- Код
- в том, что я заменяю произведение вероятностей на сумму логарифмов, взятых с отрицательным знаком, и вычисляю не argmax, а argmin. Переход к логарифмам — распространненный прием чтобы избежать слишком маленьких чисел, которые могли бы получится при произведении вероятностей. Число 10(^-7), которое подставляется в логарифм, это способ избежать нуля в аргументе логарифма (т.к. он будет иначе он будет неопределен). Чтобы натренировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом:
def get_features(sample): return (sample[-1],) # get last letter samples = (line.decode('utf-8').split() for line in open('names.txt'))
features = [(get_features(feat), label) for feat, label in samples]
classifier = train(features) print 'gender: ', classify(classifier, get_features(u'Аглафья')) В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
def get_features(sample): return (
'll: %s' % sample[-1], # get last letter
'fl: %s' % sample[0], # get first letter
'sl: %s' % sample[1], # get second letter
) Алгоритм можно использовать для произвольного числа классов. К примеру, можно попробовать построить классификатор текстов по эмоциональной окраске.
Немного теории Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так: Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид: Знаменатель нас не интересует. Числитель же можно переписать так. Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид: Финальная формула примет вид:
Classifier Building in Scikit-learn
Naive Bayes Classifier with Synthetic Dataset In the first example, we will generate synthetic data using scikit-learn and train and evaluate the Gaussian Naive Bayes algorithm.
Generating the Dataset Scikit-learn provides us with a machine learning ecosystem so that you can generate the dataset and evaluate various machine learning algorithms. In our case, we are creating a dataset with six features, three classes, and 800 samples using the `make_classification` function.
from sklearn.datasets import make_classification X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
) We will use matplotlib.pyplot’s `scatter` function to visualize the dataset.
import matplotlib.pyplot as plt plt.scatter(X[:, 0], X[:, 1], c=y, marker="*"); As we can observe, there are three types of target labels, and we will be training a multiclass classification model.
Train Test Split Before we start the training process, we need to split the dataset into training and testing for model evaluation.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)
Model Building and Training Build a generic Gaussian Naive Bayes and train it on a training dataset. After that, feed a random test sample to the model to get a predicted value.
from sklearn.naive_bayes import GaussianNB # Build a Gaussian Classifier
model = GaussianNB() # Model training
model.fit(X_train, y_train) # Predict Output
predicted = model.predict([X_test[6]]) print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0]) Both actual and predicted values are the same.
Actual Value: 0
Predicted Value: 0
Model Evaluation We will not evolve the model on an unseen test dataset. First, we will predict the values for the test dataset and use them to calculate accuracy and F1 score.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
) y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted") print("Accuracy:", accuray)
print("F1 Score:", f1) Our model has performed fairly well with default hyperparameters.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328 To visualize the Confusion matrix, we will use `confusion_matrix` to calculate the true positives and true negatives and `ConfusionMatrixDisplay` to display the confusion matrix with the labels.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(); Our model has performed quite well, and we can improve model performance by scaling, preprocessing cross-validations, and hyperparameter optimization.
Naive Bayes Classifier with Loan Dataset Let’s train the Naive Bayes Classifier on the real dataset. Мы будем повторять большинство задач, за исключением предварительной обработки и исследования данных.
Загрузка данных В этом примере мы будем загружать Данные о кредите из DataCamp Workspace с использованием pandas ‘ read_csv `функция.
import pandas as pd df = pd.read_csv('loan_data.csv')
df.head()
Исследование данных Чтобы лучше понять набор данных, мы будем использовать `.info()`.
Набор данных состоит из 14 столбцов и 9578 строк.
Помимо «назначения», столбцы могут быть либо числами с плавающей запятой, либо целыми числами.
Наш целевой столбец — «не полностью оплачено».
df.info()
RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64, int64, object
memory usage: 1.0+ MB В этом примере мы будем разрабатывать модель для прогнозирования клиентов, которые не полностью выплатили кредит. Давайте рассмотрим столбец «Цель и цель», используя графический график Seaborn.
import seaborn as sns
import matplotlib.pyplot as plt sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right'); Наш набор данных представляет собой дисбаланс, который повлияет на производительность модели. Вы можете проверить Повторная выборка несбалансированного набора данных руководство, позволяющее получить практический опыт работы с несбалансированными наборами данных.
Обработка данных Теперь мы преобразуем столбец «цель» из категориального в целочисленный, используя функцию pandas `get_dummies`.
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head() После этого мы определим переменные функции (X) и цели (y) и разделим набор данных на обучающий и проверочный наборы.
from sklearn.model_selection import train_test_split X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid'] X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)
Построение и обучение моделей Построение и обучение модели довольно просты. Мы будем обучать модель на наборе обучающих данных, используя гиперпараметры по умолчанию.
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train);
Оценка модели Мы будем использовать точность и показатель f1 для определения производительности модели, и похоже, что гауссов наивный алгоритм Байеса показал себя достаточно хорошо.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
) y_pred = model.predict(X_test) accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted") print("Accuracy:", accuray)
print("F1 Score:", f1)
Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266 Из-за несбалансированного характера данных мы видим, что матрица путаницы рассказывает другую историю. Что касается цели меньшинства: «не полностью оплачено», мы неправильно маркируем ее.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(); Если вы столкнулись с проблемами во время обучения или оценки модели, вы можете ознакомиться с Учебным пособием по наивной байесовской классификации с помощью Scikit-learn Workspace . Он поставляется с набором данных, исходным кодом и выходными данными.
Категориальный Наивный Байес CategoricalNB реализовать категориально наивный алгоритм Байеса для категориально распределенных данных. Предполагается, что каждая функция, описывающая индексом $i$, имеет свое категориальное значение.
Как работает наивный байесовский классификатор? Давайте разберемся с работой Наивного Байеса на примере. Приведен пример погодных условий и занятий спортом. Вам необходимо рассчитать вероятность занятий спортом. Теперь вам нужно определить, будут ли игроки играть или нет, в зависимости от погодных условий.
Первый подход (в случае одной функции)
Шаг 1 : вычислить априорную вероятность для заданных меток классов .
Шаг 2 : Найти вероятность правдоподобия для каждого атрибута для каждого класса .
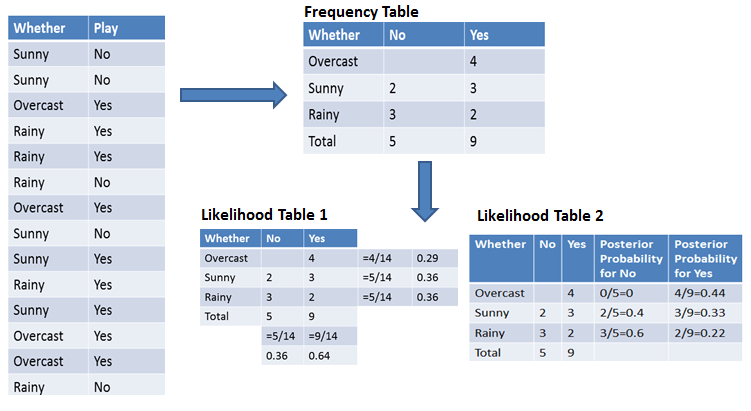
Шаг 3 : поместите эти значения в формулу Байеса и рассчитайте апостериорную вероятность.
Шаг 4 : Посмотрите, какой класс имеет более высокую вероятность, учитывая, что входные данные принадлежат к классу с более высокой вероятностью. Для упрощения расчета априорной и апостериорной вероятности вы можете использовать две таблицы: таблицу частот и таблицу правдоподобия. Обе эти таблицы помогут вам рассчитать априорную и апостериорную вероятность. Таблица частот содержит появление меток для всех объектов. Есть две таблицы вероятности. Таблица правдоподобия 1 показывает априорные вероятности меток, а таблица правдоподобия 2 показывает апостериорную вероятность. Теперь предположим, что вы хотите вычислить вероятность игры в пасмурную погоду. Вероятность игры:
Вычислить априорные вероятности: P(пасмурно) = 4/14 = 0,29 P(Да)= 9/14 = 0,64
Вычислить апостериорные вероятности:
Поместите априорную и апостериорную вероятности в уравнение Аналогично можно посчитать вероятность неигры: Вероятность не играть:
Вычислить априорные вероятности: P(пасмурно) = 4/14 = 0,29 P(Нет)= 5/14 = 0,36
Вычислить апостериорные вероятности:
Поместите априорную и апостериорную вероятности в уравнение Вероятность класса «Да» выше. Таким образом, здесь вы можете определить, будет ли погода пасмурной, чем игроки будут заниматься этим видом спорта. <h3 id="second-approach-(in-case-of-multiple-features)- Второй подход (в случае нескольких функций) Теперь предположим, что вы хотите вычислить вероятность игры в пасмурную погоду и умеренную температуру. Вероятность игры:
Вычислите априорные вероятности: P(Да)= 9/14 = 0,64 Аналогично можно посчитать вероятность неигры: Вероятность не играть:
Вычислите априорные вероятности: P(No)= 5/14 = 0,36 Вероятность класса «Да» выше. Таким образом, здесь можно сказать, что если погода пасмурная, то игроки будут заниматься этим видом спорта.
