
- 1 Нисходящее дерево разбора
- Дерево синтаксического разбора¶
- Принцип микропрограммного управления. Теорема Глушкова. Понятия операционного и управляющих автоматов.
- Обход дерева¶
- Дерево синтаксического разбора¶
- Лево- и правосторонний вывод слова
2 Восходящее дерево разбора
Построение дерева
вывода снизу вверх начинается с листьев
дерева. В качестве листьев выбираются
терминальные символы конечной цепочки
вывода, которые на первом шаге построения
образуют последний уровень (слой) дерева.
Построение дерева идет по слоям. На
втором шаге построения в грамматике
выбирается правило, правая часть которого
соответствует крайним символам в слое
дерева (крайним правым символам при
правостороннем выводе и крайним левым
— при левостороннем). Выбранные вершины
слоя соединяются с новой вершиной,
которая выбирается из левой части
правила. Новая вершина попадает в слой
де рева вместо выбранных вершин.
Построение дерева закончено, если
достигнута корневая вершина (обозначенная
целевым символом), а иначе надо вернуться
ко второму шагу и повторить его над
полученным слоем дерева.
Поскольку все
известные языки программирования имеют
нотацию записи «слева — направо»,
компилятор также всегда читает входную
программу слева направо (и сверху
вниз, если программа разбита на несколько
строк). Поэтому для построения дерева
вывода методом «сверху вниз», как
правило, используется левосторонний
вывод, а для построения «снизу вверх»
— правосторонний вывод. На эту особенность
компиляторов стоит обратить внимание.
Нотация чтения программ «слева направо»
влияет не только на порядок разбора
программы компилятором (для пользователя
это, как правило, не имеет значения), но
и ни порядок выполнения операций — при
отсутствии скобок большинство равноправных
операций выполняются в порядке слева
направо, а это уже имеет существенное
значение.
Связь ксг с конечными автоматами. Нормальная форма Хомского.
По любой заданой
КСГ можно наблюдать одну КСГ которая
порождает тот же язык что и исходная
за искл. Цепочки эпсилон, и при этом
новая граматика находиться в нормальной
форме Хомского т.е не содержит бесполезных
символов и тела каждой продукчии состоит
либо из 2–х переменных либо из одного
терминала
переменнные можно
удалить из граматики если она не порождает
не одной терминальной цепочки, или не
встречает в чепочках выводимых из
стартового символа
2) удаляются цепные
и и эпсилон продукции
2 Восходящее дерево разбора
Построение дерева
вывода снизу вверх начинается с листьев
дерева. В качестве листьев выбираются
терминальные символы конечной цепочки
вывода, которые на первом шаге построения
образуют последний уровень (слой) дерева.
Построение дерева идет по слоям. На
втором шаге построения в грамматике
выбирается правило, правая часть которого
соответствует крайним символам в слое
дерева (крайним правым символам при
правостороннем выводе и крайним левым
— при левостороннем). Выбранные вершины
слоя соединяются с новой вершиной,
которая выбирается из левой части
правила. Новая вершина попадает в слой
де рева вместо выбранных вершин.
Построение дерева закончено, если
достигнута корневая вершина (обозначенная
целевым символом), а иначе надо вернуться
ко второму шагу и повторить его над
полученным слоем дерева.
Поскольку все
известные языки программирования имеют
нотацию записи «слева — направо»,
компилятор также всегда читает входную
программу слева направо (и сверху
вниз, если программа разбита на несколько
строк). Поэтому для построения дерева
вывода методом «сверху вниз», как
правило, используется левосторонний
вывод, а для построения «снизу вверх»
— правосторонний вывод. На эту особенность
компиляторов стоит обратить внимание.
Нотация чтения программ «слева направо»
влияет не только на порядок разбора
программы компилятором (для пользователя
это, как правило, не имеет значения), но
и ни порядок выполнения операций — при
отсутствии скобок большинство равноправных
операций выполняются в порядке слева
направо, а это уже имеет существенное
значение.
1 Нисходящее дерево разбора
При построении
дерева вывода сверху вниз построение
начинается с целевого символа грамматики,
который помещается в корень дерева.