Набор данных RCV1 Reuters Corpus Volume I (RCV1) — это архив из более чем 800 000 вручную категоризированных новостных лент, предоставленных Reuters, Ltd. для исследовательских целей. Набор данных подробно описан в 1 Характеристики набора данных: sklearn.datasets.fetch_rcv1 загрузить эту версию: RCV1-v2, упомянуть, полные наборы, темы с несколькими ярлыками:
>>> из sklearn.datasets import fetch_rcv1
>>> rcv1 = fetch_rcv1() Он возвращает объект, словарь, соблюдая атрибуты: data : Матрица функций — это типовая разреженная матрица CSR с 804414 выборками и 47236 функциями. Ненулевые значения содержат нормализованные по косинусу логарифмические записи TF-IDF. Предлагается почти хронологическое разделение на 1 : первые 23149 выборок являются обучающей выборкой. Последние 781265 образцов — это набор для тестирования. Это следует указать в хронологическом порядке LYRL2004. В массиве 0,16% ненулевых результатов:
>>> rcv1.data.shape
(804414, 47236) target : Целевые значения хранения в разреженной матрице CSR с 804414 выборками и 103 категориями. Каждый образец имеет значение 1 в своих категориях и 0 в других. В массиве 3,15% ненулевых результатов:
>>> rcv1.target.shape
(804414, 103) sample_id : Каждый образец можно идентифицировать по его идентификатору в отдельных частях (с пробелами) от 2286 до 810596:
>>> rcv1.sample_id[:3]
массив([2286, 2287, 2288], dtype=uint32) target_names : Целевые значения — это тема каждого образца. Каждый образец относится как минимум к одной теме, но не более чем к 17 темам. Всего 103 темы, техника из которых представлена строкой. Часто их корпус состоит из пяти порядков, от 5 для GMIL до 381327 для CCAT:
>>> rcv1.target_names[:3].tolist()
['E11', 'ECAT', 'M11'] При необходимости набор данных будет загружен с закрытая страница rcv1 . Сжатый размер составляет около 656 МБ. 1 Льюис, Д. Д., Янг, Ю., Роуз, Т. Г., и Ли, Ф. (2004). RCV1: новая коллекция тестов для исследования категоризации текста. Журнал исследований в области машинного обучения, 5, 361–397.
Набор данных California Housing Характеристики набора данных: Количество экземпляров 20640 Количество атрибутов 8 числовых, прогнозных атрибутов и цель Информация об атрибутах :
Медианный доход MedInc в блоке
HouseAge средний возраст дома в блоке
Среднее количество комнат в AveRooms
Среднее количество спален AveBedrms
Население блока населения
Средняя заполняемость дома AveOccup
Широта дома блок широта
Долгота долгота блока дома Отсутствующие значения атрибутов Нет Этот набор данных был получен из репозитория StatLib. http://lib.stat.cmu.edu/datasets/ Целевая переменная — это средняя стоимость дома для округов Калифорнии. Этот набор данных был получен из переписи населения США 1990 года с использованием одной строки на каждую блочную группу переписи. Блочная группа — это наименьшая географическая единица, для которой Бюро переписи США публикует выборочные данные (блочная группа обычно насчитывает от 600 до 3000 человек).
Пейс, Р. Келли и Рональд Барри, Разреженные пространственные авторегрессии, статистика и вероятностные письма, 33 (1997) 291-297.
Гауссовский наивный байесовский Параметры $\sigma_y Параметры $\sigma_y$ а также $\mu_y$ оцениваются с использованием максимального правдоподобия. nbsp;а также $\mu_y Параметры $\sigma_y$ а также $\mu_y$ оцениваются с использованием максимального правдоподобия. nbsp;оцениваются с использованием максимального правдоподобия.
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.naive_bayes import GaussianNB
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
>>> gnb = GaussianNB()
>>> y_pred = gnb.fit(X_train, y_train).predict(X_test)
>>> print("Number of mislabeled points out of a total %d points : %d"
. % (X_test.shape[0], (y_test != y_pred).sum()))
Number of mislabeled points out of a total 75 points : 4
Advantages
It is not only a simple approach but also a fast and accurate method for prediction.
Naive Bayes has a very low computation cost.
It can efficiently work on a large dataset.
It performs well in case of discrete response variable compared to the continuous variable.
It can be used with multiple class prediction problems.
It also performs well in the case of text analytics problems.
When the assumption of independence holds, a Naive Bayes classifier performs better compared to other models like logistic regression.
Мультиномиальных Наивный Байес Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1 Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1$ называется сглаживанием Лапласа, а $\alpha < 1$ называется сглаживанием Лидстоуна. nbsp;называется сглаживанием Лапласа, а $\alpha < 1 Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1$ называется сглаживанием Лапласа, а $\alpha < 1$ называется сглаживанием Лидстоуна. nbsp;называется сглаживанием Лидстоуна.
Disadvantages
The assumption of independent features. In practice, it is almost impossible that model will get a set of predictors which are entirely independent.
If there is no training tuple of a particular class, this causes zero posterior probability. In this case, the model is unable to make predictions. This problem is known as Zero Probability/Frequency Problem.
What is Naive Bayes Classifier? Naive Bayes is a statistical classification technique based on Bayes Theorem. It is one of the simplest supervised learning algorithms. Naive Bayes classifier is the fast, accurate and reliable algorithm. Наивные байесовские классификаторы обладают высокой точностью и скоростью работы с большими наборами данных. Наивный байесовский классификатор предполагает, что влияние определенного признака в классе не зависит от других признаков. Например, кандидат на получение кредита является желательным или нет в зависимости от его / ее дохода, предыдущей кредитной истории и истории транзакций, возраста и местоположения. Даже если эти функции взаимозависимы, они все равно считаются независимыми. Это предположение упрощает вычисления и поэтому считается наивным. Это предположение называется условной независимостью класса. P(h): вероятность того, что гипотеза h верна (независимо от данных). Это известно как априорная вероятность h.
P(D): вероятность данных (независимо от гипотезы). Это известно как априорная вероятность.
P(h|D): вероятность гипотезы h с учетом данных D. Это известно как апостериорная вероятность.
P(D|h): вероятность данных d при условии, что гипотеза h верна. Это известно как апостериорная вероятность.
Дополнение наивного Байеса т. е. документ, отнесенный к классу, который является самым плохим дополнением.
Задача нулевой вероятности Предположим, что в наборе данных нет кортежа для рискованного кредита; в этом сценарии апостериорная вероятность будет равна нулю, и модель не сможет сделать прогноз. Эта проблема известна как нулевая вероятность, поскольку появление определенного класса равно нулю. Решением такой проблемы является поправка Лапласа или преобразование Лапласа. Коррекция Лапласа является одним из методов сглаживания. Здесь вы можете предположить, что набор данных достаточно велик, и добавление одной строки каждого класса не повлияет на оценочную вероятность. Это позволит решить проблему нулевых значений вероятности. Например: предположим, что для класса кредита рискованного в базе данных имеется 1000 обучающих кортежей. В этой базе данных столбец дохода содержит 0 кортежей для низкого дохода, 990 кортежей для среднего дохода и 10 кортежей для высокого дохода. Вероятности этих событий без учета поправки Лапласа равны 0, 0,990 (из 990/1000) и 0,010 (из 10/1000) . Теперь примените поправку Лапласа к данному набору данных. Давайте добавим еще один кортеж для каждой пары доход-стоимость. Вероятности этих событий:
Набор текстовых данных 20 групп новостей Набор данных из 20 групп новостей включает около 18000 сообщений групп новостей по 20 темам, разделенных на два подмножества: один для обучения (или разработки), другой для тестирования (или для оценки производительности). Разделение между поездом и набором тестов основано на сообщениях, отправленных до и после даты назначения. Этот модуль содержит два загрузчика. Первый,, sklearn.datasets.fetch_20newsgroups вернуть список необработанных текстов, которые могут быть переданы экстракторам текстовых признаков, например, CountVectorizer с пользовательскими параметрами для извлечения векторов признаков. Второй, sklearn.datasets.fetch_20newsgroups_vectorized верните готовые к использованию функции, т.е. е. нет необходимости использовать средства извлечения признаков. Характеристики набора данных: 7.2.2.1. Использование Эта sklearn.datasets.fetch_20newsgroups
функция представляет собой функцию выборки / кэширования данных, которая загружает архив данных с оригинального веб-сайта 20 групп новостей , извлекает содержимое архива в ~/scikit_learn_data/20news_home папку и вызывает sklearn.datasets.load_files либо папку обучающего, либо тестового набора, либо оба из них: >>> from sklearn.datasets import fetch_20newsgroups >>> newsgroups_train = fetch_20newsgroups(subset='train') >>> from pprint import pprint >>> pprint(list(newsgroups_train.target_names)) ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc'] Ложь реальных данных в filenames и target атрибутах. Целевой атрибут — это целочисленный индекс категории: >>> newsgroups_train.filenames.shape (11314,) >>> newsgroups_train.target.shape (11314,) >>> newsgroups_train.target[:10] array([ 7, 4, 4, 1, 14, 16, 13, 3, 2, 4]) Можно загрузить только подвыбор категорий, передав список категорий для загрузки в sklearn.datasets.fetch_20newsgroups функцию: >>> cats = ['alt.atheism', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', categories=cats) >>> list(newsgroups_train.target_names) ['alt.atheism', 'sci.space'] >>> newsgroups_train.filenames.shape (1073,) >>> newsgroups_train.target.shape (1073,) >>> newsgroups_train.target[:10] array([0, 1, 1, 1, 0, 1, 1, 0, 0, 0]) 7.2.2.2. Преобразование текста в векторы Чтобы наполнить прогнозные модели или модели кластеризации текстовыми данными, сначала необходимо преобразовать текст в векторы числовых значений, пригодные для статистического анализа. Это может быть достигнуто с помощью утилит, sklearn.feature_extraction.text как показано в следующем примере, которые извлекают векторы TF-IDF токенов unigram из подмножества 20news: >>> from sklearn.feature_extraction.text import TfidfVectorizer >>> categories = ['alt.atheism', 'talk.religion.misc', . 'comp.graphics', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', . categories=categories) >>> vectorizer = TfidfVectorizer() >>> vectors = vectorizer.fit_transform(newsgroups_train.data) >>> vectors.shape (2034, 34118) Извлеченные векторы TF-IDF очень разрежены, в среднем 159 ненулевых компонентов по выборке в более чем 30000-мерном пространстве (менее 0,5% ненулевых функций): >>> vectors.nnz / float(vectors.shape[0]) 159.01327. sklearn.datasets.fetch_20newsgroups_vectorized — это функция, которая возвращает готовые к использованию функции подсчета токенов вместо имен файлов. 7.2.2.3. Фильтрация текста для более реалистичного обучения Классификатору легко приспособиться к определенным вещам, которые появляются в данных 20 групп новостей, например, к заголовкам групп новостей. Многие классификаторы достигают очень высоких оценок F, но их результаты не могут быть обобщены на другие документы, выходящие за рамки этого временного окна. Например, давайте посмотрим на результаты полиномиального наивного байесовского классификатора, который быстро обучается и дает приличный F-балл: >>> from sklearn.naive_bayes import MultinomialNB >>> from sklearn import metrics >>> newsgroups_test = fetch_20newsgroups(subset='test', . categories=categories) >>> vectors_test = vectorizer.transform(newsgroups_test.data) >>> clf = MultinomialNB(alpha=.01) >>> clf.fit(vectors, newsgroups_train.target) MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) >>> pred = clf.predict(vectors_test) >>> metrics.f1_score(newsgroups_test.target, pred, average='macro') 0.88213. (В примере « Классификация текстовых документов с использованием разреженных функций» происходит перемешивание обучающих и тестовых данных вместо сегментации по времени, и в этом случае полиномиальный Наивный Байес получает гораздо более высокий F-балл 0,88. Вы еще не подозреваете, что происходит внутри этого? классификатор?) Давайте посмотрим, какие функции наиболее информативны: >>> import numpy as np >>> def show_top10(classifier, vectorizer, categories): . feature_names = np.asarray(vectorizer.get_feature_names()) . for i, category in enumerate(categories): . top10 = np.argsort(classifier.coef_[i])[-10:] . print("%s: %s" % (category, " ".join(feature_names[top10]))) . >>> show_top10(clf, vectorizer, newsgroups_train.target_names) alt.atheism: edu it and in you that is of to the comp.graphics: edu in graphics it is for and of to the sci.space: edu it that is in and space to of the talk.religion.misc: not it you in is that and to of the Теперь вы можете увидеть многие вещи, которым эти функции лучше всего подходят: Практически каждая группа отличается тем, что заголовки, такие как NNTP-Posting-Host: и, Distribution: появляются чаще или реже. Еще одна важная особенность связана с тем, является ли отправитель аффилированным лицом к университету, о чем свидетельствуют заголовки или подпись. Слово «статья» — важная особенность, основанная на том, как часто люди цитируют предыдущие сообщения, например: «В статье [идентификатор статьи], [имя] написал:» Другие функции соответствуют именам и адресам электронной почты конкретных людей, которые публиковали сообщения в то время. С таким обилием подсказок, которые различают группы новостей, классификаторам практически не нужно определять темы по тексту, и все они работают на одном высоком уровне. По этой причине функции, загружающие данные 20 групп новостей, предоставляют параметр с именем remove , сообщающий ему, какие виды информации нужно удалить из каждого файла. remove должен быть кортежем, содержащим любое подмножество из (‘headers’, ‘footers’, ‘quotes’), с указанием удалить заголовки, блоки подписи и блоки цитат соответственно. >>> newsgroups_test = fetch_20newsgroups(subset='test', . remove=('headers', 'footers', 'quotes'), . categories=categories) >>> vectors_test = vectorizer.transform(newsgroups_test.data) >>> pred = clf.predict(vectors_test) >>> metrics.f1_score(pred, newsgroups_test.target, average='macro') 0.77310. Этот классификатор потерял большую часть своего F-балла только потому, что мы удалили метаданные, которые не имеют ничего общего с классификацией тем. Он потеряет еще больше, если мы также удалим эти метаданные из данных обучения: >>> newsgroups_train = fetch_20newsgroups(subset='train', . remove=('headers', 'footers', 'quotes'), . categories=categories) >>> vectors = vectorizer.fit_transform(newsgroups_train.data) >>> clf = MultinomialNB(alpha=.01) >>> clf.fit(vectors, newsgroups_train.target) MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) >>> vectors_test = vectorizer.transform(newsgroups_test.data) >>> pred = clf.predict(vectors_test) >>> metrics.f1_score(newsgroups_test.target, pred, average='macro') 0.76995. Некоторые другие классификаторы лучше справляются с этой более сложной версией задачи. Попробуйте запустить пример конвейера для извлечения и оценки текстовых функций с --filter возможностью сравнения результатов и без нее. При оценке текстовых классификаторов для данных 20 групп новостей следует удалить метаданные, относящиеся к группам новостей. В scikit-learn вы можете сделать это, установив remove=(‘headers’, ‘footers’, ‘quotes’). Оценка F будет ниже, потому что это более реалистично. Набор данных Kddcup 99 Набор данных KDD Cup ’99 был создан путем обработки частей tcpdump из набора данных DARPA Intrusion Detection System (IDS) 1998 года, созданного MIT Lincoln Lab 2 Искусственные данные (описанные на домашней странице набора данных ) были сгенерированы с использованием закрытой сети и вручную введенных атак, чтобы произвести большое количество различных типов атак с нормальной активностью в фоновом режиме. Поскольку первоначальная цель состояла в том, чтобы создать большой обучающий набор для алгоритмов контролируемого обучения, существует большая часть (80,1%) аномальных данных, которые нереальны в реальном мире и не подходят для неконтролируемого обнаружения аномалий, направленного на обнаружение «аномальных» данных. то есть: качественно отличается от нормальных данных в значительном меньшинстве среди наблюдений. Таким образом, мы преобразуем набор данных KDD в два разных набора данных: SA и SF. SA получается простым выбором всех нормальных данных, а небольшая часть аномальных данных дает долю аномалий в 1%. SF получается, как в пункте 3 , путем простого сбора данных, атрибут logged_in положительный, таким образом сосредоточиваясь на атаке вторжения, что дает долю атаки 0,3%. http и smtp — это два подмножества SF, соответствующие третьей функции, равной http (соответственно, smtp). Общая структура KDD: sklearn.datasets.fetch_kddcup99 загрузит набор данных kddcup99; он возвращает объект, подобный словарю, с матрицей признаков в data члене и целевыми значениями в target . Необязательный аргумент «as_frame» преобразует data в pandas DataFrame и target в pandas Series. При необходимости набор данных будет загружен из Интернета. Анализ и результаты оценки обнаружения вторжений в автономном режиме DARPA 1999 г., Ричард Липпманн, Джошуа В. Хейнс, Дэвид Дж. Фрид, Джонатан Корба, Кумар Дас. К. Яманиши, Ж.-И. Такеучи, Дж. Уильямс и П. Милн. Онлайн-обнаружение неконтролируемых выбросов с использованием конечных смесей с дисконтирующими алгоритмами обучения. В материалах шестой международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных, страницы 320-324. ACM Press, 2000. Набор данных лица Olivetti Этот набор данных содержит набор изображений лиц , снятых в период с апреля 1992 г. по апрель 1994 г. в AT&T Laboratories Cambridge. sklearn.datasets.fetch_olivetti_faces Функция выборки / кэширования функцию , которая загружает архив данных от AT & T данные. Как описано на исходном веб-сайте: Есть десять различных изображений каждого из 40 различных предметов. Для некоторых объектов изображения были сделаны в разное время, варьируя освещение, выражение лица (открытые / закрытые глаза, улыбающийся / не улыбающийся) и детали лица (очки / без очков). Все изображения были сделаны на темном однородном фоне, когда испытуемые находились в вертикальном фронтальном положении (с допуском на некоторое боковое движение). Характеристики набора данных: «Цель» для этой базы данных — это целое число от 0 до 39, указывающее личность изображенного человека; однако, имея всего 10 примеров на класс, этот относительно небольшой набор данных более интересен с точки зрения неконтролируемого или полууправляемого обучения. Исходный набор данных состоял из 92 x 112, в то время как версия, доступная здесь, состоит из изображений 64×64. При использовании этих изображений, пожалуйста, отдайте должное AT&T Laboratories Cambridge. Подгонка нестандартной наивной байесовской модели Наивные байесовские модели могут использоваться для решения крупномасштабных задач классификации, для которых полный обучающий набор может не поместиться в памяти. Чтобы справиться с этим делом, MultinomialNB , BernoulliNB , и GaussianNB выставить partial_fit метод , который может быть использован пошагово , как это сделано с другими классификаторами , как показано в вне ядра классификации текстовых документов Все наивные байесовские классификаторы поддерживают взвешивание выборки. В отличие от fit метода, при первом вызове partial_fit необходимо передать список всех ожидаемых меток классов. Для обзора доступных стратегий в scikit-learn см. Также документацию по внешнему обучению Вызов метода partial_fit наивных моделей Байеса представляет некоторую вычислительную нагрузку. Рекомендуется использовать как можно большие размеры блоков данных, то есть насколько позволяет доступная оперативная память. Виды лесного покрова Образцы в этом наборе данных соответствуют участкам леса 30 × 30 м в США, собранным для задачи прогнозирования типа покрытия каждого участка, то есть доминирующих видов деревьев. Существует семь типов обложек, что делает эту задачу мультиклассовой классификацией. Каждый образец имеет 54 функции, описанные на домашней странице набора данных Некоторые из функций являются логическими индикаторами, а другие — дискретными или непрерывными измерениями. Характеристики набора данных: sklearn.datasets.fetch_covtype загрузит набор