Затем в грамматике выбирается необходимое
правило, и на первом шаге вывода корневой
символ раскрывается на несколько
символов первого уровня. На втором шаге
среди всех концевых вершин дерева
выбирается крайняя (крайняя левая —
для левостороннего вывода, крайняя
правая — для правостороннего) вершина,
обозначенная нетерминальным символом,
для этой вершины выбирается нужное
правило грамматики, и она раскрывается
на несколько вершин следующего уровня.
Построение дерева заканчивается,
когда все концевые вершины обозначены
терминальными символами, в противном
случае надо вернуться ко второму шагу
и продолжить построение.
1 Нисходящее дерево разбора
При построении
дерева вывода сверху вниз построение
начинается с целевого символа грамматики,
который помещается в корень дерева.
Затем в грамматике выбирается необходимое
правило, и на первом шаге вывода корневой
символ раскрывается на несколько
символов первого уровня. На втором шаге
среди всех концевых вершин дерева
выбирается крайняя (крайняя левая —
для левостороннего вывода, крайняя
правая — для правостороннего) вершина,
обозначенная нетерминальным символом,
для этой вершины выбирается нужное
правило грамматики, и она раскрывается
на несколько вершин следующего уровня.
Построение дерева заканчивается,
когда все концевые вершины обозначены
терминальными символами, в противном
случае надо вернуться ко второму шагу
и продолжить построение.
Дерево синтаксического разбора¶
Закончив с реализацией дерева как структуры данных, рассмотрим примеры его применения при решении некоторых реальных задач. Этот раздел будет посвящён деревьям синтаксического разбора. Они могут использоваться для представления таких конструкций реального мира, как предложения естественного языка или математические выражения.
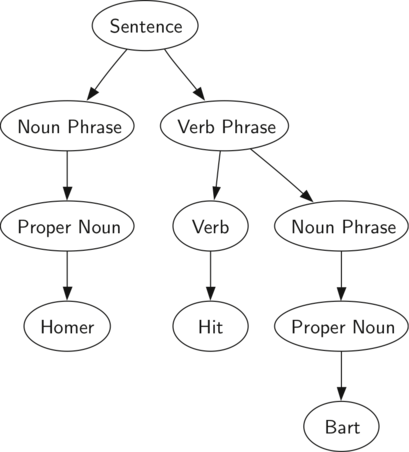
Рисунок 1: Дерево синтаксического разбора простого предложения
На рисунке 1
изображена иерархическая структура простого предложения. Такое представление позволяет нам работать с его отдельными частями, используя поддеревья.
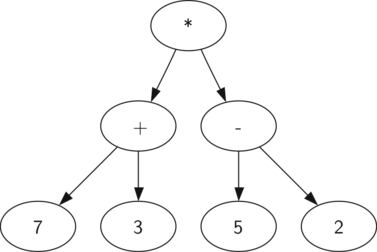
Рисунок 2: Дерево синтаксического разбора выражения
Также в виде дерева синтаксического разбора можно представить математическое выражение наподобие \(((7 + 3) * (5 — 2))\)
(см. рисунок 2
). Мы уже рассматривали выражения с полной расстановкой скобок: исходя из этого, что можно сказать о данном примере? Нам известно, что умножение имеет более высокий приоритет, чем сложение и вычитание. Однако, благодаря скобкам мы знаем, что здесь сначала нужно вычислить сумму и разность. Иерархия дерева помогает лучше понять порядок вычисления выражения в целом. Перед тем, как найти стоящее на самом верху произведение, требуется произвести сложение и вычитание в поддеревьях. Первая операция — левое поддерево — даст 10, вторая — правое поддерево — 3. Используя свойство иерархической структуры, мы можем просто заменить каждое из поддеревьев на узел, содержащий найденный ответ. Эта процедура даст упрощённое дерево, показанное на рисунке 3
.
Рисунок 3: Упрощённое дерево синтаксического разбора для
До конца этого раздела мы собираемся как следует протестировать деревья синтаксического разбора. Точнее, будет рассмотрено:
- Как построить дерево разбора для математического выражения с полной расстановкой скобок.
- Как вычислить выражение, хранящееся в дереве разбора.
- Как записать оригинальное математическое выражение из дерева разбора.
Первый шаг при постороении дерева синтаксического разбора — это разбить строку выражения на список токенов. Их насчитывается четыре вида: левая скобка, правая скобка, оператор и операнд. Мы знаем, что прочитанная левая скобка всегда означает начало нового выражения и, следовательно, необходимо создать связанное с ним поддерево. И наоборот, считывание правой скобки сигнализирует о завершении выражения. Так же известно, что операнды будут листьями и потомками своих операторов. Наконец, мы знаем, что каждый оператор имеет обоих своих потомков.
Используя сказанную выше информацию, определим следующие правила:
- Если считан токен
— добавляем новый узел, как левого потомка текущего, и спускаемся к нему вниз. - Если считанный один из элементов списка
, то устанавливаем корневое значение текущего узла равным оператору из этого токена. Добавляем новый узел на место правого потомка текущего и спускаемся вниз по правому поддереву. - Если считанный токен — число, то устанавливаем корневое значение равным этой величине и возвращаемся к родителю.
- Если считан токен
, то перемещаемся к родителю текущего узла.

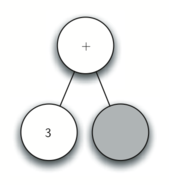
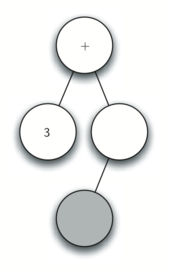
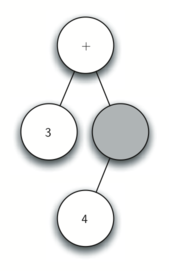
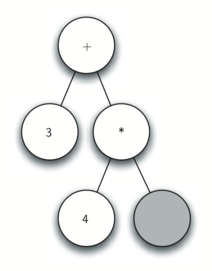
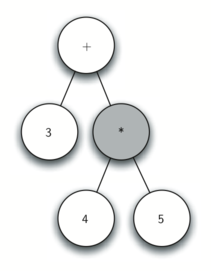
Рисунок 4: Трассировка постороения дерева разбора.
Используя этот рисунок, пройдём по примеру шаг за шагом.
а) Создаём пустое дерево.
б) Читаем
в качестве первого токена. По правилу 1 создаём новый узел, как левого потомка корня. Делаем его текущим.
в) Считываем следующий токен —
. По правилу 3 устанавливаем значение текущего узла в
и перемещаемся обратно к его родителю.
г) Следующим считываем
. По правилу 2 устанавливаем корневое значение текущего узла в
и добавляем ему правого потомка. Этот новый узел становится текущим.
д) Считываем
. По правилу 1 создаём для текущего узла левого потомка. Этот новый узел становится текущим.
е) Считываем
. По правилу 3 устанавливаем значение текущего узла равным
. Делаем текущим родителя
.
ж) Считываем следующий токен —
. По правилу 2 устанавливаем корневое значение текущего узла равным
и создаём его правого потомка. Он становится текущим.
з) Считываем
. По правилу 3 устанавливаем корневое значение текущего узла в
, после чего текущим становится его родитель.
и) Считываем
. По правилу 4 делаем текущим узлом родителя
.
к) Наконец, считываем последний токен —
. По правилу 4 мы должны сделать текущим родителя
. Но такого узла не существует, следовательно, мы закончили.
Из примера выше очевидна необходимость отслеживать не только текущий узел, но и его предка. Интерфейс дерева предоставляет нам способы получить потомков заданного узла — с помощью методов
и
, — но как отследить родителя? Простым решением для этого станет использование стека в процессе прохода по дереву. Перед тем, как спуститься к потомку узла, проследний мы кладём в стек. Когда же надо будет вернуть родителя текущего узла, мы вытолкнем из стека нужный элемент.
Используя описанные выше правила совместно с операциями из
и
, мы готовы написать на Python функцию для создания дерева синтаксического разбора. Код её представлен в ActiveCode 1
.