данных covertype; он возвращает подобный словарю объект Bunch с матрицей признаков в data члене и целевыми значениями в target . Если необязательный аргумент «as_frame» установлен в «True», он возвращает data и target в панд кадра данных, и будет являться дополнительным членом , frame а также. При необходимости набор данных будет загружен из Интернета. Classification Workflow Whenever you perform classification, the first step is to understand the problem and identify potential features and label. Features are those characteristics or attributes which affect the results of the label. For example, in the case of a loan distribution, bank managers identify the customer’s occupation, income, age, location, previous loan history, transaction history, and credit score. These characteristics are known as features that help the model classify customers. The classification has two phases, a learning phase and the evaluation phase. In the learning phase, the classifier trains its model on a given dataset, and in the evaluation phase, it tests the classifier’s performance. Performance is evaluated on the basis of various parameters such as accuracy, error, precision, and recall. Бернулли Наивный Байес BernoulliNB реализует простые байесовские алгоритмы обучения и классификации данных, которые распределяются согласно многомерному распределению Бернулли; то есть может быть несколько функций, но предполагается, что каждая из них является двоичной (Бернулли, логическая) переменной. Следовательно, этот класс требует, чтобы образцы были представлены как векторы признаков с двоичными значениями; если переданы данные любого другого типа, BernoulliNB экземпляр может преобразовать свой ввод в двоичную форму (в зависимости от binarize параметра). Решающее правило для наивного Байеса Бернулли основано на $P(x_i \mid y) = P(i \mid y) x_i + (1 — P(i \mid y)) (1 — x_i)$ которое отличается от правила полиномиального NB тем, что в нем явно наказывается отсутствие признака $i которое отличается от правила полиномиального NB тем, что в нем явно наказывается отсутствие признака $i$ это показатель класса y, где полиномиальный вариант просто игнорирует отсутствующую функцию. nbsp;это показатель класса y, где полиномиальный вариант просто игнорирует отсутствующую функцию. В случае классификации текста для обучения и использования этого классификатора могут использоваться векторы появления слов (а не векторы подсчета слов). BernoulliNB может работать лучше с некоторыми наборами данных, особенно с более короткими документами. Если позволяет время, желательно оценить обе модели. CD Мэннинг, П. Рагхаван и Х. Шютце (2008). Введение в поиск информации. Издательство Кембриджского университета, стр. 234-265. А. МакКаллум и К. Нигам (1998). Сравнение моделей событий для классификации наивного байесовского текста. Proc. Практикум AAAI / ICML-98 по обучению категоризации текста, стр. 41-48. В. Метсис, И. Андроутсопулос и Г. Палиурас (2006). Фильтрация спама с помощью наивного байесовского метода — какой наивный байесовский метод? 3-я конф. по электронной почте и защите от спама (CEAS). Тесты Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно. Помеченные лица в наборе данных по распознаванию лиц Wild Этот набор данных представляет собой коллекцию изображений известных людей в формате JPEG, собранных через Интернет, все подробности доступны на официальном сайте: Каждое изображение сосредоточено на одном лице. Типичная задача называется Face Verification: для пары двух изображений двоичный классификатор должен предсказать, принадлежат ли эти два изображения одному и тому же человеку. Альтернативная задача, «Распознавание лиц» или «Идентификация лиц»: по изображению лица неизвестного человека определить имя человека, обратившись к галерее ранее увиденных изображений идентифицированных лиц. И проверка лиц, и распознавание лиц — это задачи, которые обычно выполняются на выходе модели, обученной выполнять обнаружение лиц. Самая популярная модель для распознавания лиц называется Виола-Джонса и реализована в библиотеке OpenCV. Лица LFW были извлечены этим детектором лиц с различных онлайн-сайтов. Характеристики набора данных: 7.2.3.1. Использование scikit-learn предоставляет два загрузчика, которые автоматически загружают, кэшируют, анализируют файлы метаданных, декодируют jpeg и преобразуют интересные фрагменты в запомненные массивы numpy. Размер этого набора данных превышает 200 МБ. Первая загрузка обычно занимает более пары минут, чтобы полностью декодировать соответствующую часть файлов JPEG в несколько массивов. Если набор данных был загружен один раз, в следующие разы время загрузки составляет менее 200 мс с использованием запомненной версии, запомненной на диске в ~/scikit_learn_data/lfw_home/ папке с использованием joblib . Первый загрузчик используется для задачи идентификации лиц: задачи классификации нескольких классов (следовательно, контролируемое обучение): >>> from sklearn.datasets import fetch_lfw_people >>> lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4) >>> for name in lfw_people.target_names: . print(name) . Ariel Sharon Colin Powell Donald Rumsfeld George W Bush Gerhard Schroeder Hugo Chavez Tony Blair Срез по умолчанию представляет собой прямоугольную форму вокруг лица, удаляя большую часть фона: >>> lfw_people.data.dtype dtype('float32') >>> lfw_people.data.shape (1288, 1850) >>> lfw_people.images.shape (1288, 50, 37) Каждому из 1140 лиц назначается отдельный идентификатор человека в target массиве: >>> lfw_people.target.shape (1288,) >>> list(lfw_people.target[:10]) [5, 6, 3, 1, 0, 1, 3, 4, 3, 0] Второй загрузчик обычно используется для задачи проверки лица: каждый образец представляет собой пару из двух изображений, принадлежащих или не принадлежащих одному и тому же человеку: >>> from sklearn.datasets import fetch_lfw_pairs >>> lfw_pairs_train = fetch_lfw_pairs(subset='train') >>> list(lfw_pairs_train.target_names) ['Different persons', 'Same person'] >>> lfw_pairs_train.pairs.shape (2200, 2, 62, 47) >>> lfw_pairs_train.data.shape (2200, 5828) >>> lfw_pairs_train.target.shape (2200,) Как для функции, так sklearn.datasets.fetch_lfw_people и для sklearn.datasets.fetch_lfw_pairs функции можно получить дополнительное измерение с цветовыми каналами RGB, передавая color=True , в этом случае форма будет иметь вид (2200, 2, 62, 47, 3) Эти sklearn.datasets.fetch_lfw_pairs
наборы данные подразделяются на 3 подмножество: разработка train набор, разработка test набор и оценка 10_folds набор предназначен для вычисления метрик производительности с использованием 10-складывает перекрестную схему проверки. 7.2.3.2. Примеры Пример распознавания лиц с использованием собственных лиц и SVM - Немного теории
- Classifier Building in Scikit-learn
- Naive Bayes Classifier with Synthetic Dataset
- Generating the Dataset
- Train Test Split
- Model Building and Training
- Model Evaluation
- Naive Bayes Classifier with Loan Dataset
- Загрузка данных
- Исследование данных
- Обработка данных
- Построение и обучение моделей
- Оценка модели
- Категориальный Наивный Байес
- Как работает наивный байесовский классификатор?
- Первый подход (в случае одной функции)
- Набор данных RCV1
- Набор данных California Housing
- Гауссовский наивный байесовский
- Advantages
- Мультиномиальных Наивный Байес
- Disadvantages
- What is Naive Bayes Classifier?
- Дополнение наивного Байеса
- Задача нулевой вероятности
- Набор текстовых данных 20 групп новостей
- 7.2.2.1. Использование
- 7.2.2.2. Преобразование текста в векторы
- 7.2.2.3. Фильтрация текста для более реалистичного обучения
- Набор данных Kddcup 99
- Набор данных лица Olivetti
- Подгонка нестандартной наивной байесовской модели
- Виды лесного покрова
- Classification Workflow
- Бернулли Наивный Байес
- Тесты
- Помеченные лица в наборе данных по распознаванию лиц Wild
- 7.2.3.1. Использование
- 7.2.3.2. Примеры
Код
Ниже — код на питоне. Содержит всего две функции: одна для тренировки (подсчета параметров формулы), другая для классификации (непосредственный расчет формулы).
from __future__ import division
from collections import defaultdict
from math import log
def train(samples):
classes, freq = defaultdict(lambda:0), defaultdict(lambda:0)
for feats, label in samples:
classes[label] += 1 # count classes frequencies
for feat in feats:
freq[label, feat] += 1 # count features frequencies
for label, feat in freq: # normalize features frequencies
freq[label, feat] /= classes[label]
for c in classes: # normalize classes frequencies
classes[c] /= len(samples)
return classes, freq # return P(C) and P(O|C)
def classify(classifier, feats):
classes, prob = classifier
return min(classes.keys(), # calculate argmin(-log(C|O))
key = lambda cl: -log(classes[cl]) + \
sum(-log(prob.get((cl,feat), 10**(-7))) for feat in feats))
В функции classify
происходит поиск наиболее вероятного класса. Единственное отличие от формулы
в том, что я заменяю произведение вероятностей на сумму логарифмов, взятых с отрицательным знаком, и вычисляю не argmax, а argmin. Переход к логарифмам — распространненный прием чтобы избежать слишком маленьких чисел, которые могли бы получится при произведении вероятностей.
Число 10(^-7), которое подставляется в логарифм, это способ избежать нуля в аргументе логарифма (т.к. он будет иначе он будет неопределен).
Чтобы натренировать классификатор возьмем размеченный список мужских и женских имен и воспользуемся этим кодом:
def get_features(sample): return (sample[-1],) # get last letter
samples = (line.decode('utf-8').split() for line in open('names.txt'))
features = [(get_features(feat), label) for feat, label in samples]
classifier = train(features)
print 'gender: ', classify(classifier, get_features(u'Аглафья'))
В качестве фич я выбрал последнюю букву имени (см функцию get_features). Работает неплохо, но для рабочего варианта лучше использовать схему посложнее. К примеру, выбрать первую букву имени и две последних. К примеру, вот так:
def get_features(sample): return (
'll: %s' % sample[-1], # get last letter
'fl: %s' % sample[0], # get first letter
'sl: %s' % sample[1], # get second letter
)
Алгоритм можно использовать для произвольного числа классов. К примеру, можно попробовать построить классификатор текстов по эмоциональной окраске.