Постороение дерева синтаксического разбора (parsebuild)
Четыре правила для постороения дерева разбора закодированы в первых четырёх
-ах 11, 15, 19 и 24 строк ActiveCode 1
. В каждом случае вы видите код, воплощающий одно из описанных выше правил с помощью нескольких вызовов методов классов
или
. Единственная ошибка, на которую в этой функции происходит проверка, — ветка
, вызывающая исключение
, если мы получаем токен, который не можем рапознать.
Итак, дерево синтаксического разбора построено, но что с ним теперь делать? В качестве первого примера, напишем функцию, вычисляющую дерево разбора и возвращающую числовой результат. Для этого будем использовать иерархическу природу дерева. Посмотрите ещё раз на рисунок 2
. Напоминаем: оригинальное дерево можно заменять упрощённым, показанным на рисунке 3
. Это предполагает возможность написать алгоритм, вычисляющий дерево разбора с помощью рекурсивного вычисления каждого из его поддеревьев.
Как мы уже делали для рекурсивных алгоритмов в прошлом, написание функции начнём с выявления базового случая. Естественным базовым случаем для рекурсивных алгоритмов, работающих с деревьями, является проверка узла на лист. В дереве разбора такими узлами всегда будут операнды. Поскольку объекты, подобные целым или действительным числам, не требуют дальнейшей интерпретации, функция
может просто возвращать значение, сохранённое в листе дерева. Рекурсивный шаг, продвигающий функцию к базовому случаю, будет вызывать
для правого и левого потомков текущего узла. Так мы эффективно спустимся по дереву до его листьев.
Чтобы собрать вместе результаты двух рекурсивных вызовов, мы просто применим к ним сохранённый в родительском узле оператор. В примере на рисунке 3
мы видим, что два потомка корневого узла вычисляются в 10 и 3. Применение к ним оператора умножения даст окончательный результат, равный 30.
Код рекурсивной функции
показан в листинге 1
. Сначала мы получаем ссылки на правого и левого потомков текущего узла. Если оба они вычисляются в
, значит этот узел — лист. Это проверяется в строке 7. Если же узел не листовой, то ищем в нём оператор и применяем его к результатам рекурсивных вычислений левого и правого потомков.
Наконец, проследим работу функции
на дереве синтаксического разбора, которое изображено на рисунке 4
. В первом вызове
мы передаём ей корень всего дерева в качестве параметра
. Затем получаем ссылки на левого и правого потомков, чтобы убедиться в их существовании. В строке 9 идёт следующий рекурсивный вызов. Мы начинаем с поиска оператора в корне дерева, которым в данном случае является
. Он отображается как вызов функции
, принимающей два параметра. Традиционно для вызова функции первым, что сделает Python, станет вычисление переданных в функцию параметров. В нашем случае оба они — рекурсивные вызовы
. Вычисляя слева направо, сначала выполнится левый рекурсивный вызов, куда передано левое поддерево. Мы обнаружим, что этот узел не имеет потомков, следовательно, является листом. Поэтому хранящееся в нём значение просто вернётся, как результат вычисления. В данном случае это будет целое число 3.
К настоящему моменту у нас есть один параметр, вычисленный для верхнего вызова
. Но мы ещё не закончили. Продолжая вычислять параметры слева направо, сделаем рекурсивный вызов для правого поддерева корня. Обнаружив, что у него есть и правый, и левый потомки, ищем оператор, хранящийся в узле, (
) и вызываем для него функцию, передавая в неё левого и правого потомков в качестве параметров. В этой точке вычисления оба рекурсивных вызова вернут листья — целые 4 и 5, соответственно. Имея их, вернём результат
. Теперь у нас есть все операнды для верхнего оператора
, и остаётся просто вызвать
. Результат вычисления дерева для выражения \((3 + (4 * 5))\)
равен 23.
Принцип микропрограммного управления. Теорема Глушкова. Понятия операционного и управляющих автоматов.
Функциональная и
структурная организация выч. Устройств
любая операция
релизуемая устройством, которая
расссматривает как элементарные
действия операций. Передача информации
из одного устройства в другоедля управления
используются логические условия
зависисмости от результата, могут
принимать значения либо истинылибо
лжи(0)процес выполнения
операций в устройстве описывается в
форме алгоритма который представляется
в терминах микроопераций и логических
условий и называется микропрограммой.
Она определяет порядок следования
операций и необходима для получения
результатаиспользуется как
форма представления функций устройства
на основе которой определяется порядок
функционирования устройства во врепени
академиком глушковым
было показано что в любом устройстве
обработки информации, операционный
автомат это:
Значение логических
условий в операционном автомате задаются
множеством осведомительных сигналов.
Управляющий автомат
генерирует последовательность управляющих
сигналов предписаную микропрограммой
и соответственым значение логических
условий
Операционый автомат
задается 5 множествами
мн-во вх слов Д
мн-во
выходных слов Rмн-во
внутрених слов Sмн-во микроопераций
У (преобразование вхю слов в выходные)лог. Условие х
Обход дерева¶
После испытания функционала нашего дерева, пришло время расмотреть некоторые дополнительные модели использования этой структуры данных. Их можно разделить по трём способам доступа к узлам дерева. Различие будет состоять в порядке посещения каждого узла. Мы будем называть посещение узлов словом “обход”. Три способа обхода, которые будут рассмотрены, называются обход в прямом порядке
, симметричный обход
и обход в обратном порядке
. Начнём с того, что дадим им более точные определения, а затем рассмотрим несколько примеров, где эти модели будут полезны.
- Обход в прямом порядке
- В этом случае мы сначала посещаем корневой узел, затем рекурсивно обходим в прямом порядке левое поддерево, после чего таким же образом обходим правое.
- Симметричный обход
- Сначала мы симметрично обходим левое поддерево, затем посещаем корневой узел, затем — правое поддерево.
- Обход в обратном порядке
- Сначала делается рекурсивный обратный обход левого и правого поддеревьев, после чего посещается корневой узел.
Рассмотрим несколько примеров, иллюстрирующих каждый из этих типов обхода. Первым будет обход в прямом порядке. В качестве примера дерева возьмём эту книгу. Сама по себе она является корнем, чьи потомки — главы. Каждый раздел главы будет уже её потомком, каждый подраздел — потомком раздела и так далее. Рисунок 5
показывает урезанную версию книги (всего две главы). Обратите внимание, что алгоритм обхода будет работать с любым числом потомков, но мы пока сосредоточимся на двоичном дереве.
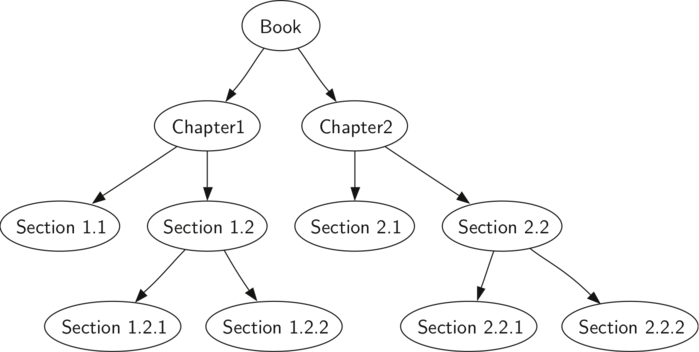
Рисунок 5: Представление книги в виде дерева
Предположим, вы хотите прочитать эту книгу от начала до конца. Обход в прямом порядке даст вам в точности такую последовательность. Начиная с корня дерева (узел Book), последуем инструкциям прямого обхода. Мы рекурсивно вызовем
к левому потомку Book (Chapter1), а потом уже к его левому потомку (Section 1.1). Section 1.1 является листом, так что больше рекурсивные вызовы не нужны. Закончив с ней, поднимемся по дереву вверх до Chapter 1. Нам по-прежнему надо посетить правое поддрево — Section 1.2. Как и раньше, сначала мы пойдём по его левому потомку (1.2.1), а затем посетим узел Section 1.2.2. Закончив с Section 1.2, мы вернёмся к Chapter 1, потом к Book и проделаем аналогичную процедуру для Chapter 2.
Код для описанного обхода дерева на удивление элегантный — в основном благодаря рекурсии. Листинг 2
демонстрирует код прямого обхода двоичного дерева.