Немного теории
Пусть у нас есть строка текста O. Кроме того, имеются классы С, к одному из которых мы должны отнести строку. Нам необходимо найти такой класс с, при котором его вероятность для данной строки была бы максимальна. Математически это записывается так:

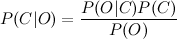
Так как мы ищем максимум от функции, то знаменатель нас не интересует (он в данном случае константа). Кроме того, нужно взглянуть на строку O. Обычно, нет смысла работать со всей строкой. Намного эффективней выделить из нее определенные признаки (features). Таким образом формула примет вид:

Знаменатель нас не интересует. Числитель же можно переписать так.

Но это опять сложно. Здесь включаем «наивное» предположение о том, что переменные O зависят только от класса C, и не зависят друг от друга. Это сильно упрощение, но зачастую это работает. Числитель примет вид:

Финальная формула примет вид:
Classifier Building in Scikit-learn
Naive Bayes Classifier with Synthetic Dataset
In the first example, we will generate synthetic data using scikit-learn and train and evaluate the Gaussian Naive Bayes algorithm.
Generating the Dataset
Scikit-learn provides us with a machine learning ecosystem so that you can generate the dataset and evaluate various machine learning algorithms.
In our case, we are creating a dataset with six features, three classes, and 800 samples using the `make_classification` function.
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=800,
n_informative=2,
random_state=1,
n_clusters_per_class=1,
)
We will use matplotlib.pyplot’s `scatter` function to visualize the dataset.
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, marker="*");
As we can observe, there are three types of target labels, and we will be training a multiclass classification model.
Train Test Split
Before we start the training process, we need to split the dataset into training and testing for model evaluation.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)
Model Building and Training
Build a generic Gaussian Naive Bayes and train it on a training dataset. After that, feed a random test sample to the model to get a predicted value.
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])
Both actual and predicted values are the same.
Actual Value: 0
Predicted Value: 0
Model Evaluation
We will not evolve the model on an unseen test dataset. First, we will predict the values for the test dataset and use them to calculate accuracy and F1 score.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)
Our model has performed fairly well with default hyperparameters.
Accuracy: 0.8484848484848485
F1 Score: 0.8491119695890328
To visualize the Confusion matrix, we will use `confusion_matrix` to calculate the true positives and true negatives and `ConfusionMatrixDisplay` to display the confusion matrix with the labels.
labels = [0,1,2]
cm = confusion_matrix(y_test, y_pred, labels=labels)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();
Our model has performed quite well, and we can improve model performance by scaling, preprocessing cross-validations, and hyperparameter optimization.
Naive Bayes Classifier with Loan Dataset
Let’s train the Naive Bayes Classifier on the real dataset. Мы будем повторять большинство задач, за исключением предварительной обработки и исследования данных.
Загрузка данных
В этом примере мы будем загружать Данные о кредите
из DataCamp Workspace с использованием pandas ‘ read_csv
`функция.
import pandas as pd
df = pd.read_csv('loan_data.csv')
df.head()
Исследование данных
Чтобы лучше понять набор данных, мы будем использовать `.info()`.
- Набор данных состоит из 14 столбцов и 9578 строк.
- Помимо «назначения», столбцы могут быть либо числами с плавающей запятой, либо целыми числами.
- Наш целевой столбец — «не полностью оплачено».
df.info()
RangeIndex: 9578 entries, 0 to 9577
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit.policy 9578 non-null int64
1 purpose 9578 non-null object
2 int.rate 9578 non-null float64
3 installment 9578 non-null float64
4 log.annual.inc 9578 non-null float64
5 dti 9578 non-null float64
6 fico 9578 non-null int64
7 days.with.cr.line 9578 non-null float64
8 revol.bal 9578 non-null int64
9 revol.util 9578 non-null float64
10 inq.last.6mths 9578 non-null int64
11 delinq.2yrs 9578 non-null int64
12 pub.rec 9578 non-null int64
13 not.fully.paid 9578 non-null int64
dtypes: float64, int64, object
memory usage: 1.0+ MB
В этом примере мы будем разрабатывать модель для прогнозирования клиентов, которые не полностью выплатили кредит. Давайте рассмотрим столбец «Цель и цель», используя графический график Seaborn.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=df,x='purpose',hue='not.fully.paid')
plt.xticks(rotation=45, ha='right');
Наш набор данных представляет собой дисбаланс, который повлияет на производительность модели. Вы можете проверить Повторная выборка несбалансированного набора данных
руководство, позволяющее получить практический опыт работы с несбалансированными наборами данных.
Обработка данных
Теперь мы преобразуем столбец «цель» из категориального в целочисленный, используя функцию pandas `get_dummies`.
pre_df = pd.get_dummies(df,columns=['purpose'],drop_first=True)
pre_df.head()
После этого мы определим переменные функции (X) и цели (y) и разделим набор данных на обучающий и проверочный наборы.
from sklearn.model_selection import train_test_split
X = pre_df.drop('not.fully.paid', axis=1)
y = pre_df['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=125
)
Построение и обучение моделей
Построение и обучение модели довольно просты. Мы будем обучать модель на наборе обучающих данных, используя гиперпараметры по умолчанию.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train);
Оценка модели
Мы будем использовать точность и показатель f1 для определения производительности модели, и похоже, что гауссов наивный алгоритм Байеса показал себя достаточно хорошо.
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
ConfusionMatrixDisplay,
f1_score,
classification_report,
)
y_pred = model.predict(X_test)
accuray = accuracy_score(y_pred, y_test)
f1 = f1_score(y_pred, y_test, average="weighted")
print("Accuracy:", accuray)
print("F1 Score:", f1)
Accuracy: 0.8206263840556786
F1 Score: 0.8686606980013266
Из-за несбалансированного характера данных мы видим, что матрица путаницы рассказывает другую историю. Что касается цели меньшинства: «не полностью оплачено», мы неправильно маркируем ее.
labels = ["Fully Paid", "Not fully Paid"]
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot();
Если вы столкнулись с проблемами во время обучения или оценки модели, вы можете ознакомиться с Учебным пособием по наивной байесовской классификации с помощью Scikit-learn Workspace
. Он поставляется с набором данных, исходным кодом и выходными данными.
Категориальный Наивный Байес
CategoricalNB
реализовать категориально наивный алгоритм Байеса для категориально распределенных данных. Предполагается, что каждая функция, описывающая индексом $i$, имеет свое категориальное значение.
Как работает наивный байесовский классификатор?
Давайте разберемся с работой Наивного Байеса на примере. Приведен пример погодных условий и занятий спортом. Вам необходимо рассчитать вероятность занятий спортом. Теперь вам нужно определить, будут ли игроки играть или нет, в зависимости от погодных условий.
Первый подход (в случае одной функции)
- Шаг 1
: вычислить априорную вероятность для заданных меток классов - Шаг 2
: Найти вероятность правдоподобия для каждого атрибута для каждого класса - Шаг 3
: поместите эти значения в формулу Байеса и рассчитайте апостериорную вероятность. - Шаг 4
: Посмотрите, какой класс имеет более высокую вероятность, учитывая, что входные данные принадлежат к классу с более высокой вероятностью.
.
.
Для упрощения расчета априорной и апостериорной вероятности вы можете использовать две таблицы: таблицу частот и таблицу правдоподобия. Обе эти таблицы помогут вам рассчитать априорную и апостериорную вероятность. Таблица частот содержит появление меток для всех объектов. Есть две таблицы вероятности. Таблица правдоподобия 1 показывает априорные вероятности меток, а таблица правдоподобия 2 показывает апостериорную вероятность.
Теперь предположим, что вы хотите вычислить вероятность игры в пасмурную погоду.
Вероятность игры:
Вычислить априорные вероятности:
P(пасмурно) = 4/14 = 0,29
P(Да)= 9/14 = 0,64
Вычислить апостериорные вероятности:
Поместите априорную и апостериорную вероятности в уравнение
Аналогично можно посчитать вероятность неигры:
Вероятность не играть:
Вычислить априорные вероятности:
P(пасмурно) = 4/14 = 0,29
P(Нет)= 5/14 = 0,36
Вычислить апостериорные вероятности:
Поместите априорную и апостериорную вероятности в уравнение
Вероятность класса «Да» выше. Таким образом, здесь вы можете определить, будет ли погода пасмурной, чем игроки будут заниматься этим видом спорта.
<h3 id="second-approach-(in-case-of-multiple-features)- Второй подход (в случае нескольких функций)
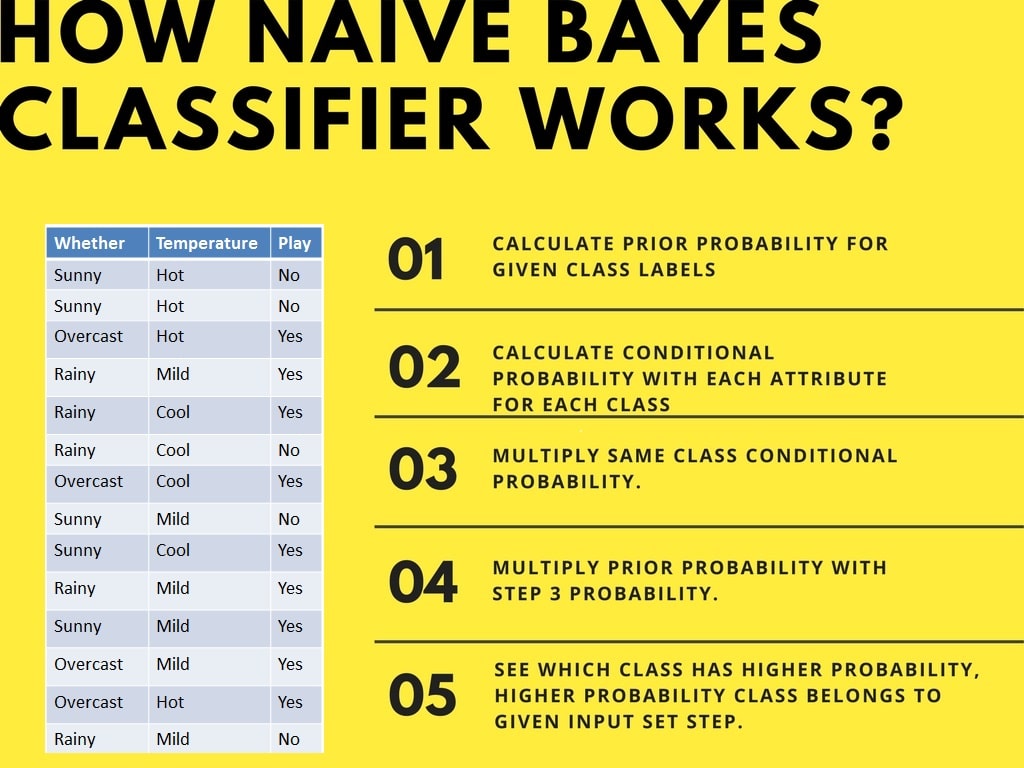
Теперь предположим, что вы хотите вычислить вероятность игры в пасмурную погоду и умеренную температуру.
Вероятность игры:
Вычислите априорные вероятности: P(Да)= 9/14 = 0,64
Аналогично можно посчитать вероятность неигры:
Вероятность не играть:
Вычислите априорные вероятности: P(No)= 5/14 = 0,36
Вероятность класса «Да» выше. Таким образом, здесь можно сказать, что если погода пасмурная, то игроки будут заниматься этим видом спорта.
Набор данных RCV1
Reuters Corpus Volume I (RCV1) — это архив из более чем 800 000 вручную категоризированных новостных лент, предоставленных Reuters, Ltd. для исследовательских целей. Набор данных подробно описан в 1
Характеристики набора данных:
sklearn.datasets.fetch_rcv1
загрузить эту версию: RCV1-v2, упомянуть, полные наборы, темы с несколькими ярлыками:
>>> из sklearn.datasets import fetch_rcv1 >>> rcv1 = fetch_rcv1()
Он возвращает объект, словарь, соблюдая атрибуты:
data
: Матрица функций — это типовая разреженная матрица CSR с 804414 выборками и 47236 функциями. Ненулевые значения содержат нормализованные по косинусу логарифмические записи TF-IDF. Предлагается почти хронологическое разделение на 1
: первые 23149 выборок являются обучающей выборкой. Последние 781265 образцов — это набор для тестирования. Это следует указать в хронологическом порядке LYRL2004. В массиве 0,16% ненулевых результатов:
>>> rcv1.data.shape (804414, 47236)
target
: Целевые значения хранения в разреженной матрице CSR с 804414 выборками и 103 категориями. Каждый образец имеет значение 1 в своих категориях и 0 в других. В массиве 3,15% ненулевых результатов:
>>> rcv1.target.shape (804414, 103)
sample_id
: Каждый образец можно идентифицировать по его идентификатору в отдельных частях (с пробелами) от 2286 до 810596:
>>> rcv1.sample_id[:3] массив([2286, 2287, 2288], dtype=uint32)
target_names
: Целевые значения — это тема каждого образца. Каждый образец относится как минимум к одной теме, но не более чем к 17 темам. Всего 103 темы, техника из которых представлена строкой. Часто их корпус состоит из пяти порядков, от 5 для GMIL до 381327 для CCAT:
>>> rcv1.target_names[:3].tolist() ['E11', 'ECAT', 'M11']
При необходимости набор данных будет загружен с закрытая страница rcv1
. Сжатый размер составляет около 656 МБ.
1 Льюис, Д. Д., Янг, Ю., Роуз, Т. Г., и Ли, Ф. (2004). RCV1: новая коллекция тестов для исследования категоризации текста. Журнал исследований в области машинного обучения, 5, 361–397.
Набор данных California Housing
Характеристики набора данных:
Количество экземпляров
20640
Количество атрибутов
8 числовых, прогнозных атрибутов и цель
Информация об атрибутах
:
- Медианный доход MedInc в блоке
- HouseAge средний возраст дома в блоке
- Среднее количество комнат в AveRooms
- Среднее количество спален AveBedrms
- Население блока населения
- Средняя заполняемость дома AveOccup
- Широта дома блок широта
- Долгота долгота блока дома
Отсутствующие значения атрибутов
Нет
Этот набор данных был получен из репозитория StatLib. http://lib.stat.cmu.edu/datasets/
Целевая переменная — это средняя стоимость дома для округов Калифорнии.
Этот набор данных был получен из переписи населения США 1990 года с использованием одной строки на каждую блочную группу переписи. Блочная группа — это наименьшая географическая единица, для которой Бюро переписи США публикует выборочные данные (блочная группа обычно насчитывает от 600 до 3000 человек).
- Пейс, Р. Келли и Рональд Барри, Разреженные пространственные авторегрессии, статистика и вероятностные письма, 33 (1997) 291-297.
Гауссовский наивный байесовский
Параметры $\sigma_y
Параметры $\sigma_y$ а также $\mu_y$ оцениваются с использованием максимального правдоподобия.
nbsp;а также $\mu_y
Параметры $\sigma_y$ а также $\mu_y$ оцениваются с использованием максимального правдоподобия.
nbsp;оцениваются с использованием максимального правдоподобия.
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.naive_bayes import GaussianNB
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
>>> gnb = GaussianNB()
>>> y_pred = gnb.fit(X_train, y_train).predict(X_test)
>>> print("Number of mislabeled points out of a total %d points : %d"
. % (X_test.shape[0], (y_test != y_pred).sum()))
Number of mislabeled points out of a total 75 points : 4 Advantages
- It is not only a simple approach but also a fast and accurate method for prediction.
- Naive Bayes has a very low computation cost.
- It can efficiently work on a large dataset.
- It performs well in case of discrete response variable compared to the continuous variable.
- It can be used with multiple class prediction problems.
- It also performs well in the case of text analytics problems.
- When the assumption of independence holds, a Naive Bayes classifier performs better compared to other models like logistic regression.
Мультиномиальных Наивный Байес
Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1
Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1$ называется сглаживанием Лапласа, а $\alpha < 1$ называется сглаживанием Лидстоуна.
nbsp;называется сглаживанием Лапласа, а $\alpha < 1
Сглаживающие приоры $\alpha \ge 0$ учитывает особенности, отсутствующие в обучающих выборках, и предотвращает нулевые вероятности в дальнейших вычислениях. Параметр $\alpha = 1$ называется сглаживанием Лапласа, а $\alpha < 1$ называется сглаживанием Лидстоуна.
nbsp;называется сглаживанием Лидстоуна.
Disadvantages
- The assumption of independent features. In practice, it is almost impossible that model will get a set of predictors which are entirely independent.
- If there is no training tuple of a particular class, this causes zero posterior probability. In this case, the model is unable to make predictions. This problem is known as Zero Probability/Frequency Problem.
What is Naive Bayes Classifier?
Naive Bayes is a statistical classification technique based on Bayes Theorem. It is one of the simplest supervised learning algorithms. Naive Bayes classifier is the fast, accurate and reliable algorithm. Наивные байесовские классификаторы обладают высокой точностью и скоростью работы с большими наборами данных.
Наивный байесовский классификатор предполагает, что влияние определенного признака в классе не зависит от других признаков. Например, кандидат на получение кредита является желательным или нет в зависимости от его / ее дохода, предыдущей кредитной истории и истории транзакций, возраста и местоположения. Даже если эти функции взаимозависимы, они все равно считаются независимыми. Это предположение упрощает вычисления и поэтому считается наивным. Это предположение называется условной независимостью класса.
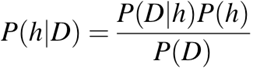
- P(h): вероятность того, что гипотеза h верна (независимо от данных). Это известно как априорная вероятность h.
- P(D): вероятность данных (независимо от гипотезы). Это известно как априорная вероятность.
- P(h|D): вероятность гипотезы h с учетом данных D. Это известно как апостериорная вероятность.
- P(D|h): вероятность данных d при условии, что гипотеза h верна. Это известно как апостериорная вероятность.
Дополнение наивного Байеса
т. е. документ, отнесенный к классу, который является самым плохим дополнением.
Задача нулевой вероятности
Предположим, что в наборе данных нет кортежа для рискованного кредита; в этом сценарии апостериорная вероятность будет равна нулю, и модель не сможет сделать прогноз. Эта проблема известна как нулевая вероятность, поскольку появление определенного класса равно нулю.
Решением такой проблемы является поправка Лапласа или преобразование Лапласа. Коррекция Лапласа является одним из методов сглаживания. Здесь вы можете предположить, что набор данных достаточно велик, и добавление одной строки каждого класса не повлияет на оценочную вероятность. Это позволит решить проблему нулевых значений вероятности.
Например: предположим, что для класса кредита рискованного в базе данных имеется 1000 обучающих кортежей. В этой базе данных столбец дохода содержит 0 кортежей для низкого дохода, 990 кортежей для среднего дохода и 10 кортежей для высокого дохода. Вероятности этих событий без учета поправки Лапласа равны 0, 0,990 (из 990/1000) и 0,010 (из 10/1000)
.