Может возникнуть вопрос: в каком виде лучше написать алгоритм вроде обхода в прямом порядке? Должна ли это быть функция, просто использующая дерево как структуру данных, или это будет метод внутри класса “дерево”? В листинге 2
показан вариант с внешней функцией, принимающей двоичное дерево в качестве параметра. В частности, элегантность такой функции заключается в базовом случае — проверке существования дерева. Если её параметр равен
, то она возвращается без выполнения каких-либо действий.
Также
можно реализовать, как метод класса
. Код для этого случая показан в листинге 3
. Обратите внимание, что происходит, когда мы перемещаем код “снаружи” “внутрь”. В общем,
просто заменяется на
. Однако, так же требуется изменить и базовый случай. Внутренний метод проверяет наличие левого и правого потомков до того
, как делается рекурсивный вызов
.
Какой из двух способов реализации
лучше? Ответ: для данного случая — в виде внешней функции. Причина в том, что вы очень редко хотите просто обойти дерево. В большинстве случаев вам нужно сделать что-то ещё во время использования одной из моделей обхода. Фактически, уже в следующем примере мы увидим, что модель обхода
очень близка к коду, который мы писали ранее для вычисления дерева синтаксического разбора. Исходя из изложенного, для оставшихся моделей мы будем писать внешние функции.
Алгоритм обхода
показан в листинге 4
. Он очень близок к
, за исключением того, что мы перемещаем вызов печати в конец функции.
Мы уже видели распространённое использование обхода в обратном порядке — вычисление дерева синтаксического разбора. Взгляните на листинг 1
ещё раз. Что мы делаем, так это вычисляем левое поддерево, потом правое и собираем их в корне через вызов функции оператора. Предположим, наше двоичное дерево будет хранить только данные для математического выражения. Давайте перепишем функцию вычисления более приближённо к коду
из листинга 4
(см. листинг 5
).
Обратите внимание, что код в листинге 4
аналогичен коду из листинга 5
, за исключением того, что вместо печати ключей в конце функции, мы их возвращаем. Это позволяет сохранить ответы рекурсивных вызовов в строках 6 и 7. Потом они используются вместе с оператором в строке 9.
Последним рассмотренным в этом разделе обходом будет симметричный обход. В его ходе мы сначала посещаем левое поддерево, затем корень и потом уже правое поддерево. Листинг 6
показывает этот алгоритм в коде. Заметьте: во всех трёх моделях обхода мы просто меняем расположение оператора
по отношению к двум рекурсивным вызовам.
Если мы применим простой симметричный обход к дереву синтаксического разбора, то получим оригинальное выражение, правда без скобок. Давайте модифицируем базовый алгоритм симметричного обхода, чтобы он позволял восстановить версию выражения с полной расстановкой скобок. Единственное изменение, которое надо внести в базовый шаблон, — это печатать левую скобку до
рекурсивного вызова с левым поддеревом и правую скобку после
рекурсивного вызова с правым поддеревом. Модифицированный код показан в листинге 7
.
Обратите внимание, что функция
после реализации помещает скобки вокруг каждого числа. Не то, чтобы это было неправильно, но они здесь просто не нужны. В упражнении в конце этой главы мы попросим вас изменить
, чтобы исправить это.
Дерево синтаксического разбора¶
Закончив с реализацией дерева как структуры данных, рассмотрим примеры его применения при решении некоторых реальных задач. Этот раздел будет посвящён деревьям синтаксического разбора. Они могут использоваться для представления таких конструкций реального мира, как предложения естественного языка или математические выражения.

Рисунок 1: Дерево синтаксического разбора простого предложения
На рисунке 1
изображена иерархическая структура простого предложения. Такое представление позволяет нам работать с его отдельными частями, используя поддеревья.