Теперь примените поправку Лапласа к данному набору данных. Давайте добавим еще один кортеж для каждой пары доход-стоимость. Вероятности этих событий:
Набор текстовых данных 20 групп новостей
Набор данных из 20 групп новостей включает около 18000 сообщений групп новостей по 20 темам, разделенных на два подмножества: один для обучения (или разработки), другой для тестирования (или для оценки производительности). Разделение между поездом и набором тестов основано на сообщениях, отправленных до и после даты назначения.
Этот модуль содержит два загрузчика. Первый,, sklearn.datasets.fetch_20newsgroups
вернуть список необработанных текстов, которые могут быть переданы экстракторам текстовых признаков, например, CountVectorizer
с пользовательскими параметрами для извлечения векторов признаков. Второй, sklearn.datasets.fetch_20newsgroups_vectorized
верните готовые к использованию функции, т.е. е. нет необходимости использовать средства извлечения признаков.
Характеристики набора данных:
7.2.2.1. Использование
Эта sklearn.datasets.fetch_20newsgroups функция представляет собой функцию выборки / кэширования данных, которая загружает архив данных с оригинального веб-сайта 20 групп новостей
, извлекает содержимое архива в ~/scikit_learn_data/20news_home
папку и вызывает sklearn.datasets.load_files
либо папку обучающего, либо тестового набора, либо оба из них:
>>> from sklearn.datasets import fetch_20newsgroups >>> newsgroups_train = fetch_20newsgroups(subset='train') >>> from pprint import pprint >>> pprint(list(newsgroups_train.target_names)) ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Ложь реальных данных в filenames
и target
атрибутах. Целевой атрибут — это целочисленный индекс категории:
>>> newsgroups_train.filenames.shape (11314,) >>> newsgroups_train.target.shape (11314,) >>> newsgroups_train.target[:10] array([ 7, 4, 4, 1, 14, 16, 13, 3, 2, 4])
Можно загрузить только подвыбор категорий, передав список категорий для загрузки в sklearn.datasets.fetch_20newsgroups
функцию:
>>> cats = ['alt.atheism', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', categories=cats) >>> list(newsgroups_train.target_names) ['alt.atheism', 'sci.space'] >>> newsgroups_train.filenames.shape (1073,) >>> newsgroups_train.target.shape (1073,) >>> newsgroups_train.target[:10] array([0, 1, 1, 1, 0, 1, 1, 0, 0, 0])
7.2.2.2. Преобразование текста в векторы
Чтобы наполнить прогнозные модели или модели кластеризации текстовыми данными, сначала необходимо преобразовать текст в векторы числовых значений, пригодные для статистического анализа. Это может быть достигнуто с помощью утилит, sklearn.feature_extraction.text
как показано в следующем примере, которые извлекают векторы TF-IDF
токенов unigram из подмножества 20news:
>>> from sklearn.feature_extraction.text import TfidfVectorizer >>> categories = ['alt.atheism', 'talk.religion.misc', . 'comp.graphics', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', . categories=categories) >>> vectorizer = TfidfVectorizer() >>> vectors = vectorizer.fit_transform(newsgroups_train.data) >>> vectors.shape (2034, 34118)
Извлеченные векторы TF-IDF очень разрежены, в среднем 159 ненулевых компонентов по выборке в более чем 30000-мерном пространстве (менее 0,5% ненулевых функций):
>>> vectors.nnz / float(vectors.shape[0]) 159.01327.
sklearn.datasets.fetch_20newsgroups_vectorized
— это функция, которая возвращает готовые к использованию функции подсчета токенов вместо имен файлов.
7.2.2.3. Фильтрация текста для более реалистичного обучения
Классификатору легко приспособиться к определенным вещам, которые появляются в данных 20 групп новостей, например, к заголовкам групп новостей. Многие классификаторы достигают очень высоких оценок F, но их результаты не могут быть обобщены на другие документы, выходящие за рамки этого временного окна.
Например, давайте посмотрим на результаты полиномиального наивного байесовского классификатора, который быстро обучается и дает приличный F-балл:
>>> from sklearn.naive_bayes import MultinomialNB >>> from sklearn import metrics >>> newsgroups_test = fetch_20newsgroups(subset='test', . categories=categories) >>> vectors_test = vectorizer.transform(newsgroups_test.data) >>> clf = MultinomialNB(alpha=.01) >>> clf.fit(vectors, newsgroups_train.target) MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) >>> pred = clf.predict(vectors_test) >>> metrics.f1_score(newsgroups_test.target, pred, average='macro') 0.88213.
(В примере « Классификация текстовых документов с использованием разреженных функций» происходит
перемешивание обучающих и тестовых данных вместо сегментации по времени, и в этом случае полиномиальный Наивный Байес получает гораздо более высокий F-балл 0,88. Вы еще не подозреваете, что происходит внутри этого? классификатор?)
Давайте посмотрим, какие функции наиболее информативны:
>>> import numpy as np
>>> def show_top10(classifier, vectorizer, categories):
. feature_names = np.asarray(vectorizer.get_feature_names())
. for i, category in enumerate(categories):
. top10 = np.argsort(classifier.coef_[i])[-10:]
. print("%s: %s" % (category, " ".join(feature_names[top10])))
.
>>> show_top10(clf, vectorizer, newsgroups_train.target_names)
alt.atheism: edu it and in you that is of to the
comp.graphics: edu in graphics it is for and of to the
sci.space: edu it that is in and space to of the
talk.religion.misc: not it you in is that and to of the Теперь вы можете увидеть многие вещи, которым эти функции лучше всего подходят:
- Практически каждая группа отличается тем, что заголовки, такие как
NNTP-Posting-Host:
и,Distribution:
появляются чаще или реже. - Еще одна важная особенность связана с тем, является ли отправитель аффилированным лицом к университету, о чем свидетельствуют заголовки или подпись.
- Слово «статья» — важная особенность, основанная на том, как часто люди цитируют предыдущие сообщения, например: «В статье [идентификатор статьи], [имя] написал:»
- Другие функции соответствуют именам и адресам электронной почты конкретных людей, которые публиковали сообщения в то время.
С таким обилием подсказок, которые различают группы новостей, классификаторам практически не нужно определять темы по тексту, и все они работают на одном высоком уровне.
По этой причине функции, загружающие данные 20 групп новостей, предоставляют параметр с именем remove
, сообщающий ему, какие виды информации нужно удалить из каждого файла. remove
должен быть кортежем, содержащим любое подмножество из (‘headers’, ‘footers’, ‘quotes’), с указанием удалить заголовки, блоки подписи и блоки цитат соответственно.
>>> newsgroups_test = fetch_20newsgroups(subset='test',
. remove=('headers', 'footers', 'quotes'),
. categories=categories)
>>> vectors_test = vectorizer.transform(newsgroups_test.data)
>>> pred = clf.predict(vectors_test)
>>> metrics.f1_score(pred, newsgroups_test.target, average='macro')
0.77310. Этот классификатор потерял большую часть своего F-балла только потому, что мы удалили метаданные, которые не имеют ничего общего с классификацией тем. Он потеряет еще больше, если мы также удалим эти метаданные из данных обучения:
>>> newsgroups_train = fetch_20newsgroups(subset='train',
. remove=('headers', 'footers', 'quotes'),
. categories=categories)
>>> vectors = vectorizer.fit_transform(newsgroups_train.data)
>>> clf = MultinomialNB(alpha=.01)
>>> clf.fit(vectors, newsgroups_train.target)
MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) >>> vectors_test = vectorizer.transform(newsgroups_test.data) >>> pred = clf.predict(vectors_test) >>> metrics.f1_score(newsgroups_test.target, pred, average='macro') 0.76995.
Некоторые другие классификаторы лучше справляются с этой более сложной версией задачи. Попробуйте запустить пример конвейера для извлечения и оценки текстовых функций
с --filter
возможностью сравнения результатов и без нее.
При оценке текстовых классификаторов для данных 20 групп новостей следует удалить метаданные, относящиеся к группам новостей. В scikit-learn вы можете сделать это, установив remove=(‘headers’, ‘footers’, ‘quotes’). Оценка F будет ниже, потому что это более реалистично.
Набор данных Kddcup 99
Набор данных KDD Cup ’99 был создан путем обработки частей tcpdump из набора данных DARPA Intrusion Detection System (IDS) 1998 года, созданного MIT Lincoln Lab 2
Искусственные данные (описанные на домашней странице набора данных
) были сгенерированы с использованием закрытой сети и вручную введенных атак, чтобы произвести большое количество различных типов атак с нормальной активностью в фоновом режиме. Поскольку первоначальная цель состояла в том, чтобы создать большой обучающий набор для алгоритмов контролируемого обучения, существует большая часть (80,1%) аномальных данных, которые нереальны в реальном мире и не подходят для неконтролируемого обнаружения аномалий, направленного на обнаружение «аномальных» данных. то есть:
- качественно отличается от нормальных данных
- в значительном меньшинстве среди наблюдений.
Таким образом, мы преобразуем набор данных KDD в два разных набора данных: SA и SF.
- SA получается простым выбором всех нормальных данных, а небольшая часть аномальных данных дает долю аномалий в 1%.
- SF получается, как в пункте 3
, путем простого сбора данных, атрибут logged_in положительный, таким образом сосредоточиваясь на атаке вторжения, что дает долю атаки 0,3%. - http и smtp — это два подмножества SF, соответствующие третьей функции, равной http (соответственно, smtp).
Общая структура KDD:
sklearn.datasets.fetch_kddcup99
загрузит набор данных kddcup99; он возвращает объект, подобный словарю, с матрицей признаков в data
члене и целевыми значениями в target
. Необязательный аргумент «as_frame» преобразует data
в pandas DataFrame и target
в pandas Series. При необходимости набор данных будет загружен из Интернета.
- Анализ и результаты оценки обнаружения вторжений в автономном режиме DARPA 1999 г., Ричард Липпманн, Джошуа В. Хейнс, Дэвид Дж. Фрид, Джонатан Корба, Кумар Дас.
- К. Яманиши, Ж.-И. Такеучи, Дж. Уильямс и П. Милн. Онлайн-обнаружение неконтролируемых выбросов с использованием конечных смесей с дисконтирующими алгоритмами обучения. В материалах шестой международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных, страницы 320-324. ACM Press, 2000.
Набор данных лица Olivetti
Этот набор данных содержит набор изображений лиц
, снятых в период с апреля 1992 г. по апрель 1994 г. в AT&T Laboratories Cambridge. sklearn.datasets.fetch_olivetti_faces
Функция выборки / кэширования функцию , которая загружает архив данных от AT & T данные.
Как описано на исходном веб-сайте:
Есть десять различных изображений каждого из 40 различных предметов. Для некоторых объектов изображения были сделаны в разное время, варьируя освещение, выражение лица (открытые / закрытые глаза, улыбающийся / не улыбающийся) и детали лица (очки / без очков). Все изображения были сделаны на темном однородном фоне, когда испытуемые находились в вертикальном фронтальном положении (с допуском на некоторое боковое движение).
Характеристики набора данных:
«Цель» для этой базы данных — это целое число от 0 до 39, указывающее личность изображенного человека; однако, имея всего 10 примеров на класс, этот относительно небольшой набор данных более интересен с точки зрения неконтролируемого или полууправляемого обучения.
Исходный набор данных состоял из 92 x 112, в то время как версия, доступная здесь, состоит из изображений 64×64.
При использовании этих изображений, пожалуйста, отдайте должное AT&T Laboratories Cambridge.
Подгонка нестандартной наивной байесовской модели
Наивные байесовские модели могут использоваться для решения крупномасштабных задач классификации, для которых полный обучающий набор может не поместиться в памяти. Чтобы справиться с этим делом, MultinomialNB
, BernoulliNB
, и GaussianNB
выставить partial_fit
метод , который может быть использован пошагово , как это сделано с другими классификаторами , как показано в вне ядра классификации текстовых документов
Все наивные байесовские классификаторы поддерживают взвешивание выборки.
В отличие от fit
метода, при первом вызове partial_fit
необходимо передать список всех ожидаемых меток классов.
Для обзора доступных стратегий в scikit-learn см. Также документацию по внешнему обучению
Вызов метода partial_fit
наивных моделей Байеса представляет некоторую вычислительную нагрузку. Рекомендуется использовать как можно большие размеры блоков данных, то есть насколько позволяет доступная оперативная память.
Виды лесного покрова
Образцы в этом наборе данных соответствуют участкам леса 30 × 30 м в США, собранным для задачи прогнозирования типа покрытия каждого участка, то есть доминирующих видов деревьев. Существует семь типов обложек, что делает эту задачу мультиклассовой классификацией. Каждый образец имеет 54 функции, описанные на домашней странице набора данных
Некоторые из функций являются логическими индикаторами, а другие — дискретными или непрерывными измерениями.
Характеристики набора данных:
sklearn.datasets.fetch_covtype
загрузит набор данных covertype; он возвращает подобный словарю объект Bunch с матрицей признаков в data
члене и целевыми значениями в target
. Если необязательный аргумент «as_frame» установлен в «True», он возвращает data
и target
в панд кадра данных, и будет являться дополнительным членом , frame
а также. При необходимости набор данных будет загружен из Интернета.
Classification Workflow
Whenever you perform classification, the first step is to understand the problem and identify potential features and label. Features are those characteristics or attributes which affect the results of the label. For example, in the case of a loan distribution, bank managers identify the customer’s occupation, income, age, location, previous loan history, transaction history, and credit score. These characteristics are known as features that help the model classify customers.
The classification has two phases, a learning phase and the evaluation phase. In the learning phase, the classifier trains its model on a given dataset, and in the evaluation phase, it tests the classifier’s performance. Performance is evaluated on the basis of various parameters such as accuracy, error, precision, and recall.

Бернулли Наивный Байес
BernoulliNB
реализует простые байесовские алгоритмы обучения и классификации данных, которые распределяются согласно многомерному распределению Бернулли; то есть может быть несколько функций, но предполагается, что каждая из них является двоичной (Бернулли, логическая) переменной. Следовательно, этот класс требует, чтобы образцы были представлены как векторы признаков с двоичными значениями; если переданы данные любого другого типа, BernoulliNB
экземпляр может преобразовать свой ввод в двоичную форму (в зависимости от binarize
параметра).
Решающее правило для наивного Байеса Бернулли основано на
$P(x_i \mid y) = P(i \mid y) x_i + (1 — P(i \mid y)) (1 — x_i)$
которое отличается от правила полиномиального NB тем, что в нем явно наказывается отсутствие признака $i
которое отличается от правила полиномиального NB тем, что в нем явно наказывается отсутствие признака $i$ это показатель класса y, где полиномиальный вариант просто игнорирует отсутствующую функцию.
nbsp;это показатель класса y, где полиномиальный вариант просто игнорирует отсутствующую функцию.
В случае классификации текста для обучения и использования этого классификатора могут использоваться векторы появления слов (а не векторы подсчета слов). BernoulliNB
может работать лучше с некоторыми наборами данных, особенно с более короткими документами. Если позволяет время, желательно оценить обе модели.
- CD Мэннинг, П. Рагхаван и Х. Шютце (2008). Введение в поиск информации. Издательство Кембриджского университета, стр. 234-265.
- А. МакКаллум и К. Нигам (1998). Сравнение моделей событий для классификации наивного байесовского текста.
Proc. Практикум AAAI / ICML-98 по обучению категоризации текста, стр. 41-48. - В. Метсис, И. Андроутсопулос и Г. Палиурас (2006). Фильтрация спама с помощью наивного байесовского метода — какой наивный байесовский метод?
3-я конф. по электронной почте и защите от спама (CEAS).
Тесты
Я протестировал классификатор на части исходного корпуса с именами. Точность составила 96%. Это не блестящий результат, но для многих задач вполне достаточно.
Помеченные лица в наборе данных по распознаванию лиц Wild
Этот набор данных представляет собой коллекцию изображений известных людей в формате JPEG, собранных через Интернет, все подробности доступны на официальном сайте:
Каждое изображение сосредоточено на одном лице. Типичная задача называется Face Verification: для пары двух изображений двоичный классификатор должен предсказать, принадлежат ли эти два изображения одному и тому же человеку.
Альтернативная задача, «Распознавание лиц» или «Идентификация лиц»: по изображению лица неизвестного человека определить имя человека, обратившись к галерее ранее увиденных изображений идентифицированных лиц.
И проверка лиц, и распознавание лиц — это задачи, которые обычно выполняются на выходе модели, обученной выполнять обнаружение лиц. Самая популярная модель для распознавания лиц называется Виола-Джонса и реализована в библиотеке OpenCV. Лица LFW были извлечены этим детектором лиц с различных онлайн-сайтов.
Характеристики набора данных:
7.2.3.1. Использование
scikit-learn
предоставляет два загрузчика, которые автоматически загружают, кэшируют, анализируют файлы метаданных, декодируют jpeg и преобразуют интересные фрагменты в запомненные массивы numpy. Размер этого набора данных превышает 200 МБ. Первая загрузка обычно занимает более пары минут, чтобы полностью декодировать соответствующую часть файлов JPEG в несколько массивов. Если набор данных был загружен один раз, в следующие разы время загрузки составляет менее 200 мс с использованием запомненной версии, запомненной на диске в ~/scikit_learn_data/lfw_home/
папке с использованием joblib
.
Первый загрузчик используется для задачи идентификации лиц: задачи классификации нескольких классов (следовательно, контролируемое обучение):
>>> from sklearn.datasets import fetch_lfw_people >>> lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4) >>> for name in lfw_people.target_names: . print(name) . Ariel Sharon Colin Powell Donald Rumsfeld George W Bush Gerhard Schroeder Hugo Chavez Tony Blair
Срез по умолчанию представляет собой прямоугольную форму вокруг лица, удаляя большую часть фона:
>>> lfw_people.data.dtype
dtype('float32')
>>> lfw_people.data.shape
(1288, 1850)
>>> lfw_people.images.shape
(1288, 50, 37) Каждому из 1140
лиц назначается отдельный идентификатор человека в target
массиве:
>>> lfw_people.target.shape (1288,) >>> list(lfw_people.target[:10]) [5, 6, 3, 1, 0, 1, 3, 4, 3, 0]
Второй загрузчик обычно используется для задачи проверки лица: каждый образец представляет собой пару из двух изображений, принадлежащих или не принадлежащих одному и тому же человеку:
>>> from sklearn.datasets import fetch_lfw_pairs >>> lfw_pairs_train = fetch_lfw_pairs(subset='train') >>> list(lfw_pairs_train.target_names) ['Different persons', 'Same person'] >>> lfw_pairs_train.pairs.shape (2200, 2, 62, 47) >>> lfw_pairs_train.data.shape (2200, 5828) >>> lfw_pairs_train.target.shape (2200,)
Как для функции, так sklearn.datasets.fetch_lfw_people
и для sklearn.datasets.fetch_lfw_pairs
функции можно получить дополнительное измерение с цветовыми каналами RGB, передавая color=True
, в этом случае форма будет иметь вид (2200, 2, 62, 47, 3)
Эти sklearn.datasets.fetch_lfw_pairs наборы данные подразделяются на 3 подмножество: разработка
train
набор, разработка test
набор и оценка 10_folds
набор предназначен для вычисления метрик производительности с использованием 10-складывает перекрестную схему проверки.
7.2.3.2. Примеры
Пример распознавания лиц с использованием собственных лиц и SVM