Рисунок 2: Дерево синтаксического разбора выражения
Также можно представить в виде дерева синтаксического разбора математическое выражение наподобие \(((7 + 3) * (5 — 2))\)
(см. рисунок 2
). Мы уже рассматривали выражения с полной расстановкой скобок; исходя из этого, что можно сказать о данном примере? Нам известно, что умножение имеет более высокий приоритет, чем сложение и вычитание. Благодаря скобкам мы знаем, что перед умножением нужно вычислить сумму и разность. Иерархия дерева помогает лучше понять порядок вычисления выражения целиком. Перед тем, как найти находящееся на самом верху произведение, нужно провести сложение и вычитание в поддеревьях. Сложение — левое поддерево — даст 10, вычитание — правое поддерево — 3. Используя свойство иерархической структуры, мы можем просто заменить каждое из поддеревьем на узел, содержащий вычисленный ответ. Процедура замены даст нам упрощённое дерево, показанное на рисунке 3
.

Рисунок 3: Упрощённое дерево синтаксического разбора для
До конца этого раздела мы собираемся детально протестировать деревья синтаксического разбора. Точнее, мы рассмотрим:
- Как построить дерево разбора для математического выражения с полной расстановкой скобок.
- Как вычислить выражение, хранящееся в дереве разбора.
- Как записать оригинальное математическое выражение из дерева разбора.
Первый шаг при постороении дерева синтаксического разбора — это разбить строку выражения на список токенов. Их насчитывается четыре вида: левая скобка, правая скобка, оператор и операнд. Мы знаем, что прочитанная левая скобка всегда означает начало нового выражения и, следовательно, необходимо создать связанное с ним новое дерево. И наоборот, когда мы считываем правую скобку, мы завершаем выражение. Так же известно, что операнды будут листьями и потомками своих операторов. Наконец, мы знаем, что каждый оператор имеет как правого, так и левого потомков.
Используя перечисленную выше информацию, определим следующие правила:
- Если считанный токен
— добавляем новый узел, как левого потомка текущего узла, и спускаемся по нему вниз. - Если считанный токен — один из элементов списка
, то устанавливаем корневое значение текущего узла равным оператору из этого токена. Добавляем новый узел на место правого потомка текущего и спускаемся вниз по правому поддереву. - Если считанный токен — число, то устанавливаем корневое значение равным этой величине и возвращаемся к родителю.
- Если считанный токен —
, то перемещаемся к родителю текущего узла.








Рисунок 4: Трассировка постороения дерева разбора.
Используя этот рисунок, пройдём по примеру шаг за шагом.
а) Создаём пустое дерево.
б) Читаем
в качестве первого токена. По правилу 1, создаём новый узел, как левого потомка корня. Делаем текущим этот новый узел.
в) Считываем следующий токен —
. По правилу 3 устанавливаем значение текущего узла в
и перемещаемся обратно к родителю.
г) Следующим считываем
. По правилу 2 устанавливаем корневое значение текущего узла в
и добавляем ему правого потомка. Этот новый узел становится текущим.
д) Считываем
. По правилу 1 создаём для текущего узла левого потомка. Этот новый узел становится текущим.
е) Считываем
. По правилу 3 устанавливаем значение текущего узла равным
. Делаем текущим узлом родителя
.
ж) Считываем следующий токен —
. По правилу 2 устанавливаем корневое значение текущего узла равным
и создаём его правого потомка. Он становится текущим.
з) Считываем
. По правилу 3 устанавливаем корневое значение текущего узла в
, после чего текущим становится его родитель.
и) Считываем
. По правилу 4 делаем текущим узлом родителя
.
к) Наконец, считываем последний токен —
. По правилу 4 мы должны сделать текущим родителя
. Но такого узла не существует, следовательно, мы закончили.
Из примера выше очевидно, что необходимо отслеживать не только текущий узел, но и его родителя. Интерфейс дерева предоставляет нам способы получить потомков заданного узла — с помощью методов
и
, — но как нам отследить родителя? Простым решением для этого станет использование стека в процессе прохода по дереву. Перед тем, как спуститься к потомку узла, мы кладём его в стек. Когда же надо будет вернуть родителя текущего узла, мы вытолкнем из стека нужный узел.
Используя описанные выше правила совместно с операциями из
и
, мы готовы написать на Python функцию для создания дерева синтаксического разбора. Код её представлен в ActiveCode 1
.
Постороение дерева синтаксического разбора (parsebuild)
Четыре правила для постороения дерева разбора закодированы в первых четырёх
-ах в строках 11, 15, 19 и 24 ActiveCode 1
. В каждом случае вы можете видеть код, воплощающий правило, как оно описано выше, с помощью нескольких вызовов методов
или
. Единственная ошибка, которую мы проверяем в этой функции — это ветка
, вызывающая исключение
, если мы получаем токен, который не можем рапознать.
Итак, дерево синтаксического разбора построено, но что с ним теперь делать? В качестве первого примера, напишем функцию, вычисляющую дерево разбора и возвращающую числовой результат. Для этого используем иерархическу природу дерева. Посмотрите ещё раз на рисунок 2
. Напомним, что мы можем заменить оригинальное дерево упрощённым, показанным на рисунке 3
. Это предполагает, что можно написать алгоритм, вычисляющий дерево разбора с помощью рекурсивного вычисления каждого из его поддеревьев.
Как мы уже делали для рекурсивных алгоритмов в прошлом, написание функции начнём с выявления базового случая. Естественным базовым случаем для рекурсивных алгоритмов, работающих с деревьями, является проверка узла на лист. В дереве разбора такими узлами всегда будут операнды. Поскольку объекты, подобные целым или действительным числам, не требуют дальнейшей интерпретации, функция
может просто возвращать значение, сохранённое в листе дерева. Рекурсивный шаг, продвигающий функцию к базовому случаю, будет вызывать
для правого и левого потомков текущего узла. Так мы эффективно спустимся по дереву до его листьев.
Чтобы собрать вместе результаты двух рекурсивных вызовов, мы просто применим к ним сохранённый в родительском узле оператор. В примере на рисунке 3
мы видим, что два потомка корневого узла выисляются в 10 и 3. Применение оператора умножения даст нам окончательный результат, равный 30.
Код рекурсивной функции
показан в листинге 1
. Сначала мы получаем ссылки на правого и левого потомков текущего узла. Если оба они вычисляются в
, значит этот узел — лист. Это проверяется в строке 7. Если же узел не листовой, то ищем в нём оператор и применяем его к результатам рекурсивных вычислений левого и правого потомков.
Наконец, проследим работу функции
на дереве синтаксического разбора, которое изображено на рисунке 4
. В первом вызове
мы передаём ей корень всего дерева в качестве параметра
. Затем получаем ссылки на левого и правого потомков, чтобы убедиться в их существовании. В строке 9 идёт следующий рекурсивный вызов. Мы начинаем с поиска оператора в корне дерева, которым в данном случае является
. Он отображается как вызов функции
, принимающей два параметра. Традиционно для вызова функции первым, что сделает Python, будет вычисление переданных в функцию параметров. В нашем случае оба они — рекурсивные вызовы
. Вычисляя слева направо, сначала выполнится левый рекурсивный вызов, куда передано левое поддерево. Мы обнаружим, что этот узел не имеет потомков, следовательно, является листом. Поэтому мы просто вернём хранящееся в нём значение, как результат вычисления. В данном случае им окажется целое число 3.
К этому моменту у нас есть один параметр, вычисленный для верхнего вызова
. Но мы ещё не закончили. Продолжая вычислять параметры слева направо, мы делаем рекурсивный вызов для правого поддерева корня. Обнаружив, что у него есть и правый, и левый потомки, ищем оператор, хранящийся в узле, (
) и вызываем для него функцию, передавая в неё левого и правого потомков в качестве параметров. В этой точке вычисления оба рекурсивных вызова вернут листья — целые 4 и 5, соответственно. Имея их, вернём результат
. Теперь у нас есть все операнды для верхнего оператора
, и всё, что остаётся, — это вызвать
. Результат вычисления дерева для выражения \((3 + (4 * 5))\)
равен 23.
Лево- и правосторонний вывод слова
Рассмотрим грамматику, выводящую все правильные скобочные последовательности.
- и — терминальные символы
- — стартовый нетерминал
Выведем слово :
Рассмотрим левосторонний вывод скобочной последовательности из примера:
